Monday, 4th August 2025
This week, ChatGPT is on track to reach 700M weekly active users — up from 500M at the end of March and 4× since last year.
— Nick Turley, Head of ChatGPT, OpenAI
I Saved a PNG Image To A Bird. Benn Jordan provides one of the all time great YouTube video titles, and it's justified. He drew an image in an audio spectrogram, played that sound to a talented starling (internet celebrity "The Mouth") and recorded the result that the starling almost perfectly imitated back to him.
Hypothetically, if this were an audible file transfer protocol that used a 10:1 data compression ratio, that's nearly 2 megabytes of information per second. While there are a lot of caveats and limitations there, the fact that you could set up a speaker in your yard and conceivably store any amount of data in songbirds is crazy.
This video is full of so much more than just that. Fast forward to 5m58s for footage of a nest full of brown pelicans showing the sounds made by their chicks!
for services that wrap GPT-3, is it possible to do the equivalent of sql injection? like, a prompt-injection attack? make it think it's completed the task and then get access to the generation, and ask it to repeat the original instruction?
— @himbodhisattva, coining the term prompt injection on 13th May 2022, four months before I did
Qwen-Image: Crafting with Native Text Rendering (via) Not content with releasing six excellent open weights LLMs in July, Qwen are kicking off August with their first ever image generation model.
Qwen-Image is a 20 billion parameter MMDiT (Multimodal Diffusion Transformer, originally proposed for Stable Diffusion 3) model under an Apache 2.0 license. The Hugging Face repo is 53.97GB.
Qwen released a detailed technical report (PDF) to accompany the model. The model builds on their Qwen-2.5-VL vision LLM, and they also made extensive use of that model to help create some of their their training data:
In our data annotation pipeline, we utilize a capable image captioner (e.g., Qwen2.5-VL) to generate not only comprehensive image descriptions, but also structured metadata that captures essential image properties and quality attributes.
Instead of treating captioning and metadata extraction as independent tasks, we designed an annotation framework in which the captioner concurrently describes visual content and generates detailed information in a structured format, such as JSON. Critical details such as object attributes, spatial relationships, environmental context, and verbatim transcriptions of visible text are captured in the caption, while key image properties like type, style, presence of watermarks, and abnormal elements (e.g., QR codes or facial mosaics) are reported in a structured format.
They put a lot of effort into the model's ability to render text in a useful way. 5% of the training data (described as "billions of image-text pairs") was data "synthesized through controlled text rendering techniques", ranging from simple text through text on an image background up to much more complex layout examples:
To improve the model’s capacity to follow complex, structured prompts involving layout-sensitive content, we propose a synthesis strategy based on programmatic editing of pre-defined templates, such as PowerPoint slides or User Interface Mockups. A comprehensive rule-based system is designed to automate the substitution of placeholder text while maintaining the integrity of layout structure, alignment, and formatting.
I tried the model out using the ModelScope demo - I signed in with GitHub and verified my account via a text message to a phone number. Here's what I got for "A raccoon holding a sign that says "I love trash" that was written by that raccoon":

The raccoon has very neat handwriting!
Update: A version of the model exists that can edit existing images but it's not yet been released:
Currently, we have only open-sourced the text-to-image foundation model, but the editing model is also on our roadmap and planned for future release.
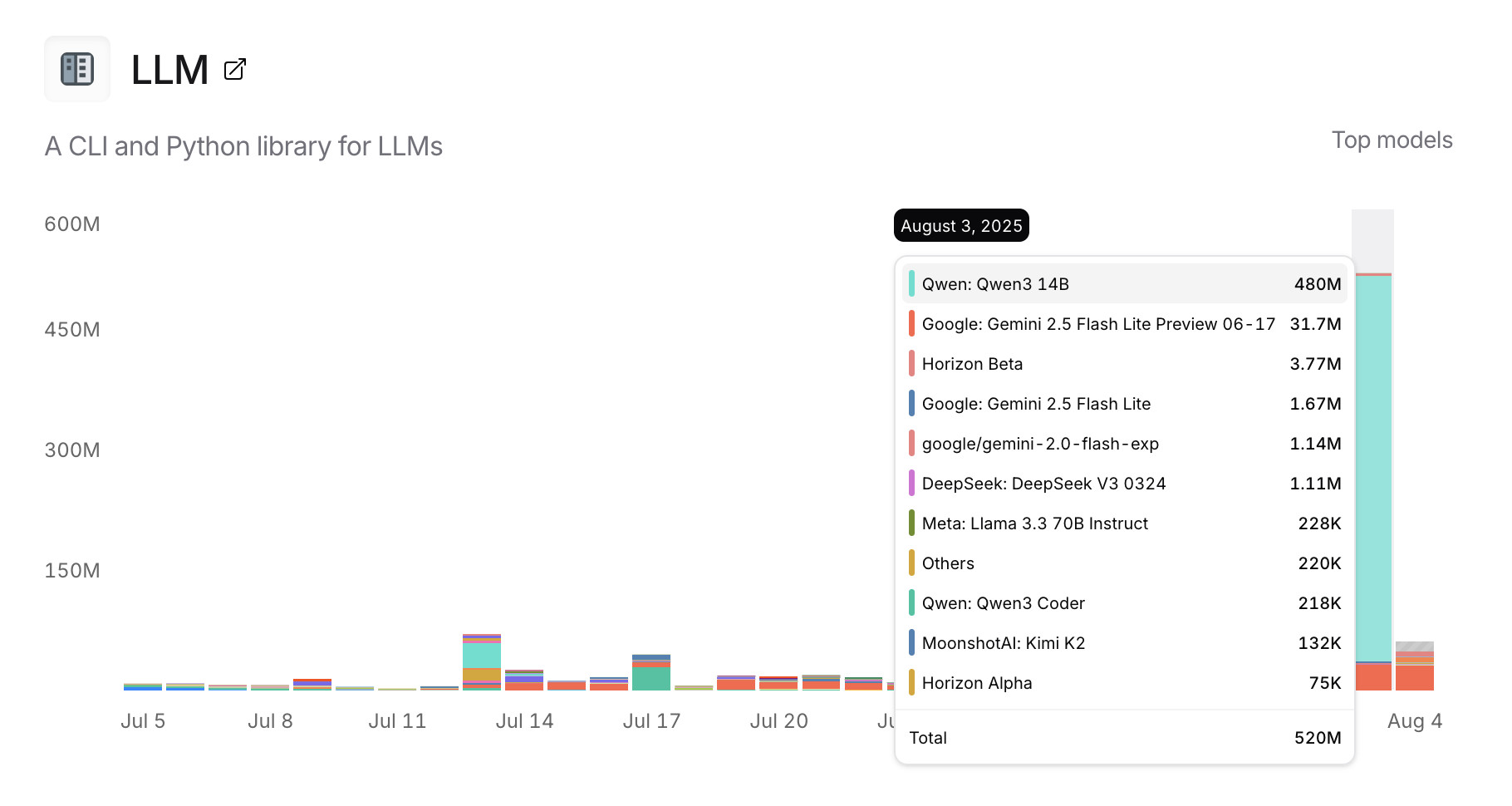
Usage charts for my LLM tool against OpenRouter. OpenRouter proxies requests to a large number of different LLMs and provides high level statistics of which models are the most popular among their users.
Tools that call OpenRouter can include HTTP-Referer and X-Title headers to credit that tool with the token usage. My llm-openrouter plugin does that here.
... which means this page displays aggregate stats across users of that plugin! Looks like someone has been running a lot of traffic through Qwen 3 14B recently.
ChatGPT agent’s user-agent
I was exploring how ChatGPT agent works today. I learned some interesting things about how it exposes its identity through HTTP headers, then made a huge blunder in thinking it was leaking its URLs to Bingbot and Yandex... but it turned out that was a Cloudflare feature that had nothing to do with ChatGPT.
[... 1,260 words]