Friday, 13th March 2026
Shopify/liquid: Performance: 53% faster parse+render, 61% fewer allocations (via) PR from Shopify CEO Tobias Lütke against Liquid, Shopify's open source Ruby template engine that was somewhat inspired by Django when Tobi first created it back in 2005.
Tobi found dozens of new performance micro-optimizations using a variant of autoresearch, Andrej Karpathy's new system for having a coding agent run hundreds of semi-autonomous experiments to find new effective techniques for training nanochat.
Tobi's implementation started two days ago with this autoresearch.md prompt file and an autoresearch.sh script for the agent to run to execute the test suite and report on benchmark scores.
The PR now lists 93 commits from around 120 automated experiments. The PR description lists what worked in detail - some examples:
- Replaced StringScanner tokenizer with
String#byteindex. Single-bytebyteindexsearching is ~40% faster than regex-basedskip_until. This alone reduced parse time by ~12%.- Pure-byte
parse_tag_token. Eliminated the costlyStringScanner#string=reset that was called for every{% %}token (878 times). Manual byte scanning for tag name + markup extraction is faster than resetting and re-scanning via StringScanner. [...]- Cached small integer
to_s. Pre-computed frozen strings for 0-999 avoid 267Integer#to_sallocations per render.
This all added up to a 53% improvement on benchmarks - truly impressive for a codebase that's been tweaked by hundreds of contributors over 20 years.
I think this illustrates a number of interesting ideas:
- Having a robust test suite - in this case 974 unit tests - is a massive unlock for working with coding agents. This kind of research effort would not be possible without first having a tried and tested suite of tests.
- The autoresearch pattern - where an agent brainstorms a multitude of potential improvements and then experiments with them one at a time - is really effective.
- If you provide an agent with a benchmarking script "make it faster" becomes an actionable goal.
- CEOs can code again! Tobi has always been more hands-on than most, but this is a much more significant contribution than anyone would expect from the leader of a company with 7,500+ employees. I've seen this pattern play out a lot over the past few months: coding agents make it feasible for people in high-interruption roles to productively work with code again.
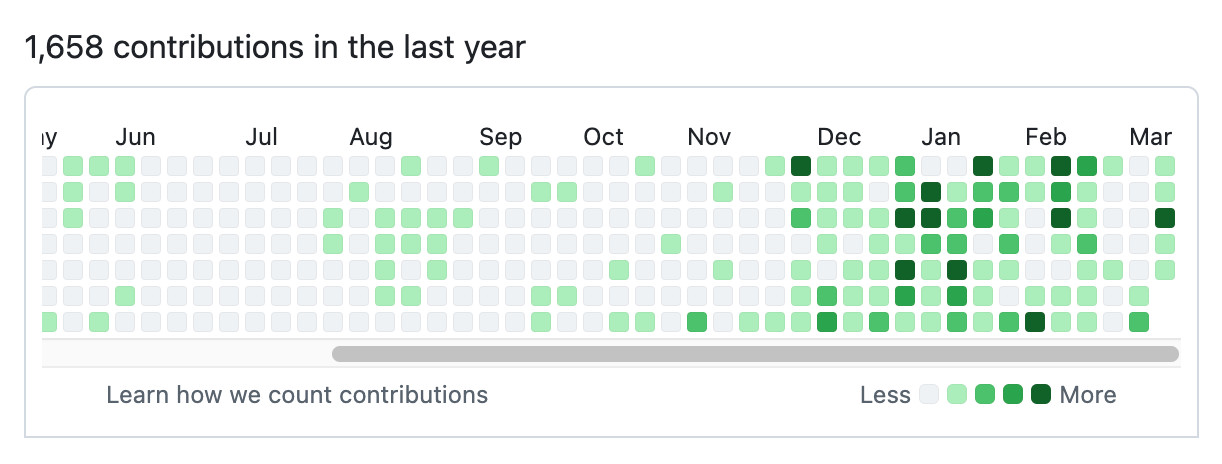
Here's Tobi's GitHub contribution graph for the past year, showing a significant uptick following that November 2025 inflection point when coding agents got really good.
He used Pi as the coding agent and released a new pi-autoresearch plugin in collaboration with David Cortés, which maintains state in an autoresearch.jsonl file like this one.
Simply put: It’s a big mess, and no off-the-shelf accounting software does what I need. So after years of pain, I finally sat down last week and started to build my own. It took me about five days. I am now using the best piece of accounting software I’ve ever used. It’s blazing fast. Entirely local. Handles multiple currencies and pulls daily (historical) conversion rates. It’s able to ingest any CSV I throw at it and represent it in my dashboard as needed. It knows US and Japan tax requirements, and formats my expenses and medical bills appropriately for my accountants. I feed it past returns to learn from. I dump 1099s and K1s and PDFs from hospitals into it, and it categorizes and organizes and packages them all as needed. It reconciles international wire transfers, taking into account small variations in FX rates and time for the transfers to complete. It learns as I categorize expenses and categorizes automatically going forward. It’s easy to do spot checks on data. If I find an anomaly, I can talk directly to Claude and have us brainstorm a batched solution, often saving me from having to manually modify hundreds of entries. And often resulting in a new, small, feature tweak. The software feels organic and pliable in a form perfectly shaped to my hand, able to conform to any hunk of data I throw at it. It feels like bushwhacking with a lightsaber.
— Craig Mod, Software Bonkers
1M context is now generally available for Opus 4.6 and Sonnet 4.6. Here's what surprised me:
Standard pricing now applies across the full 1M window for both models, with no long-context premium.
OpenAI and Gemini both charge more for prompts where the token count goes above a certain point - 200,000 for Gemini 3.1 Pro and 272,000 for GPT-5.4.