13 posts tagged “gpt-2”
2026
Originally in 2019, GPT-2 was trained by OpenAI on 32 TPU v3 chips for 168 hours (7 days), with $8/hour/TPUv3 back then, for a total cost of approx. $43K. It achieves 0.256525 CORE score, which is an ensemble metric introduced in the DCLM paper over 22 evaluations like ARC/MMLU/etc.
As of the last few improvements merged into nanochat (many of them originating in modded-nanogpt repo), I can now reach a higher CORE score in 3.04 hours (~$73) on a single 8XH100 node. This is a 600X cost reduction over 7 years, i.e. the cost to train GPT-2 is falling approximately 2.5X every year.
2024
TextSynth Server (via) I'd missed this: Fabrice Bellard (yes, that Fabrice Bellard) has a project called TextSynth Server which he describes like this:
ts_server is a web server proposing a REST API to large language models. They can be used for example for text completion, question answering, classification, chat, translation, image generation, ...
It has the following characteristics:
- All is included in a single binary. Very few external dependencies (Python is not needed) so installation is easy.
- Supports many Transformer variants (GPT-J, GPT-NeoX, GPT-Neo, OPT, Fairseq GPT, M2M100, CodeGen, GPT2, T5, RWKV, LLAMA, Falcon, MPT, Llama 3.2, Mistral, Mixtral, Qwen2, Phi3, Whisper) and Stable Diffusion.
- [...]
Unlike many of his other notable projects (such as FFmpeg, QEMU, QuickJS) this isn't open source - in fact it's not even source available, you instead can download compiled binaries for Linux or Windows that are available for non-commercial use only.
Commercial terms are available, or you can visit textsynth.com and pre-pay for API credits which can then be used with the hosted REST API there.
This is not a new project: the earliest evidence I could find of it was this July 2019 page in the Internet Archive, which said:
Text Synth is build using the GPT-2 language model released by OpenAI. [...] This implementation is original because instead of using a GPU, it runs using only 4 cores of a Xeon E5-2640 v3 CPU at 2.60GHz. With a single user, it generates 40 words per second. It is programmed in plain C using the LibNC library.
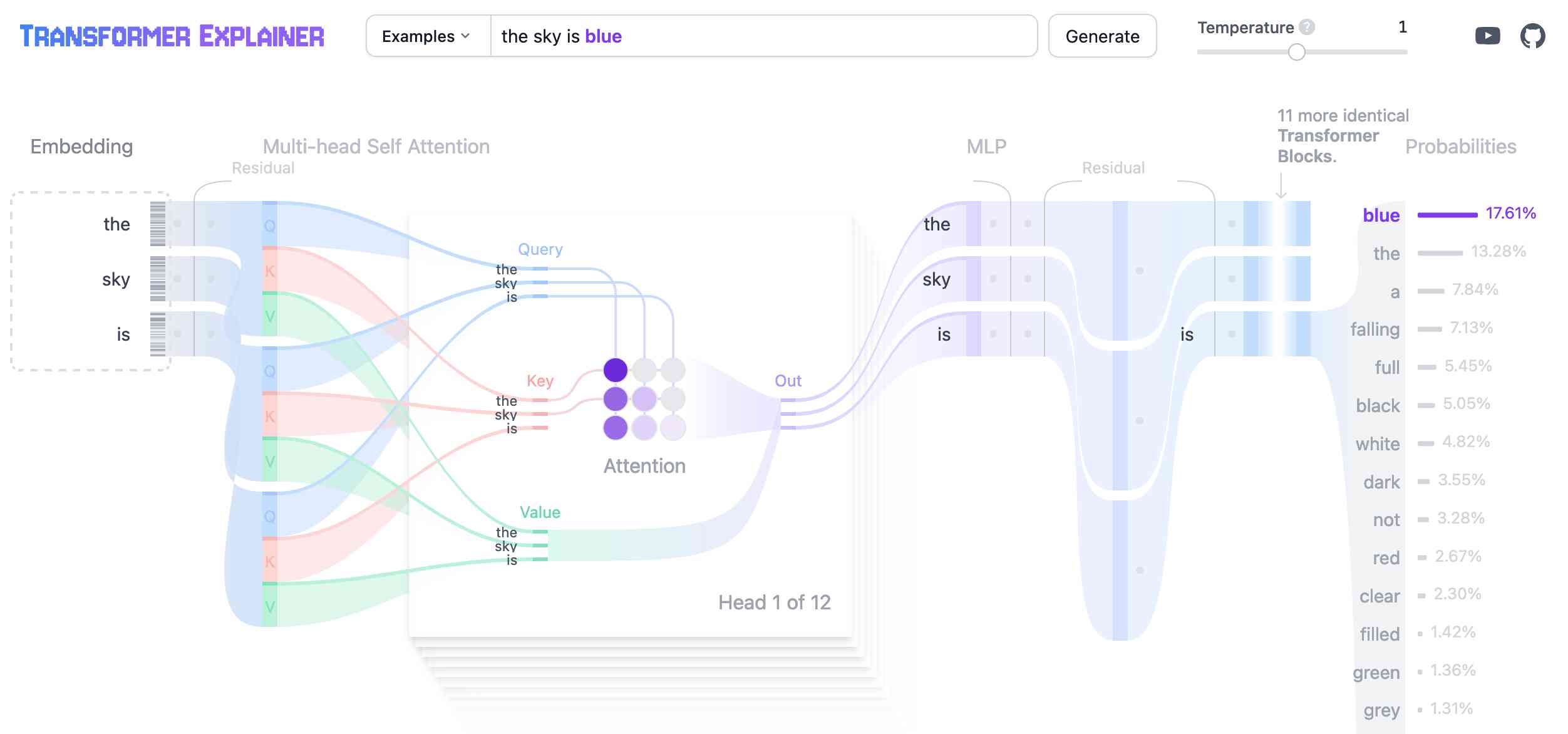
Transformer Explainer. This is a very neat interactive visualization (with accompanying essay and video - scroll down for those) that explains the Transformer architecture for LLMs, using a GPT-2 model running directly in the browser using the ONNX runtime and Andrej Karpathy's nanoGPT project.
The reason current models are so large is because we're still being very wasteful during training - we're asking them to memorize the internet and, remarkably, they do and can e.g. recite SHA hashes of common numbers, or recall really esoteric facts. (Actually LLMs are really good at memorization, qualitatively a lot better than humans, sometimes needing just a single update to remember a lot of detail for a long time). But imagine if you were going to be tested, closed book, on reciting arbitrary passages of the internet given the first few words. This is the standard (pre)training objective for models today. The reason doing better is hard is because demonstrations of thinking are "entangled" with knowledge, in the training data.
Therefore, the models have to first get larger before they can get smaller, because we need their (automated) help to refactor and mold the training data into ideal, synthetic formats.
It's a staircase of improvement - of one model helping to generate the training data for next, until we're left with "perfect training set". When you train GPT-2 on it, it will be a really strong / smart model by today's standards. Maybe the MMLU will be a bit lower because it won't remember all of its chemistry perfectly.
GPT-2 five years later. Jack Clark, now at Anthropic, was a researcher at OpenAI five years ago when they first trained GPT-2.
In this fascinating essay Jack revisits their decision not to release the full model, based on their concerns around potentially harmful ways that technology could be used.
(Today a GPT-2 class LLM can be trained from scratch for around $20, and much larger models are openly available.)
There's a saying in the financial trading business which is 'the market can stay irrational longer than you can stay solvent' - though you might have the right idea about something that will happen in the future, your likelihood of correctly timing the market is pretty low. There's a truth to this for thinking about AI risks - yes, the things we forecast (as long as they're based on a good understanding of the underlying technology) will happen at some point but I think we have a poor record of figuring out a) when they'll happen, b) at what scale they'll happen, and c) how severe their effects will be. This is a big problem when you take your imagined future risks and use them to justify policy actions in the present!
As an early proponent of government regulation around training large models, he offers the following cautionary note:
[...] history shows that once we assign power to governments, they're loathe to subsequently give that power back to the people. Policy is a ratchet and things tend to accrete over time. That means whatever power we assign governments today represents the floor of their power in the future - so we should be extremely cautious in assigning them power because I guarantee we will not be able to take it back.
Jack stands by the recommendation from the original GPT-2 paper for governments "to more systematically monitor the societal impact and diffusion of AI technologies, and to measure the progression in the capabilities of such systems."
Reproducing GPT-2 (124M) in llm.c in 90 minutes for $20 (via) GPT-2 124M was the smallest model in the GPT-2 series released by OpenAI back in 2019. Andrej Karpathy's llm.c is an evolving 4,000 line C/CUDA implementation which can now train a GPT-2 model from scratch in 90 minutes against a 8X A100 80GB GPU server. This post walks through exactly how to run the training, using 10 billion tokens of FineWeb.
Andrej notes that this isn't actually that far off being able to train a GPT-3:
Keep in mind that here we trained for 10B tokens, while GPT-3 models were all trained for 300B tokens. [...] GPT-3 actually didn't change too much at all about the model (context size 1024 -> 2048, I think that's it?).
Estimated cost for a GPT-3 ADA (350M parameters)? About $2,000.
llm.c (via) Andrej Karpathy implements LLM training—initially for GPT-2, other architectures to follow—in just over 1,000 lines of C on top of CUDA. Includes a tutorial about implementing LayerNorm by porting an implementation from Python.
Does GPT-2 Know Your Phone Number? (via) This report from Berkeley Artificial Intelligence Research in December 2020 showed GPT-3 outputting a full page of chapter 3 of Harry Potter and the Philosopher’s Stone—similar to how the recent suit from the New York Times against OpenAI and Microsoft demonstrates memorized news articles from that publication as outputs from GPT-4.
GPT in 500 lines of SQL (via) Utterly brilliant piece of PostgreSQL hackery by Alex Bolenok, who implements a full GPT-2 style language model in SQL on top of pg_vector. The final inference query is 498 lines long!
2023
A token-wise likelihood visualizer for GPT-2. Linus Lee built a superb visualization to help demonstrate how Large Language Models work, in the form of a video essay where each word is coloured to show how “surprising” it is to the model. It’s worth carefully reading the text in the video as each term is highlighted to get the full effect.
Language models can explain neurons in language models (via) Fascinating interactive paper by OpenAI, describing how they used GPT-4 to analyze the concepts tracked by individual neurons in their much older GPT-2 model. “We generated cluster labels by embedding each neuron explanation using the OpenAI Embeddings API, then clustering them and asking GPT-4 to label each cluster.”
2020
When I was curating my generated tweets, I estimated 30-40% of the tweets were usable comedically, a massive improvement over the 5-10% usability from my GPT-2 tweet generation. However, a 30-40% success rate implies a 60-70% failure rate, which is patently unsuitable for a production application.
gpt2-headlines.ipynb. My earliest experiment with GPT-2, using gpt-2-simple by Max Woolf to generate new New York Times headlines based on a GPT-2 fine-tuned against headlines from different decades of that newspaper.