datasette-scraper, Big Local News and other weeknotes
30th January 2023
In addition to exploring the new MusicCaps training and evaluation data I’ve been working on the big Datasette JSON refactor, and getting excited about a Datasette project that I didn’t work on at all.
datasette-scraper
The best thing about a plugin system is that you can wake up one day and your software has grown extra features without you even having to review a pull request.
Colin Dellow’s datasette-scraper—first released a few weeks ago—takes that a step further: it’s a plugin that builds an entire custom application on top of Datasette.
It’s really cool!
Colin has a ten minute demo up on YouTube which is well worth checking out.
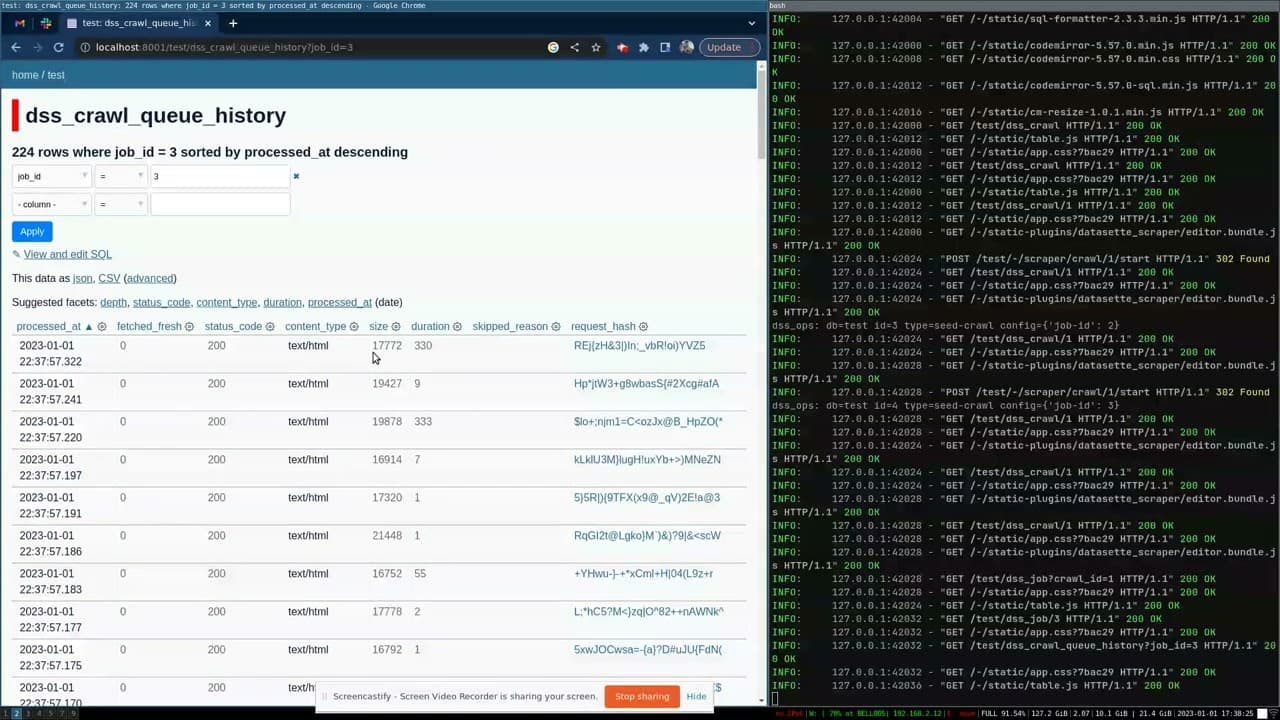
The plugin implements a website crawler which can crawl pages, build up a queue (using sitemap.xml if it’s available), then fetch and cache the content—storing its progress and the resulting data in a SQLite database hosted by Datasette.
It uses some really neat tricks to customize various pieces of the Datasette interface to provide an interface for configuring and controlling the crawler.
Most impressively of all, it implements its own plugin hooks... which means you can use small custom plugins to define how you would like data to be extracted from the pages you are crawling.
Colin has a bunch of other Datasette plugins that are worth checking out too:
- datasette-rewrite-sql monkey-patches Datasette’s database connection code (since there’s no appropriate plugin hook there yet) to provide its own hook for further plugin functions that can rewrite SQL queries before they get executed.
-
datasette-ersatz-table-valued-functions (ersatz (adj.): made or used as a substitute, typically an inferior one, for something else.) is a delightfully gnarly hack which supports custom table-valued SQL functions in SQLite, despite Python’s
sqlite3module not providing those. It works by rewriting a SQL query against a function that returns JSON to use a gnarly CTE and json_each() combo instead. - datasette-ui-extras is brand new: it tweaks the Datasette default interface in various ways, adding features like sticky header and facets in a sidebar. I’m so excited to see someone experimenting with changes to the default UI in this way, and I fully expect that some of the ideas Colin is playing with here will make it into Datasette core in the future.
Datasette and Big Local News
Big Local News is a collaborative data archive for journalists run by a team out of Stanford.
I worked with Ben Welsh this week to build an updated version of an old integration with Datasette, which went live on Friday.
Here’s the animated GIF demo from their announcement:
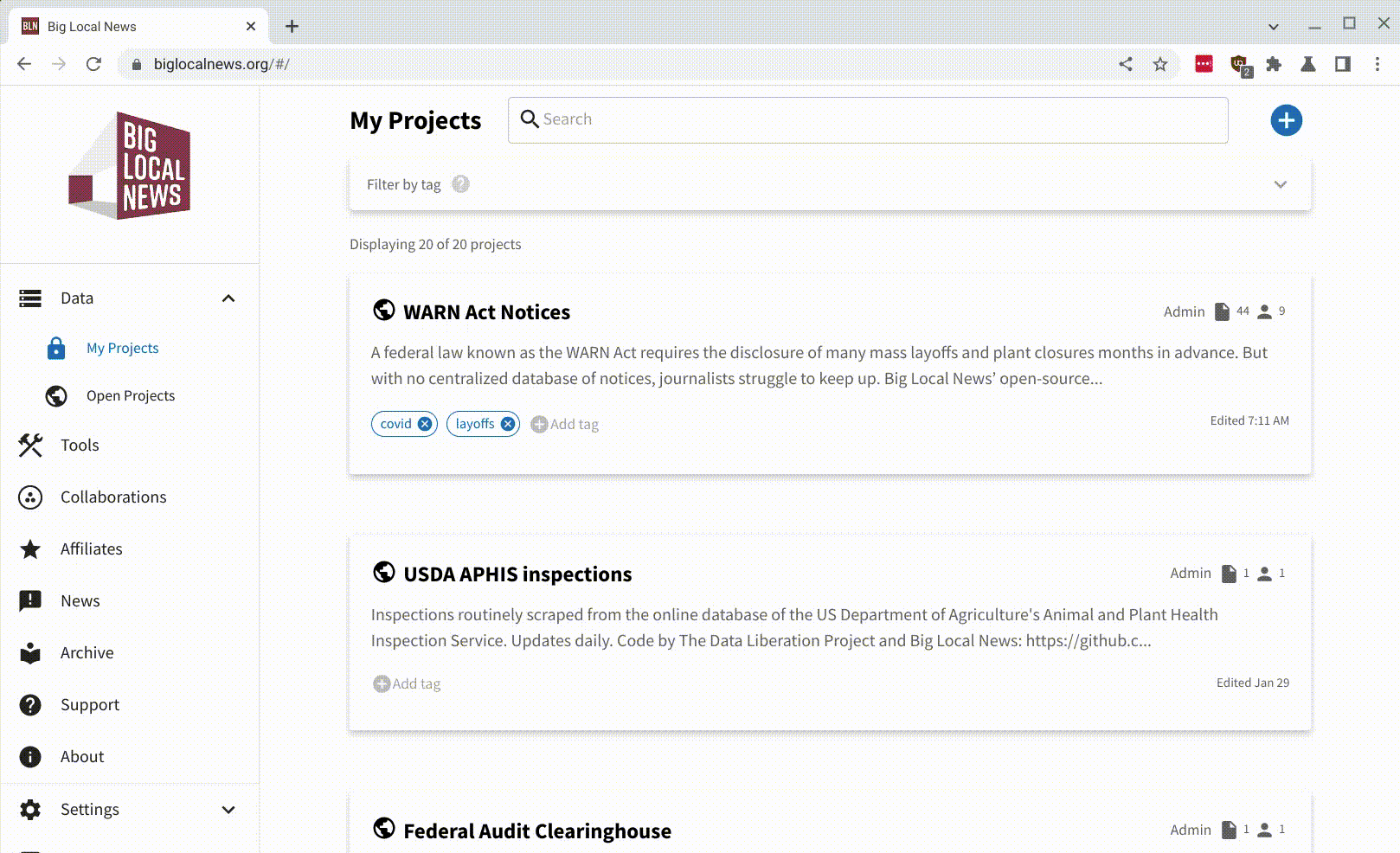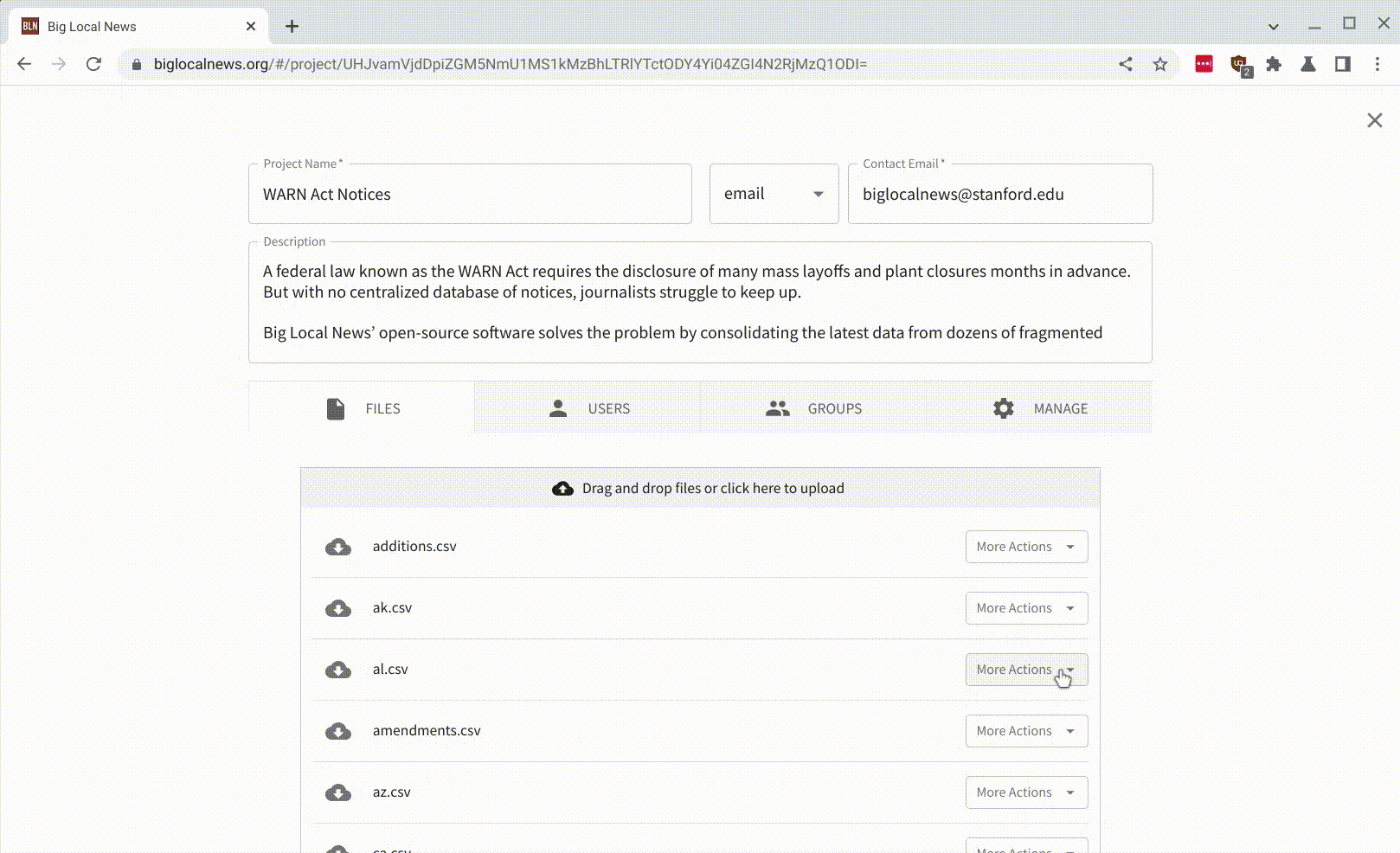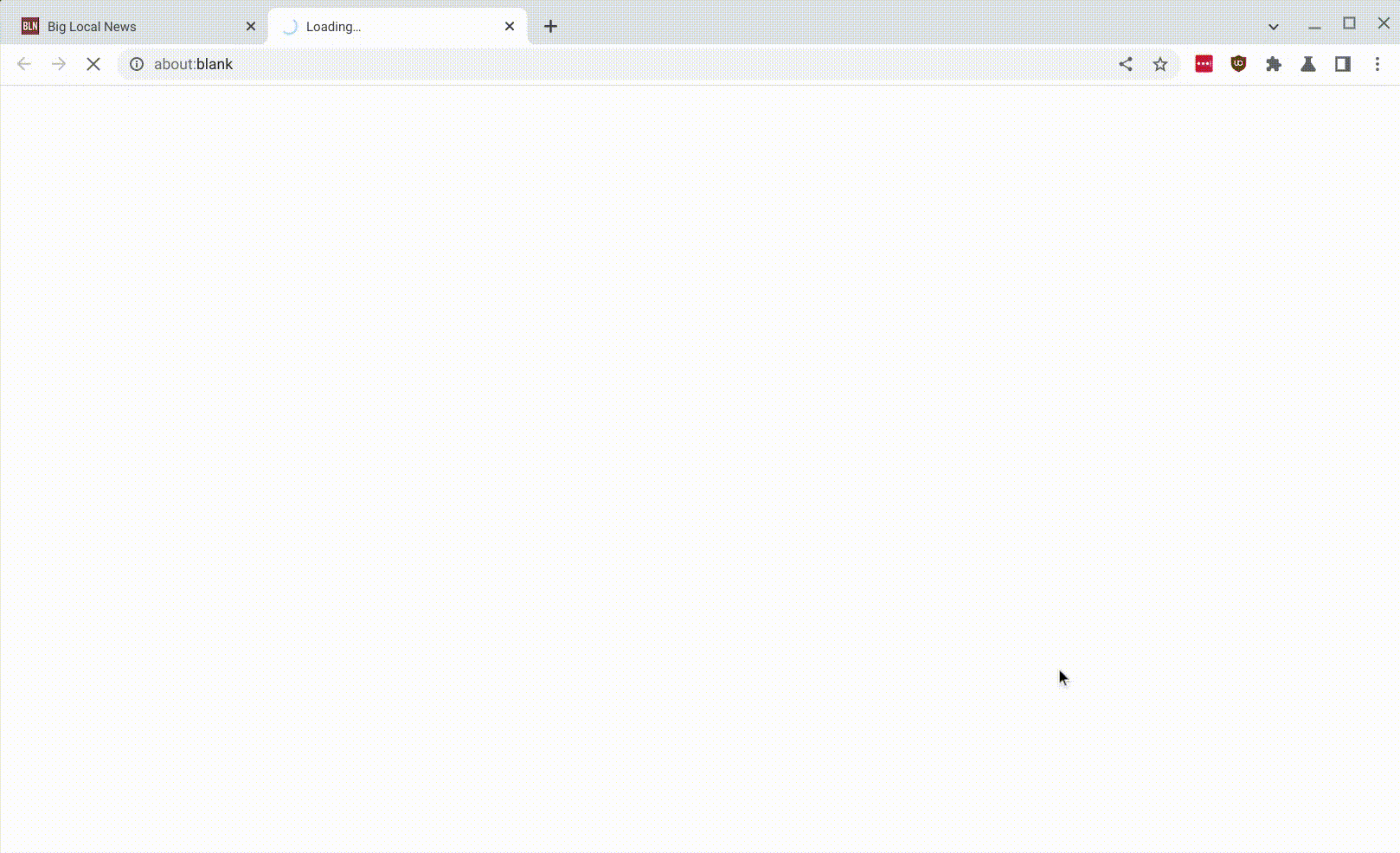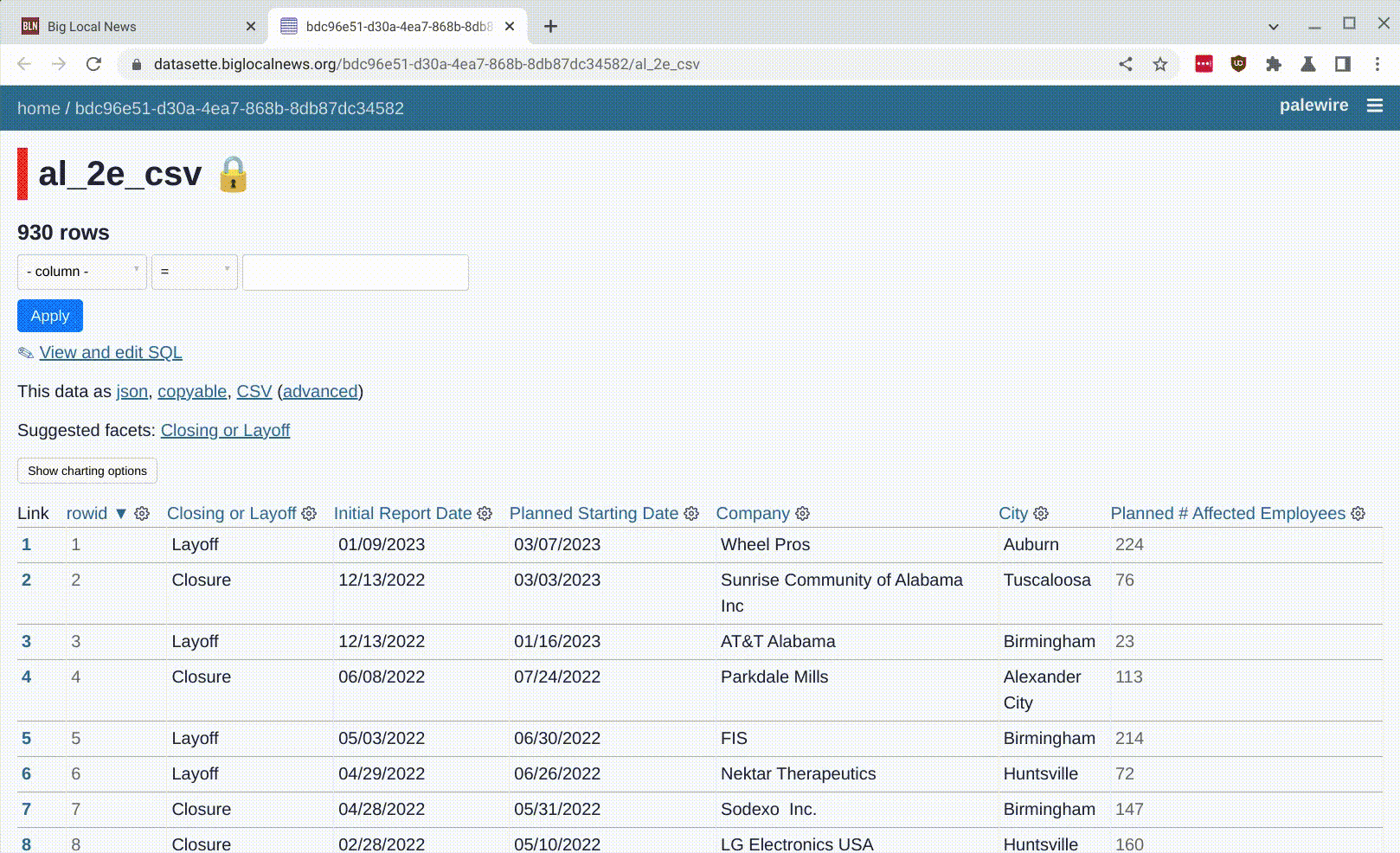
The code I wrote for this integration lives in simonw/datasette-big-local. I ended up building a custom plugin which exclusively works with Big Local (so it’s not shipped to PyPI).
The main challenge with this project involved authentication and permissions. Big Local has both public and private datasets, and we wanted the integration to work with both. But if someone opened a file in a private project, only they and others with access to that project should be able to view the resulting table.
In the end I solved this by creating a new SQLite database for each project, then configuring Datasette’s authentication system to run a permission check for each user to check that they were allowed to access files in the associated project, via a call to the Big Local GraphQL API.
The first time a user opens a file in Big Local JavaScript on the site there performs an HTTP POST to Datasette, transmitting details of the project ID, the filename and an authentication token for that user. That token can then be used by Datasette to call the GraphQL API on their behalf, verifying their permissions and signing them into the Datasette instance using a signed cookie.
The datasette-big-local README includes full details about how this all works.
Progress on ?_extra=
I finally started making progress on Datasette issue #262: Add ?_extra= mechanism for requesting extra properties in JSON—first opened back in May 2018!
This is the key step on the journey to slimming down Datasette’s default JSON representation for tables and queries.
I want to return this by default:
{
"ok": true,
"rows": [
{"id": 1, "title": "Example 1"},
{"id": 2, "title": "Example 2"},
{"id": 3, "title": "Example 3"}
],
"next": null
}Then allow users to specify all kinds of extra information—the table schema, the suggested facets, information on columns, the underlying SQL query... all by adding on ?_extra=x parameters to the URL.
This turns out to be a lot of work: I’m having to completely refactor the internals of the most complicated part of Datasette’s codebase.
Still lots more to go, but I’m happy to finally be making progress here.
Improved Datasette examples
The Datasette website has long had an Examples page linked to from the top navigation—and analytics show that it’s one of the most visited pages on the site.
I finally gave that page the upgrade it needed. It now starts with illustrated examples that have been selected to help highlight what Datasette can do—both the variety of problems it can be used to solve, and the way plugins can be used to add extra functionality.
shot-scraper 1.1
I implemented the new screenshots for the examples page using my shot-scraper screenshot automation tool.
The screenshots are taken by a GitHub Actions workflow in the datasette-screenshots repository.
I added 5 new screenshot definitions to the YAML that powers that workflow, which is used by the shot-scraper multi command.
In working with shot-scraper I spotted a couple of opportunities for small improvements, version 1.1 with the following changes:
- New
--log-consoleoption for logging the output of calls toconsole.log()to standard error. #101- New
--skipand--failoptions to specify what should happen if an HTTP 4xx or 5xx error is encountered while trying to load the page.--skipwill ignore the error and either exit cleanly or move on to the next screenshot (in the case ofmulti).--failwill cause the tool to return a non-zero exit code, useful for running in CI environments. #102
datasette-granian
Granian is a new web server for running Python WSGI and ASGI applications, written in Rust.
A while ago I built datasette-gunicorn, a plugin which adds a datasette gunicorn my.db command for serving Datasette using the Gunicorn WSGI server.
datasette-granian now provides the same thing using Granian. It’s an alpha release because I haven’t actually used it in production yet, but it seems to work well and it adds yet another option for people who want to deploy Datasette.
Creator of Granian Giovanni Barillari was really helpful in helping me figure out how to dynamically serve a freshly configured ASGI application rather than just passing a module path to the granian CLI command.
datasette-faiss 0.2
I introduced datasette-faiss a few weeks ago. It’s a plugin that suppors fast vector similarity lookups within Datasette using the FAISS vector search library by Facebook Research.
The first release of the plugin created a FAISS index on server startup for each table that contains an embeddings column. Any similarity searches would then be run against that entire table.
But what if you want to combine those searches with other filters in a query? For example, first filter to every article published in 2022, then run a similarity search on what’s left.
In datasette-faiss 0.2 I introduced two new SQLite aggregate functions: faiss_agg() and faiss_agg_with_scores(), that are designed to handle this case.
The new functions work by constructing a new FAISS index from scratch every time they are called, covering just the rows that were processed by the aggregation.
This is best illustrated with an example. The following query first selects the embeddings for just the blog entries published in 2022, then uses those to find items that are most similar to the provided ID.
with entries_2022 as (
select
id,
embedding
from
blog_entry_embeddings
where
id in (select id from blog_entry where created like '2022%')
),
faiss as (
select
faiss_agg(
id,
embedding,
(select embedding from blog_entry_embeddings where id = :id),
10
) as results
from
entries_2022
),
ids as (
select
value as id
from
json_each(faiss.results),
faiss
)
select
blog_entry.id,
blog_entry.title,
blog_entry.created
from
ids
join blog_entry on ids.id = blog_entry.idYou can try the query out here.
Releases this week
-
shot-scraper: 1.1—(25 releases total)—2023-01-30
A command-line utility for taking automated screenshots of websites -
datasette-render-markdown: 2.1.1—(10 releases total)—2023-01-27
Datasette plugin for rendering Markdown -
datasette-youtube-embed: 0.1—2023-01-27
Turn YouTube URLs into embedded players in Datasette -
datasette-granian: 0.1a0—2023-01-20
Run Datasette using the Granian HTTP server -
datasette-faiss: 0.2—(2 releases total)—2023-01-19
Maintain a FAISS index for specified Datasette tables
TIL this week
More recent articles
- OpenAI’s accidental cyberattack against Hugging Face is science fiction that happened - 22nd July 2026
- A Fireside Chat with Cat and Thariq from the Claude Code team - 21st July 2026
- Kimi K3, and what we can still learn from the pelican benchmark - 16th July 2026