Thursday, 27th March 2025
Nomic Embed Code: A State-of-the-Art Code Retriever. Nomic have released a new embedding model that specializes in code, based on their CoRNStack "large-scale high-quality training dataset specifically curated for code retrieval".
The nomic-embed-code model is pretty large - 26.35GB - but the announcement also mentioned a much smaller model (released 5 months ago) called CodeRankEmbed which is just 521.60MB.
I missed that when it first came out, so I decided to give it a try using my llm-sentence-transformers plugin for LLM.
llm install llm-sentence-transformers
llm sentence-transformers register nomic-ai/CodeRankEmbed --trust-remote-code
Now I can run the model like this:
llm embed -m sentence-transformers/nomic-ai/CodeRankEmbed -c 'hello'
This outputs an array of 768 numbers, starting [1.4794224500656128, -0.474479079246521, ....
Where this gets fun is combining it with my Symbex tool to create and then search embeddings for functions in a codebase.
I created an index for my LLM codebase like this:
cd llm
symbex '*' '*.*' --nl > code.txt
This creates a newline-separated JSON file of all of the functions (from '*') and methods (from '*.*') in the current directory - you can see that here.
Then I fed that into the llm embed-multi command like this:
llm embed-multi \
-d code.db \
-m sentence-transformers/nomic-ai/CodeRankEmbed \
code code.txt \
--format nl \
--store \
--batch-size 10
I found the --batch-size was needed to prevent it from crashing with an error.
The above command creates a collection called code in a SQLite database called code.db.
Having run this command I can search for functions that match a specific search term in that code collection like this:
llm similar code -d code.db \
-c 'Represent this query for searching relevant code: install a plugin' | jq
That "Represent this query for searching relevant code: " prefix is required by the model. I pipe it through jq to make it a little more readable, which gives me these results.
This jq recipe makes for a better output:
llm similar code -d code.db \
-c 'Represent this query for searching relevant code: install a plugin' | \
jq -r '.id + "\n\n" + .content + "\n--------\n"'
The output from that starts like so:
llm/cli.py:1776
@cli.command(name="plugins")
@click.option("--all", help="Include built-in default plugins", is_flag=True)
def plugins_list(all):
"List installed plugins"
click.echo(json.dumps(get_plugins(all), indent=2))
--------
llm/cli.py:1791
@cli.command()
@click.argument("packages", nargs=-1, required=False)
@click.option(
"-U", "--upgrade", is_flag=True, help="Upgrade packages to latest version"
)
...
def install(packages, upgrade, editable, force_reinstall, no_cache_dir):
"""Install packages from PyPI into the same environment as LLM"""
Getting this output was quite inconvenient, so I've opened an issue.
Thoughts on setting policy for new AI capabilities. Joanne Jang leads model behavior at OpenAI. Their release of GPT-4o image generation included some notable relaxation of OpenAI's policies concerning acceptable usage - I noted some of those the other day.
Joanne summarizes these changes like so:
tl;dr we’re shifting from blanket refusals in sensitive areas to a more precise approach focused on preventing real-world harm. The goal is to embrace humility: recognizing how much we don't know, and positioning ourselves to adapt as we learn.
This point in particular resonated with me:
- Trusting user creativity over our own assumptions. AI lab employees should not be the arbiters of what people should and shouldn’t be allowed to create.
A couple of years ago when OpenAI were the only AI lab with models that were worth spending time with it really did feel that San Francisco cultural values (which I relate to myself) were being pushed on the entire world. That cultural hegemony has been broken now by the increasing pool of global organizations that can produce models, but it's still reassuring to see the leading AI lab relaxing its approach here.
GPT-4o got another update in ChatGPT. This is a somewhat frustrating way to announce a new model. @OpenAI on Twitter just now:
GPT-4o got an another update in ChatGPT!
What's different?
- Better at following detailed instructions, especially prompts containing multiple requests
- Improved capability to tackle complex technical and coding problems
- Improved intuition and creativity
- Fewer emojis 🙃
This sounds like a significant upgrade to GPT-4o, albeit one where the release notes are limited to a single tweet.
ChatGPT-4o-latest (2025-0-26) just hit second place on the LM Arena leaderboard, behind only Gemini 2.5, so this really is an update worth knowing about.
The @OpenAIDevelopers account confirmed that this is also now available in their API:
chatgpt-4o-latestis now updated in the API, but stay tuned—we plan to bring these improvements to a dated model in the API in the coming weeks.
I wrote about chatgpt-4o-latest last month - it's a model alias in the OpenAI API which provides access to the model used for ChatGPT, available since August 2024. It's priced at $5/million input and $15/million output - a step up from regular GPT-4o's $2.50/$10.
I'm glad they're going to make these changes available as a dated model release - the chatgpt-4o-latest alias is risky to build software against due to its tendency to change without warning.
A more appropriate place for this announcement would be the OpenAI Platform Changelog, but that's not had an update since the release of their new audio models on March 20th.
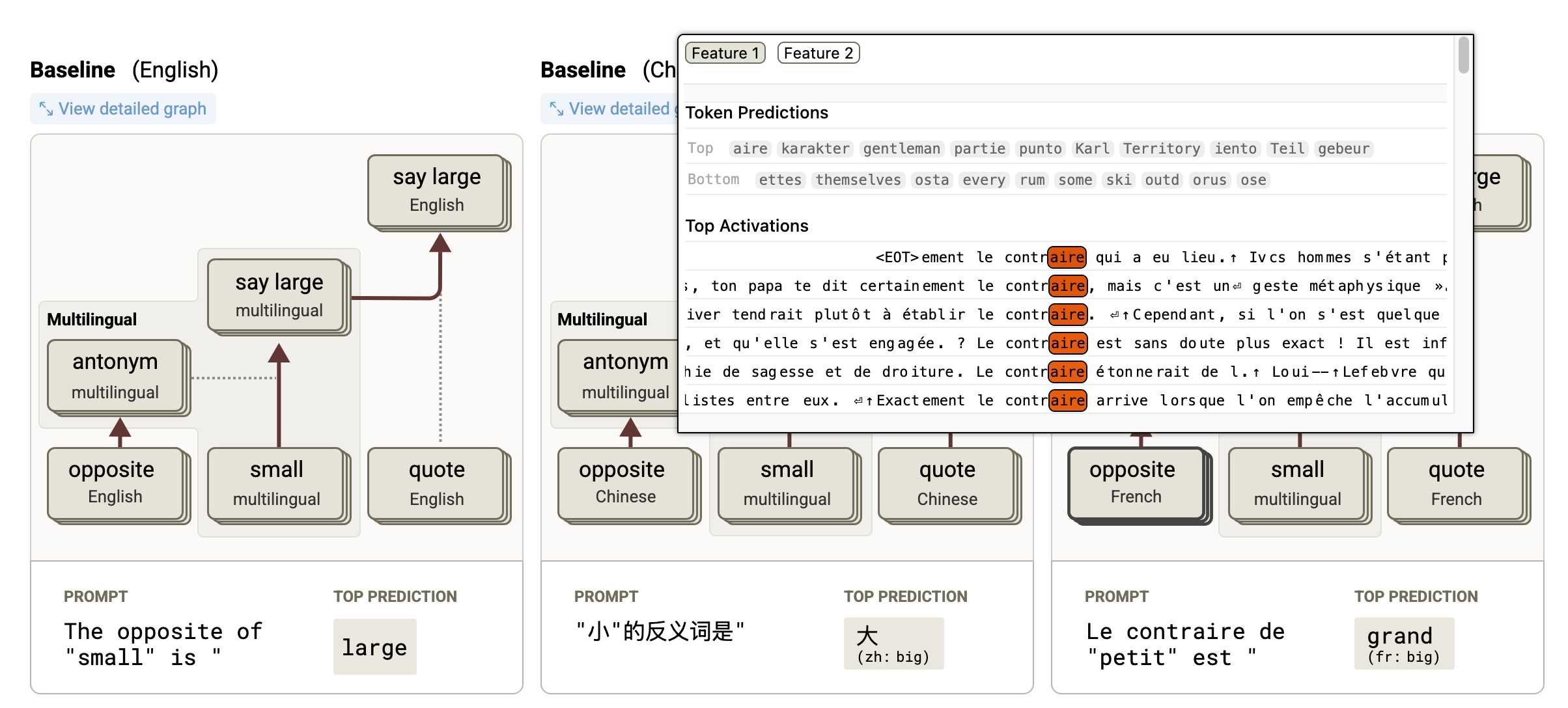
Tracing the thoughts of a large language model. In a follow-up to the research that brought us the delightful Golden Gate Claude last year, Anthropic have published two new papers about LLM interpretability:
- Circuit Tracing: Revealing Computational Graphs in Language Models extends last year's interpretable features into attribution graphs, which can "trace the chain of intermediate steps that a model uses to transform a specific input prompt into an output response".
- On the Biology of a Large Language Model uses that methodology to investigate Claude 3.5 Haiku in a bunch of different ways. Multilingual Circuits for example shows that the same prompt in three different languages uses similar circuits for each one, hinting at an intriguing level of generalization.
To my own personal delight, neither of these papers are published as PDFs. They're both presented as glorious mobile friendly HTML pages with linkable sections and even some inline interactive diagrams. More of this please!