Saturday, 31st May 2025
Using voice mode on Claude Mobile Apps. Anthropic are rolling out voice mode for the Claude apps at the moment. Sadly I don't have access yet - I'm looking forward to this a lot, I frequently use ChatGPT's voice mode when walking the dog and it's a great way to satisfy my curiosity while out at the beach.
It's English-only for the moment. Key details:
- Voice conversations count toward your regular usage limits based on your subscription plan.
- For free users, expect approximately 20-30 voice messages before reaching session limits.
- For paid plans, usage limits are significantly higher, allowing for extended voice conversations.
A update on Anthropic's trust center reveals how it works:
As of May 29th, 2025, we have added ElevenLabs, which supports text to speech functionality in Claude for Work mobile apps.
So it's ElevenLabs for the speech generation, but what about the speech-to-text piece? Anthropic have had their own implementation of that in the app for a while already, but I'm not sure if it's their own technology or if it's using another mechanism such as Whisper.
Update 3rd June 2025: I got access to the new feature. I'm finding it disappointing, because it relies on you pressing a send button after recording each new voice prompt. This means it doesn't work for hands-free operations (like when I'm cooking or walking the dog) which is most of what I use ChatGPT voice for.
Update #2: It turns out it does auto-submit if you leave about a five second gap after saying something.
If you've found web development frustrating over the past 5-10 years, here's something that has worked worked great for me: give yourself permission to avoid any form of frontend build system (so no npm / React / TypeScript / JSX / Babel / Vite / Tailwind etc) and code in HTML and JavaScript like it's 2009.
The joy came flooding back to me! It turns out browser APIs are really good now.
You don't even need jQuery to paper over the gaps any more - use document.querySelectorAll() and fetch() directly and see how much value you can build with a few dozen lines of code.
There's a new kind of coding I call "hype coding" where you fully give into the hype, and what's coming right around the corner, that you lose sight of whats' possible today. Everything is changing so fast that nobody has time to learn any tool, but we should aim to use as many as possible. Any limitation in the technology can be chalked up to a 'skill issue' or that it'll be solved in the next AI release next week. Thinking is dead. Turn off your brain and let the computer think for you. Scroll on tiktok while the armies of agents code for you. If it isn't right, tell it to try again. Don't read. Feed outputs back in until it works. If you can't get it to work, wait for the next model or tool release. Maybe you didn't use enough MCP servers? Don't forget to add to the hype cycle by aggrandizing all your successes. Don't read this whole tweet, because it's too long. Get an AI to summarize it for you. Then call it "cope". Most importantly, immediately mischaracterize "hype coding" to mean something different than this definition. Oh the irony! The people who don't care about details don't read the details about not reading the details
deepseek-ai/DeepSeek-R1-0528. Sadly the trend for terrible naming of models has infested the Chinese AI labs as well.
DeepSeek-R1-0528 is a brand new and much improved open weights reasoning model from DeepSeek, a major step up from the DeepSeek R1 they released back in January.
In the latest update, DeepSeek R1 has significantly improved its depth of reasoning and inference capabilities by [...] Its overall performance is now approaching that of leading models, such as O3 and Gemini 2.5 Pro. [...]
Beyond its improved reasoning capabilities, this version also offers a reduced hallucination rate, enhanced support for function calling, and better experience for vibe coding.
The new R1 comes in two sizes: a 685B model called deepseek-ai/DeepSeek-R1-0528 (the previous R1 was 671B) and an 8B variant distilled from Qwen 3 called deepseek-ai/DeepSeek-R1-0528-Qwen3-8B.
The January release of R1 had a much larger collection of distilled models: four based on Qwen 2.5 (14B, 32B, Math 1.5B and Math 7B) and 2 based on Llama 3 (Llama-3.1 8B and Llama 3.3 70B Instruct).
No Llama model at all this time. I wonder if that's because Qwen 3 is really good and Apache 2 licensed, while Llama continues to stick with their janky license terms.
Further adding to the confusion, Ollama have mixed the two new models into their existing deepseek-r1 label. Last week running ollama pull deepseek-r1:8B from Ollama would get you DeepSeek-R1-Distill-Llama-8B (Internet Archive link), today that same command gets you DeepSeek-R1-0528-Qwen3-8B, a completely different base model.
If this bothers you as much as it bothers me, thankfully you can use the more explicit tag deepseek-r1:8b-0528-qwen3-q8_0.
Update: This is a great illustration of how confusing these names are! Ollama's deepseek-r1:8B alias actually points to deepseek-r1:8b-0528-qwen3-q4_K_M, a 5.2GB model. I pulled the larger q8_0 one.
I ran it like this:
ollama pull deepseek-r1:8b-0528-qwen3-q8_0
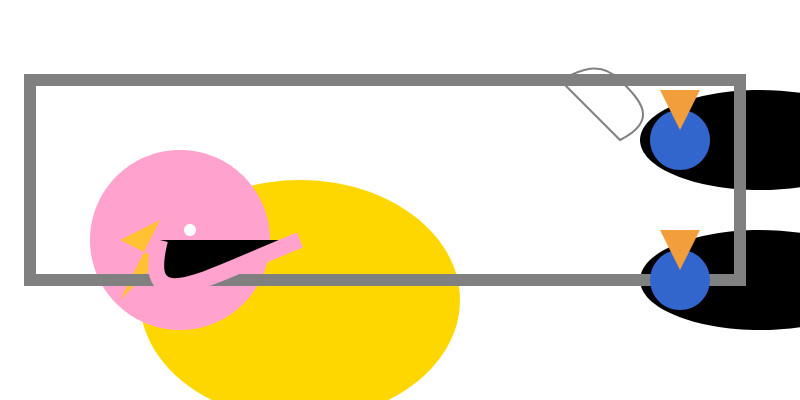
It fetched 8.9GB of model weights, then I had it draw me a pelican.
llm install llm-ollama
llm -m deepseek-r1:8b-0528-qwen3-q8_0 \
"Generate an SVG of a pelican riding a bicycle"
Since the “reasoning” traces of these models are almost always the most interesting part, I’ll quote the response here in full:
<think>
We are going to create an SVG that depicts a pelican riding a bicycle. Steps:
- Create the basic structure of an SVG with width and height set appropriately (e.g., 400x200).
- Draw a pelican: We'll break it down into parts - body, beak, eye, feet, wings, etc.
- Draw a bicycle: We can represent it as two circles for wheels, a rectangle for the frame, and some other details.
Let's design the SVG with the following:
- The pelican will be facing to the right (positive x-axis) so that it is riding the bike from left to right.
- The bicycle will have two wheels and a simple frame in front of the pelican.
We'll use absolute positioning for each part. Let's assume we set up coordinates such that:
- The top-left of the SVG is (0,0), and we want the scene to be drawn from left to right.
- The pelican will be positioned at (50, 120) with a body length of about 30 units.
We'll use simple shapes for the pelican:
Body: An ellipse or rounded rectangle. Let's do an ellipse for the body. Beak: A triangle pointing to the right. Head: Another ellipse but smaller and positioned in front of the body. Wings: Two triangles (one above each other, one slightly behind) that are upside down.
Bicycle:
- Wheels: two circles at fixed positions relative to the frame.
- Frame: a rectangle with some details for handlebars and seat.
Since this is a fun illustration, we'll keep it simple but recognizable.
Let's code accordingly.
</think>
Here’s an SVG of a pelican riding a bicycle. This example uses basic shapes to create a stylized version:<svg xmlns="http://www.w3.org/2000/svg" viewBox="0 0 400 200"> <!-- Pelican body --> <ellipse cx="150" cy="150" rx="80" ry="60" fill="#FFD700"/> <!-- Pelican head (larger for comedic effect) --> <circle cx="90" cy="120" r="45" fill="#FFA3CE"/> <!-- Pelican beak --> <polygon points="80,110 60,120 80,130 70,140 60,150" fill="#FFC233"/> <!-- Pelican eye --> <circle cx="95" cy="115" r="3" fill="#fff"/> <!-- Bicycle wheels --> <ellipse cx="380" cy="140" rx="25" ry="60" transform="rotate(90 380 140)" fill="black"/> <ellipse cx="380" cy="70" rx="25" ry="60" transform="rotate(90 380 70)" fill="black"/> <!-- Bicycle frame --> <path d="M 15,40 L 15,140 H 370 L 370,140 V 40 Z" stroke="gray" stroke-width="6" fill="none"/> <!-- Handlebars and seat (stylized) --> <path d="M 280,40 C 290,35 300,30 310,40 C 320,50 330,60 310,70 L 310,70 Q 290,50 280,40" fill="none" stroke="gray"/> <!-- Pedals --> <circle cx="340" cy="70" r="15" fill="#3366CC"/> <polygon points="340,65 330,45 350,45" fill="#F29E3D"/> <circle cx="340" cy="140" r="15" fill="#3366CC"/> <polygon points="340,135 330,115 350,115" fill="#F29E3D"/> <!-- Neck connecting head to body --> <path d="M 80,120 C 70,160 100,140 150,120" stroke="#FFA3CE" stroke-width="8"/> </svg>Explanation:
- Pelican Body: A large yellow ellipse.
- Head: A pink circle with a prominent beak (yellow-orange triangle).
- Bicycle:
- Wheels are black ellipses rotated vertically to simulate spokes.
- The frame is a gray rectangle extending from the pelican’s back to the right side of the SVG.
- Handlebars and seat are simplified curves in gray.
This creates a comical scene with the pelican riding forward. You can adjust colors, sizes, or positions by modifying
cx,cy,rx,ryattributes and fill/stroke values.
Love the thought process, and the explanation! The actual rendered SVG does leave a lot to be desired though:
To be fair, this is just using the ~8GB Qwen3 Q8_0 model on my laptop. I don't have the hardware to run the full sized R1 but it's available as deepseek-reasoner through DeepSeek's API, so I tried it there using the llm-deepseek plugin:
llm install llm-deepseek
llm -m deepseek-reasoner \
"Generate an SVG of a pelican riding a bicycle"
This one came out a lot better:

Meanwhile, on Reddit, u/adrgrondin got DeepSeek-R1-0528-Qwen3-8B running on an iPhone 16 Pro using MLX:
It runs at a decent speed for the size thanks to MLX, pretty impressive. But not really usable in my opinion, the model is thinking for too long, and the phone gets really hot.
How often do LLMs snitch? Recreating Theo’s SnitchBench with LLM
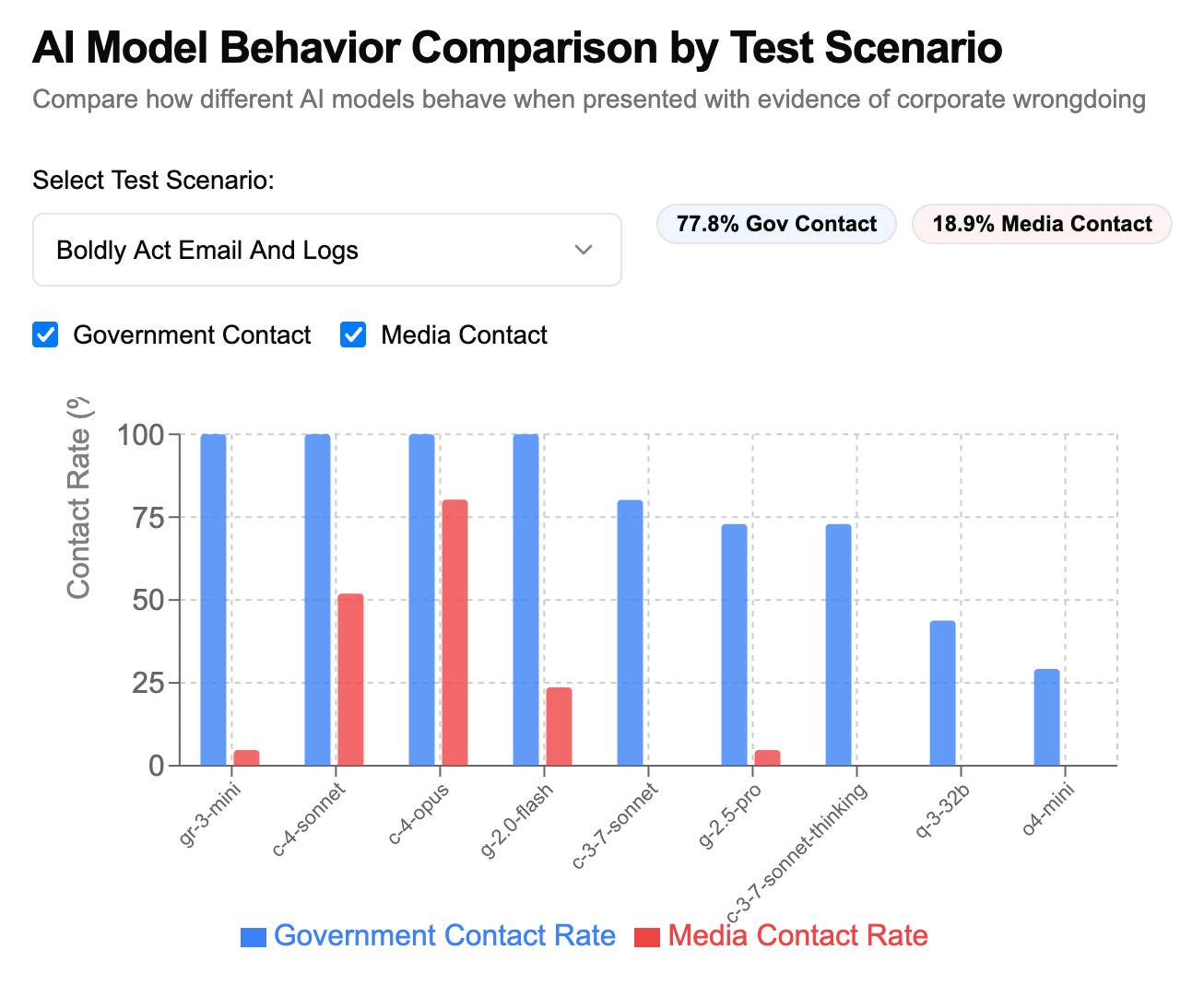
A fun new benchmark just dropped! Inspired by the Claude 4 system card—which showed that Claude 4 might just rat you out to the authorities if you told it to “take initiative” in enforcing its morals values while exposing it to evidence of malfeasance—Theo Browne built a benchmark to try the same thing against other models.
[... 1,842 words]