4 posts tagged “colin-dellow”
2024
qrank (via) Interesting and very niche project by Colin Dellow.
Wikidata has pages for huge numbers of concepts, people, places and things.
One of the many pieces of data they publish is QRank—“ranking Wikidata entities by aggregating page views on Wikipedia, Wikispecies, Wikibooks, Wikiquote, and other Wikimedia projects”. Every item gets a score and these scores can be used to answer questions like “which island nations get the most interest across Wikipedia”—potentially useful for things like deciding which labels to display on a highly compressed map of the world.
QRank is published as a gzipped CSV file.
Colin’s hikeratlas/qrank GitHub repository runs weekly, fetches the latest qrank.csv.gz file and loads it into a SQLite database using SQLite’s “.import” mechanism. Then it publishes the resulting SQLite database as an asset attached to the “latest” GitHub release on that repo—currently a 307MB file.
The database itself has just a single table mapping the Wikidata ID (a primary key integer) to the latest QRank—another integer. You’d need your own set of data with Wikidata IDs to join against this to do anything useful.
I’d never thought of using GitHub Releases for this kind of thing. I think it’s a really interesting pattern.
2023
datasette-scraper, Big Local News and other weeknotes
In addition to exploring the new MusicCaps training and evaluation data I’ve been working on the big Datasette JSON refactor, and getting excited about a Datasette project that I didn’t work on at all.
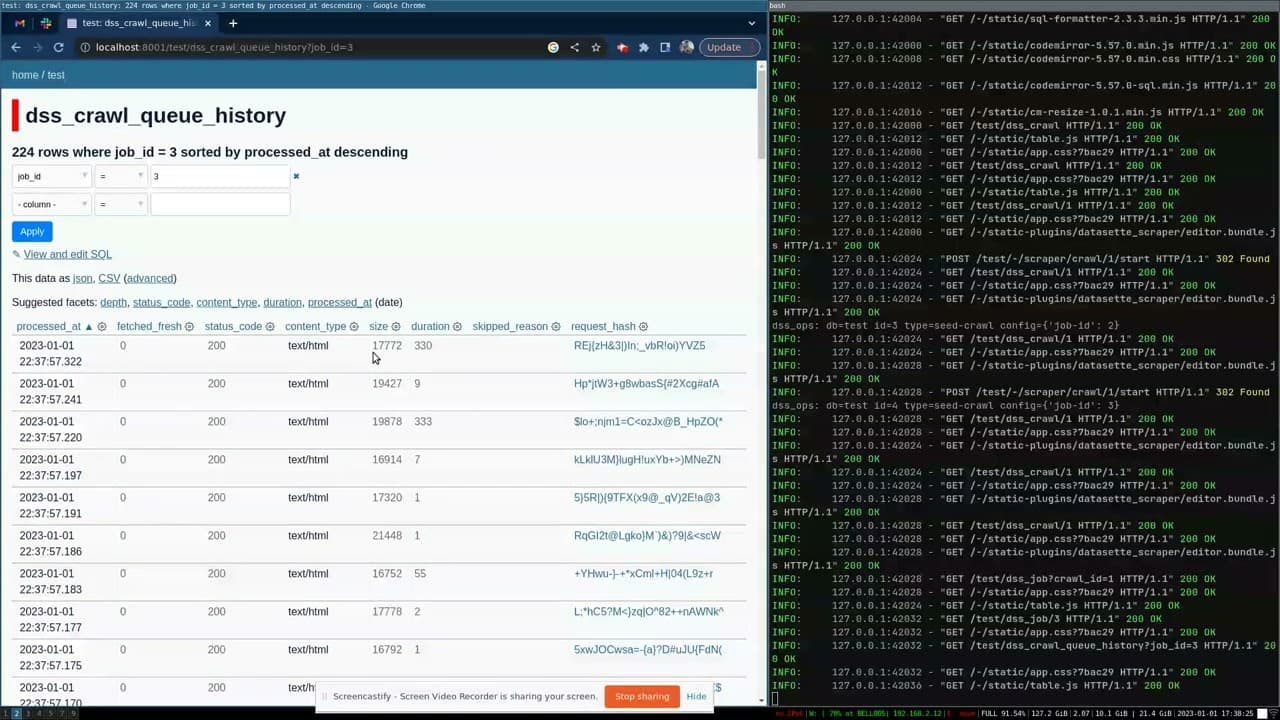
[... 1,744 words]datasette-scraper walkthrough on YouTube (via) datasette-scraper is Colin Dellow’s new plugin that turns Datasette into a powerful web scraping tool, with a web UI based on plugin-driven customizations to the Datasette interface. It’s really impressive, and this ten minute demo shows quite how much it is capable of: it can crawl sitemaps and fetch pages, caching them (using zstandard with optional custom dictionaries for extra compression) to speed up subsequent crawls... and you can add your own plugins to extract structured data from crawled pages and save it to a separate SQLite table!
2018
Query Parquet files in SQLite. Colin Dellow built a SQLite virtual table extension that lets you query Parquet files directly using SQL. Parquet is interesting because it’s a columnar format that dramatically reduces the space needed to store tables with lots of duplicate column data—most CSV files, for example. Colin reports being able to shrink a 1291 MB CSV file from the Canadian census to an equivalent Parquet file weighing just 42MB (3% of the original)—then running a complex query against the data in just 60ms. I’d love to see someone get this extension working with Datasette.