5 posts tagged “text-to-video”
2025
Instagram Reel: Veo 3 paid preview. @googlefordevs on Instagram published this reel featuring Christina Warren with prompting tips for the new Veo 3 paid preview (mp4 copy here).

(Christine checked first if I minded them using that concept. I did not!)
2024
Veo 2 (via) Google's text-to-video model, now available via waitlisted preview. I got through the waitlist and tried the same prompt I ran against OpenAI's Sora last week:
A pelican riding a bicycle along a coastal path overlooking a harbor
It generated these four videos:
Here's the larger video.
Sora (via) OpenAI's released their long-threatened Sora text-to-video model this morning, available in most non-European countries to subscribers to ChatGPT Plus ($20/month) or Pro ($200/month).
Here's what I got for the very first test prompt I ran through it:
A pelican riding a bicycle along a coastal path overlooking a harbor
The Pelican inexplicably morphs to cycle in the opposite direction half way through, but I don't see that as a particularly significant issue: Sora is built entirely around the idea of directly manipulating and editing and remixing the clips it generates, so the goal isn't to have it produce usable videos from a single prompt.
Google Research: Lumiere. The latest in text-to-video from Google Research, described as “a text-to-video diffusion model designed for synthesizing videos that portray realistic, diverse and coherent motion”.
Most existing text-to-video models generate keyframes and then use other models to fill in the gaps, which frequently leads to a lack of coherency. Lumiere “generates the full temporal duration of the video at once”, which avoids this problem.
Disappointingly but unsurprisingly the paper doesn’t go into much detail on the training data, beyond stating “We train our T2V model on a dataset containing 30M videos along with their text caption. The videos are 80 frames long at 16 fps (5 seconds)”.
The examples of “stylized generation” which combine a text prompt with a single reference image for style are particularly impressive.
2022
Exploring 10m scraped Shutterstock videos used to train Meta’s Make-A-Video text-to-video model
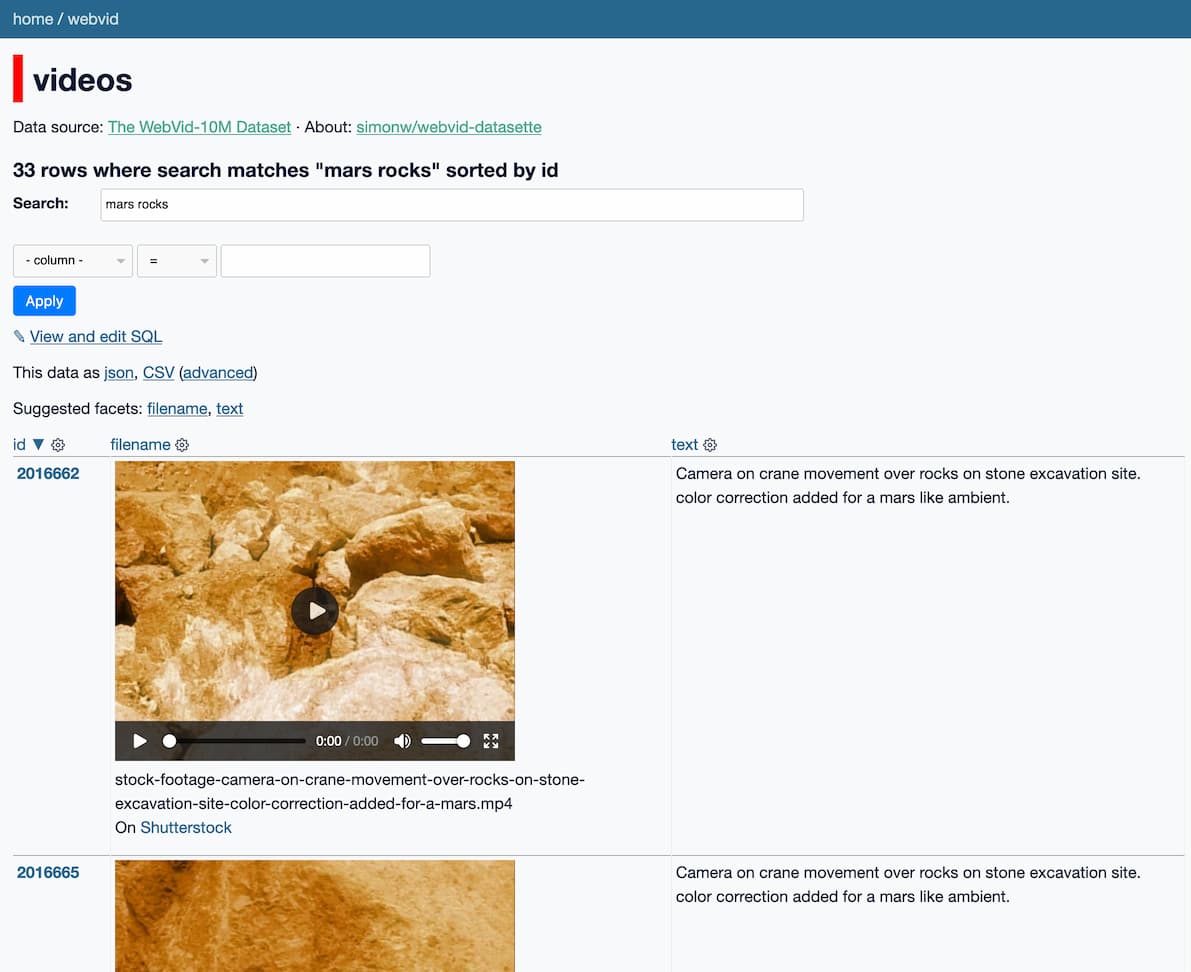
Make-A-Video is a new “state-of-the-art AI system that generates videos from text” from Meta AI. It looks incredible—it really is DALL-E / Stable Diffusion for video. And it appears to have been trained on 10m video preview clips scraped from Shutterstock.
[... 923 words]