7 posts tagged “archiving”
2026
Gwtar: a static efficient single-file HTML format (via) Fascinating new project from Gwern Branwen and Said Achmiz that targets the challenge of combining large numbers of assets into a single archived HTML file without that file being inconvenient to view in a browser.
The key trick it uses is to fire window.stop() early in the page to prevent the browser from downloading the whole thing, then following that call with inline tar uncompressed content.
It can then make HTTP range requests to fetch content from that tar data on-demand when it is needed by the page.
The JavaScript that has already loaded rewrites asset URLs to point to https://localhost/ purely so that they will fail to load. Then it uses a PerformanceObserver to catch those attempted loads:
let perfObserver = new PerformanceObserver((entryList, observer) => {
resourceURLStringsHandler(entryList.getEntries().map(entry => entry.name));
});
perfObserver.observe({ entryTypes: [ "resource" ] });
That resourceURLStringsHandler callback finds the resource if it is already loaded or fetches it with an HTTP range request otherwise and then inserts the resource in the right place using a blob: URL.
Here's what the window.stop() portion of the document looks like if you view the source:
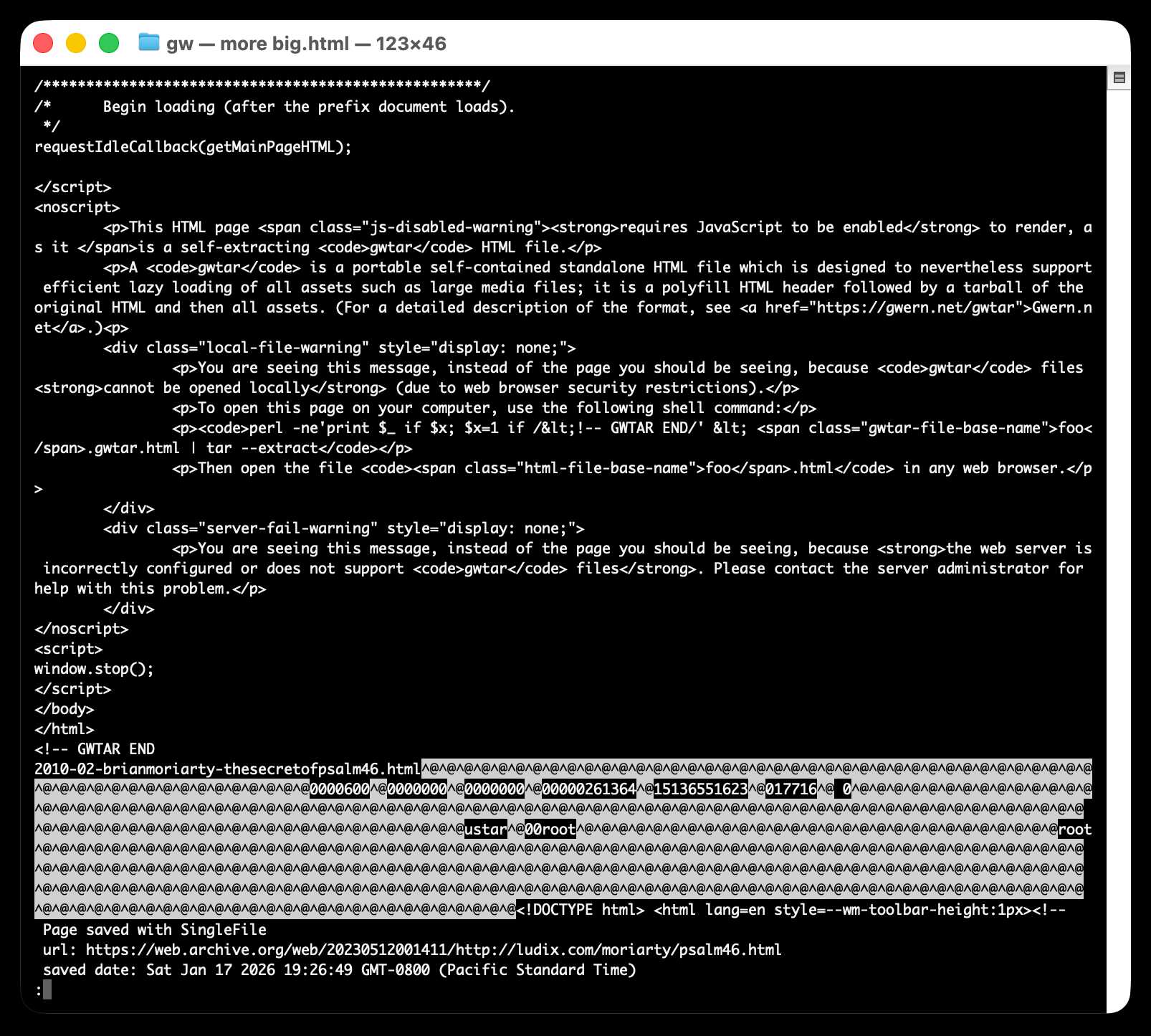
Amusingly for an archive format it doesn't actually work if you open the file directly on your own computer. Here's what you see if you try to do that:
You are seeing this message, instead of the page you should be seeing, because
gwtarfiles cannot be opened locally (due to web browser security restrictions).To open this page on your computer, use the following shell command:
perl -ne'print $_ if $x; $x=1 if /<!-- GWTAR END/' < foo.gwtar.html | tar --extractThen open the file
foo.htmlin any web browser.
2022
Digitizing 55,000 pages of civic meetings (via) Philip James has been building public, searchable archives of city council meetings for various cities—Oakland and Alamedia so far—using my s3-ocr script to run Textract OCR against the PDFs of the minutes, and deploying them to Fly using Datasette. This is a really cool project, and very much the kind of thing I’ve been hoping to support with the tools I’ve been building.
You should take more screenshots (via) Alex Chan suggests saving screenshots of your work, since they may well last a lot longer than the projects themselves. I try to do that these days but I have SO many projects from the past that I didn’t capture in this way, and that I really regret not keeping a better visual record of.
WarcDB (via) Florents Tselai built this tool for loading web crawl data stored in WARC (Web ARChive) format into a SQLite database for smaller-scale analysis with SQL, on top of my sqlite-utils Python library.
2018
Twitter conversation about long-term pre-paid archival storage. I kicked off a conversation on Twitter yesterday about long-time archival storage of web content: “Anyone know of a web hosting provider where I can pay a lump sum of money to host a file at a reliable URL essentially forever? Is this even remotely feasible?”. The thread is really interesting—this is definitely an unsolved problem, and it’s clear that the challenge is more organizational (how do you create an entity that can keep this kind of promise—does it need to be some kind of foundation or trust?) than technical.
2011
UK Web Archive: WW2 People’s War. Good news: the British Library has already archived the BBC’s WW2 People’s War site (on 22nd May 2006).
2009
When APIs go dark, how do you do a data backup? (Answer: you often can't.) With public, microformatted content, there will likely be a public archive that can be used to reconstitute at least portions of the service. With dynamic APIs and proprietary data formats, all bets are off.