Scraping web pages from the command line with shot-scraper
14th March 2022
I’ve added a powerful new capability to my shot-scraper command line browser automation tool: you can now use it to load a web page in a headless browser, execute JavaScript to extract information and return that information back to the terminal as JSON.
Among other things, this means you can construct Unix pipelines that incorporate a full headless web browser as part of their processing.
It’s also a really neat web scraping tool.
shot-scraper
I introduced shot-scraper last Thursday. It’s a Python utility that wraps Playwright, providing both a command line interface and a YAML-driven configuration flow for automating the process of taking screenshots of web pages.
% pip install shot-scraper
% shot-scraper https://simonwillison.net/ --height 800
Screenshot of 'https://simonwillison.net/' written to 'simonwillison-net.png'
Since Thursday shot-scraper has had a flurry of releases, adding features like PDF exports, the ability to dump the Chromium accessibilty tree and the ability to take screenshots of authenticated web pages. But the most exciting new feature landed today.
Executing JavaScript and returning the result
Release 0.9 takes the tool in a new direction. The following command will execute JavaScript on the page and return the resulting value:
% shot-scraper javascript simonwillison.net document.title
"Simon Willison\u2019s Weblog"
Or you can return a JSON object:
% shot-scraper javascript https://datasette.io/ "({
title: document.title,
tagline: document.querySelector('.tagline').innerText
})"
{
"title": "Datasette: An open source multi-tool for exploring and publishing data",
"tagline": "An open source multi-tool for exploring and publishing data"
}
Or if you want to use functions like setTimeout()—for example, if you want to insert a delay to allow an animation to finish before running the rest of your code—you can return a promise:
% shot-scraper javascript datasette.io "
new Promise(done => setInterval(
() => {
done({
title: document.title,
tagline: document.querySelector('.tagline').innerText
});
}, 1000
));"
Errors that occur in the JavaScript turn into an exit code of 1 returned by the tool—which means you can also use this to execute simple tests in a CI flow. This example will fail a GitHub Actions workflow if the extracted page title is not the expected value:
- name: Test page title
run: |-
shot-scraper javascript datasette.io "
if (document.title != 'Datasette') {
throw 'Wrong title detected';
}"Using this to scrape a web page
The most exciting use case for this new feature is web scraping. I’ll illustrate that with an example.
Posts from my blog occasionally show up on Hacker News—sometimes I spot them, sometimes I don’t.
https://news.ycombinator.com/from?site=simonwillison.net is a Hacker News page showing content from the specified domain. It’s really useful, but it sadly isn’t included in the official Hacker News API.
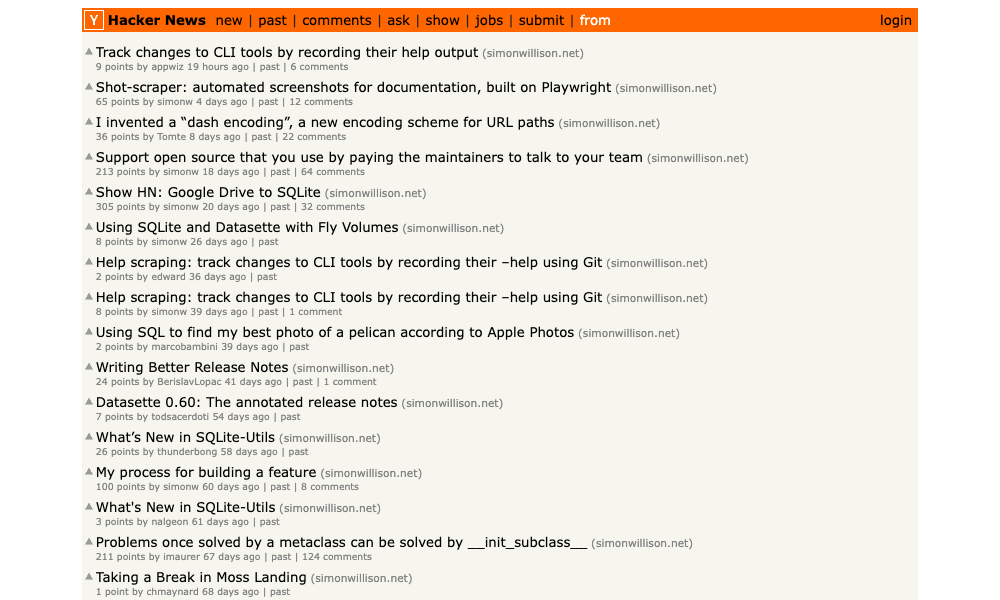
So... let’s write a scraper for it.
I started out running the Firefox developer console against that page, trying to figure out the right JavaScript to extract the data I was interested in. I came up with this:
Array.from(document.querySelectorAll('.athing'), el => {
const title = el.querySelector('.titleline a').innerText;
const points = parseInt(el.nextSibling.querySelector('.score').innerText);
const url = el.querySelector('.titleline a').href;
const dt = el.nextSibling.querySelector('.age').title;
const submitter = el.nextSibling.querySelector('.hnuser').innerText;
const commentsUrl = el.nextSibling.querySelector('.age a').href;
const id = commentsUrl.split('?id=')[1];
// Only posts with comments have a comments link
const commentsLink = Array.from(
el.nextSibling.querySelectorAll('a')
).filter(el => el && el.innerText.includes('comment'))[0];
let numComments = 0;
if (commentsLink) {
numComments = parseInt(commentsLink.innerText.split()[0]);
}
return {id, title, url, dt, points, submitter, commentsUrl, numComments};
})The great thing about modern JavaScript is that everything you could need to write a scraper is already there in the default environment.
I’m using document.querySelectorAll('.itemlist .athing') to loop through each element that matches that selector.
I wrap that with Array.from(...) so I can use the .map() method. Then for each element I can extract out the details that I need.
The resulting array contains 30 items that look like this:
[
{
"id": "30658310",
"title": "Track changes to CLI tools by recording their help output",
"url": "https://simonwillison.net/2022/Feb/2/help-scraping/",
"dt": "2022-03-13T05:36:13",
"submitter": "appwiz",
"commentsUrl": "https://news.ycombinator.com/item?id=30658310",
"numComments": 19
}
]Running it with shot-scraper
Now that I have a recipe for a scraper, I can run it in the terminal like this:
shot-scraper javascript 'https://news.ycombinator.com/from?site=simonwillison.net' "
Array.from(document.querySelectorAll('.athing'), el => {
const title = el.querySelector('.titleline a').innerText;
const points = parseInt(el.nextSibling.querySelector('.score').innerText);
const url = el.querySelector('.titleline a').href;
const dt = el.nextSibling.querySelector('.age').title;
const submitter = el.nextSibling.querySelector('.hnuser').innerText;
const commentsUrl = el.nextSibling.querySelector('.age a').href;
const id = commentsUrl.split('?id=')[1];
// Only posts with comments have a comments link
const commentsLink = Array.from(
el.nextSibling.querySelectorAll('a')
).filter(el => el && el.innerText.includes('comment'))[0];
let numComments = 0;
if (commentsLink) {
numComments = parseInt(commentsLink.innerText.split()[0]);
}
return {id, title, url, dt, points, submitter, commentsUrl, numComments};
})" > simonwillison-net.jsonsimonwillison-net.json is now a JSON file containing the scraped data.
Running the scraper in GitHub Actions
I want to keep track of changes to this data structure over time. My preferred technique for that is something I call Git scraping—the core idea is to keep the data in a Git repository and commit an update any time it updates. This provides a cheap and robust history of changes over time.
Running the scraper in GitHub Actions means I don’t need to administrate my own server to keep this running.
So I built exactly that, in the simonw/scrape-hacker-news-by-domain repository.
The GitHub Actions workflow is in .github/workflows/scrape.yml. It runs the above command once an hour, then pushes a commit back to the repository should the file have any changes since last time it ran.
The commit history of simonwillison-net.json will show me any time a new link from my site appears on Hacker News, or a comment is added.
(Fun GitHub trick: add .atom to the end of that URL to get an Atom feed of those commits.)
The whole scraper, from idea to finished implementation, took less than fifteen minutes to build and deploy.
I can see myself using this technique a lot in the future.
More recent articles
- Experimenting with Starlette 1.0 with Claude skills - 22nd March 2026
- Profiling Hacker News users based on their comments - 21st March 2026
- Thoughts on OpenAI acquiring Astral and uv/ruff/ty - 19th March 2026