Image segmentation using Gemini 2.5
18th April 2025
Max Woolf pointed out this new feature of the Gemini 2.5 series (here’s my coverage of 2.5 Pro and 2.5 Flash) in a comment on Hacker News:
One hidden note from Gemini 2.5 Flash when diving deep into the documentation: for image inputs, not only can the model be instructed to generated 2D bounding boxes of relevant subjects, but it can also create segmentation masks!
At this price point with the Flash model, creating segmentation masks is pretty nifty.
I built a tool last year to explore Gemini’s bounding box abilities. This new segmentation mask feature represents a significant new capability!
Here’s my new tool to try it out: Gemini API Image Mask Visualization. As with my bounding box tool it’s browser-based JavaScript that talks to the Gemini API directly. You provide it with a Gemini API key which isn’t logged anywhere that I can see it.
This is what it can do:

Give it an image and a prompt of the form:
Give the segmentation masks for the objects. Output a JSON list of segmentation masks where each entry contains the 2D bounding box in the key "box_2d" and the segmentation mask in key "mask".
My tool then runs the prompt and displays the resulting JSON. The Gemini API returns segmentation masks as base64-encoded PNG images in strings that start data:image/png;base64,iVBOR.... The tool then visualizes those in a few different ways on the page, including overlaid over the original image.
I vibe coded the whole thing together using a combination of Claude and ChatGPT. I started with a Claude Artifacts React prototype, then pasted the code from my old project into Claude and hacked on that until I ran out of tokens. I transferred the incomplete result to a new Claude session where I kept on iterating until it got stuck in a bug loop (the same bug kept coming back no matter how often I told it to fix that)... so I switched over to O3 in ChatGPT to finish it off.
Here’s the finished code. It’s a total mess, but it’s also less than 500 lines of code and the interface solves my problem in that it lets me explore the new Gemini capability.
Segmenting my pelican photo via the Gemini API was absurdly inexpensive. Using Gemini 2.5 Pro the call cost 303 input tokens and 353 output tokens, for a total cost of 0.2144 cents (less than a quarter of a cent). I ran it again with the new Gemini 2.5 Flash and it used 303 input tokens and 270 output tokens, for a total cost of 0.099 cents (less than a tenth of a cent). I calculated these prices using my LLM pricing calculator tool.
1/100th of a cent with Gemini 2.5 Flash non-thinking
Gemini 2.5 Flash has two pricing models. Input is a standard $0.15/million tokens, but the output charges differ a lot: in non-thinking mode output is $0.60/million, but if you have thinking enabled (the default) output is $3.50/million. I think of these as “Gemini 2.5 Flash” and “Gemini 2.5 Flash Thinking”.
My initial experiments all used thinking mode. I decided to upgrade the tool to try non-thinking mode, but noticed that the API library it was using (google/generative-ai) is marked as deprecated.
On a hunch, I pasted the code into the new o4-mini-high model in ChatGPT and prompted it with:
This code needs to be upgraded to the new recommended JavaScript library from Google. Figure out what that is and then look up enough documentation to port this code to it
o4-mini and o3 both have search tool access and claim to be good at mixing different tool uses together.
This worked extremely well! It ran a few searches and identified exactly what needed to change:
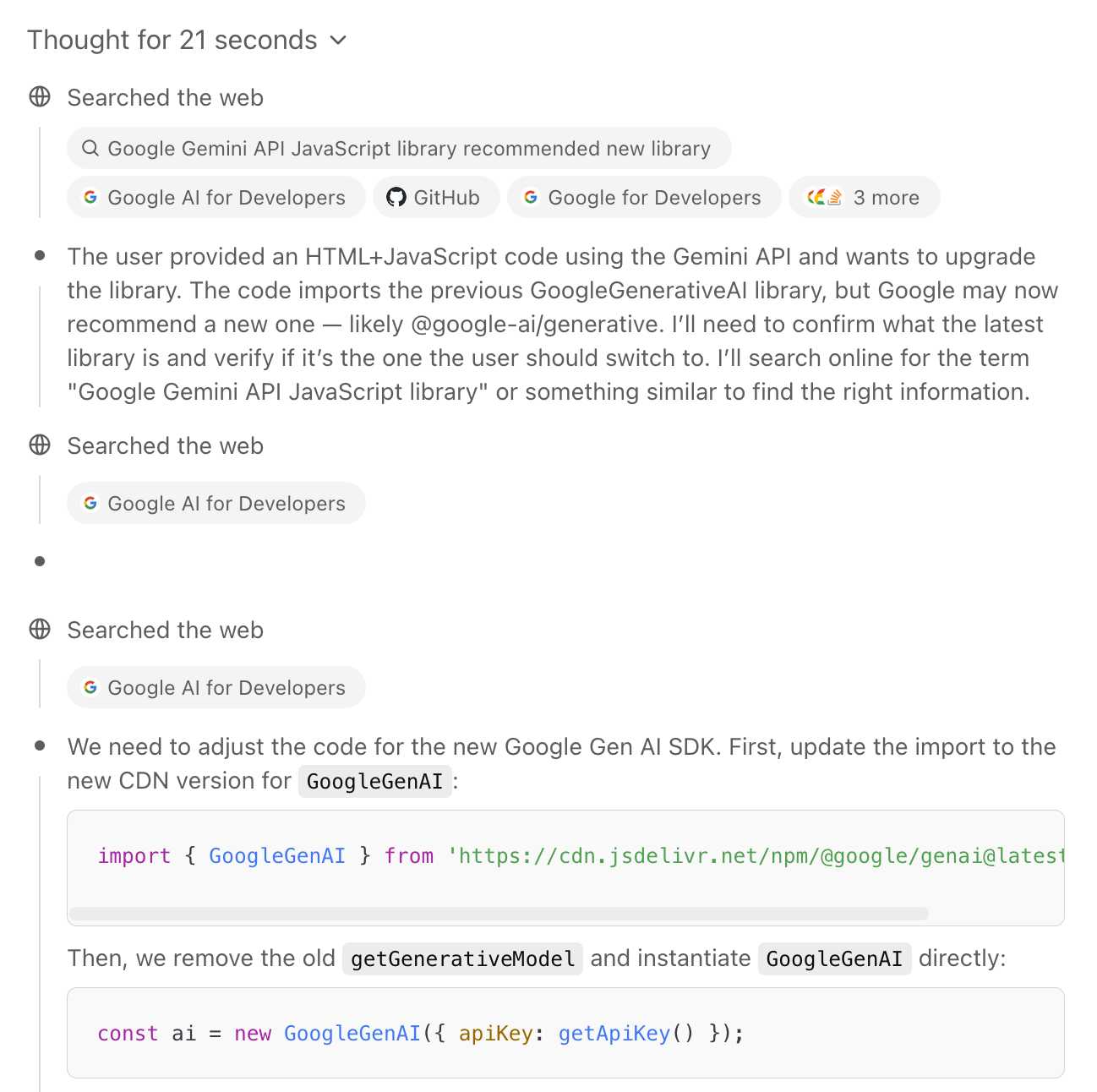
Then gave me detailed instructions along with an updated snippet of code. Here’s the full transcript.
I prompted for a few more changes, then had to tell it not to use TypeScript (since I like copying and pasting code directly out of the tool without needing to run my own build step). The latest version has been rewritten by o4-mini for the new library, defaults to Gemini 2.5 Flash non-thinking and displays usage tokens after each prompt.
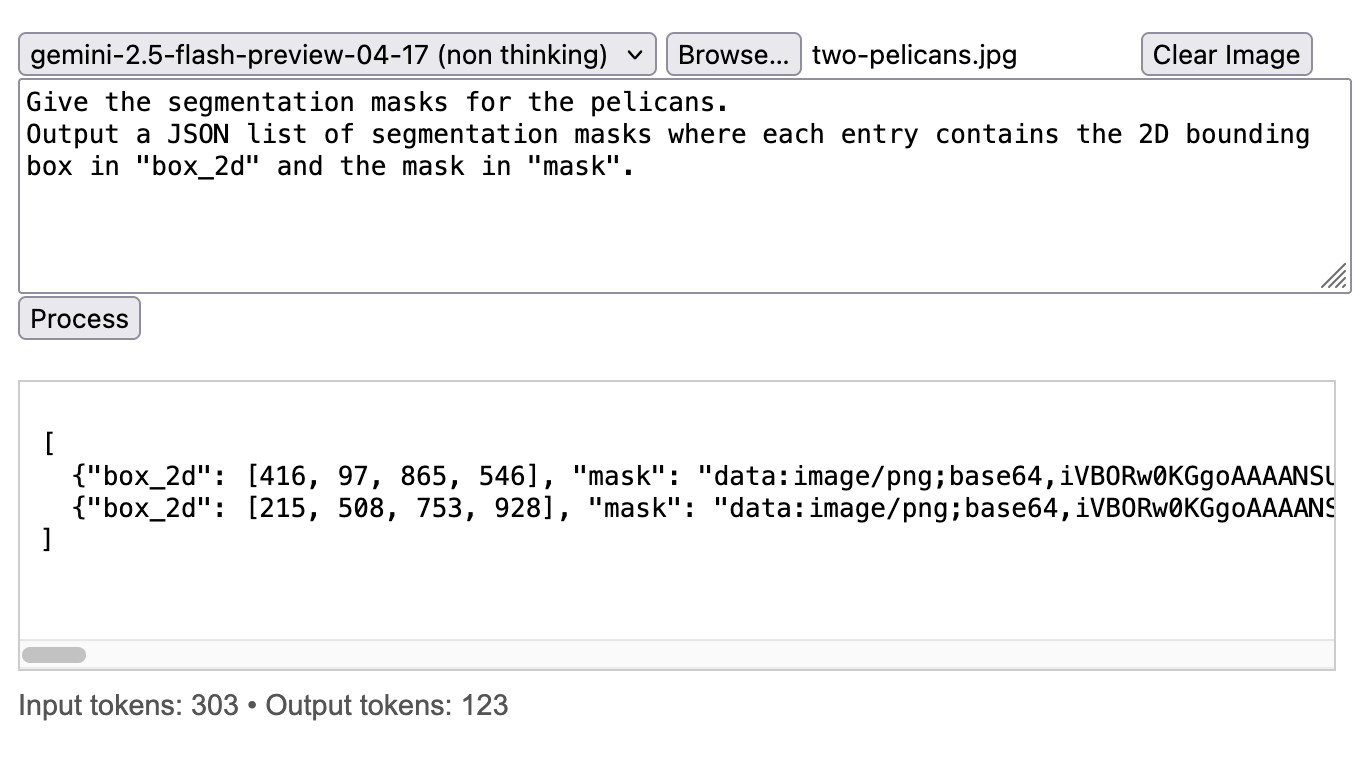
Segmenting my pelican photo in non-thinking mode cost me 303 input tokens and 123 output tokens—that’s 0.0119 cents, just over 1/100th of a cent!
But this looks like way more than 123 output tokens
The JSON that’s returned by the API looks way too long to fit just 123 tokens.
My hunch is that there’s an additional transformation layer here. I think the Gemini 2.5 models return a much more efficient token representation of the image masks, then the Gemini API layer converts those into base4-encoded PNG image strings.
We do have one clue here: last year DeepMind released PaliGemma, an open weights vision model that could generate segmentation masks on demand.
The README for that model includes this note about how their tokenizer works:
PaliGemma uses the Gemma tokenizer with 256,000 tokens, but we further extend its vocabulary with 1024 entries that represent coordinates in normalized image-space (
<loc0000>...<loc1023>), and another with 128 entries (<seg000>...<seg127>) that are codewords used by a lightweight referring-expression segmentation vector-quantized variational auto-encoder (VQ-VAE) [...]
My guess is that Gemini 2.5 is using a similar approach.
Bonus: Image segmentation with LLM and a schema
Since my LLM CLI tool supports JSON schemas we can use those to return the exact JSON shape we want for a given image.
Here’s an example using Gemini 2.5 Flash to return bounding boxes and segmentation masks for all of the objects in an image:
llm -m gemini-2.5-flash-preview-04-17 --schema '{
"type": "object",
"properties": {
"masks": {
"type": "array",
"items": {
"type": "object",
"required": ["box_2d", "mask"],
"properties": {
"box_2d": {
"type": "array",
"items": {
"type": "integer"
}
},
"mask": {
"type": "string"
}
}
}
}
},
"required": ["masks"]
}' -a https://static.simonwillison.net/static/2025/two-pelicans.jpg \
-s 'Return bounding boxes and segmentation masks for all objects'That returned:
{
"masks": [
{"box_2d": [198, 508, 755, 929], "mask": "data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAQAAAAEACAAAAAB5Gfe6AAACfElEQVR42u3ZS27dMBAF0dr/pjsDBwlsB4ZjfZ7IqjvySMQ96EfRFJRSSimlXJX5E3V5o8L8O/L6GoL5Mvb+2wvMN2Lvv6/AfD8BuOvvKDBjBpj/j73/uNtvJDATgFlgDuXdY3TtVx+KuSzy+ksYzB2R138swdybBB6FMC+Lu/0TDOYJcbd/mcE8LfL69xLMY2Pvf4vBPD7q8lca/PhKZwuCHy+/xxgcWHiHn8KxFVffD46vte6eeM4q674Wzlpg1TfjaU9e9HRw4vOWPCGdOk8rnhJft5s8xeB179KHEJx6oDJfHnSH0i3KKpcJCUSQQAJdKl8uMHIA7ZX6Uh8W+rDSl6W+rAUQgLr/VQLTBLQFdAp4ZtGb/hO0Xggv/YWsAdhTIIAA3AAEEIAaAOQCAcgBCCAAt4AdgADcAATgBkAOQAPQAAQgBiAANwByAAKovxkAOQByAOQABOAGaAAaADUAAbgBCMANQABuAAJwAyAHQA5AAG4B5ADIAZADEIAbADkAcgACcAPU3w2AHIAA3ADIAeovF7ADIAcAtwDIBZALsET0ANcREIBbgADcACAXCEAOwOoABGACIICP7Y/uCywK8Psv5qgAawp8pnABvJOwAXz4MegAPu8GYwfA2T+Av9ugFuAN4dguyPoChwDYIwEEEIC6fwAEEIC7fwAByPsHEIAdgADk/QPQA2DvH0AAdgDs/QMIIAA5AAEEIAfA3j+AAAJw9w+AAAIIwA2QQAABdBRqBAIIoJNAAAEkEIC1//cFApALEIBbANQC7B57f+z9vxYAuQB2AewCdgACCMAtEIBdwA4AcgE7AAG4BZADgFoAadzt3wgo5b78AitLcVa+Qqb7AAAAAElFTkSuQmCC"},
{"box_2d": [415, 95, 867, 547], "mask": "data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAQAAAAEACAAAAAB5Gfe6AAADUklEQVR42u3d7W6rMBCE4bn/m54e6VRVpKoQBX/s+p39WVVm58EYQiiVUjXKhsc3V8A/BY9vBYCdPwDJv2SLZfMTAVbnr3ageTFAtZXGSwHqLbVeCVDwXOOFAO6Q38csNZ8CfPfnzkfa8/zjW+y1/8c32W//j22yY37P2lLZK6B5ADWP/7v8Pjz+bX4fffhvy+8qLl4D8Pegu+fFGoCLMcvn99z8uz8Ybc9ffQX0hG0kPyp/5fn/zgr4tOfrYd0j/wOBm0GPB7C96kJzav5Pu7wbdCuAPRtg/gJTG+B+9///He1ZCzwbwG/N/22TYX9+7T0eJgP48zohv10dYGpP9mkAyc/O75X5uwP4xPxeF7/mKfDtzjyiiuZ/ozGbDWB3EZjTmOEAgPxXrblR/hkArfLP+JzaKf6ED6qNwk8BaJX+abuT8he+E3rbabf8gu9/1dv/tb8LuOkVlt/98w+dAKbld+ez//D7tcnPOwD+frSVMgEMPwBeW4YDmJr/+1EWcH43u/cz67Zd8gMvATIBmufPChCAHAEBCEAAuPkDEIAABIANoADQAYQHUADoAIUIAhABuoDoAqILiC4QALqA6AKiC4guEAC6gOgCyhSAC0hwgQDQBUQXCABdQHSBAEQgAHCBANAFRBcIAF0gAAGAC4guQAeQ4AIBCABcIAB0gQDQBQIQgACwBQIQALgAHUABCABbIABwAQUADSCxASS2gNAAql54ANHzKzMgABEIQAACEIBcCAQAAfCvIS8FqLyrVwiUnugogMsGz89/2aPPB/CugsfPOxPy3hR4/Lw+LC+Qg8fPa0TzJl14fOed+vm/GvD4qwFcrwLAjr8SwOj8rlr0/GanXwJgowFsNoDZADYawEYD2GwAswFsNICNBrDRADYawB0LHn+cgPsWPP4IArcvdvpHAj6m6Pk/IniwqRMIHm2k/zx4OnxzgOeDt14PhozZdl0cNVDTk8O42dTzDDnwUGp5kbB/IWkDcOjNswpXElsFSlxK7hT4/TOTPki/9pxbyESBAORrpADki1QwQZ4lycNUXALsk/RL/5wAsJsrE6hMsdPvEFDBgsdfSKC6BY+/wED1Cx7/l8E4G51R8Pifaujsgse/QRCo4PFfJcYO9wWdFFckoSpT7wAAAABJRU5ErkJggg=="}
]
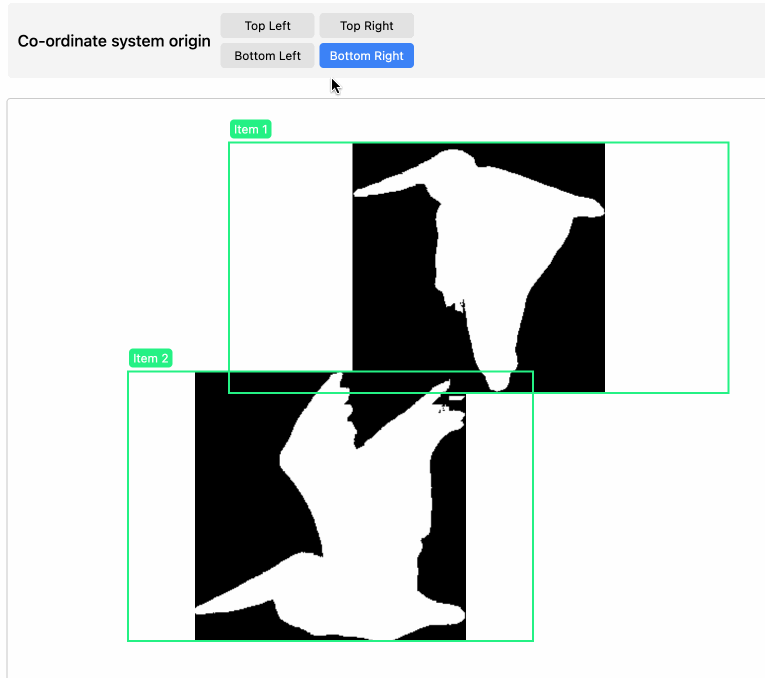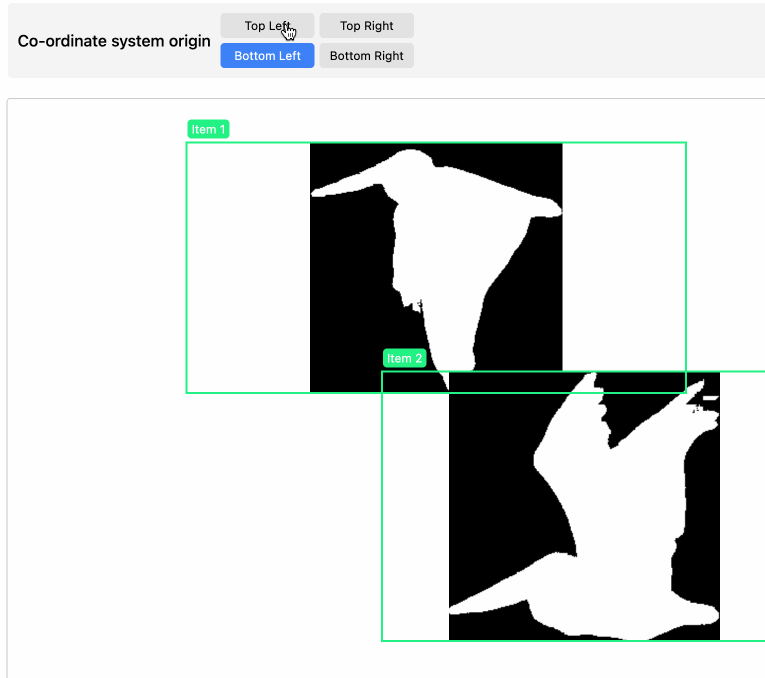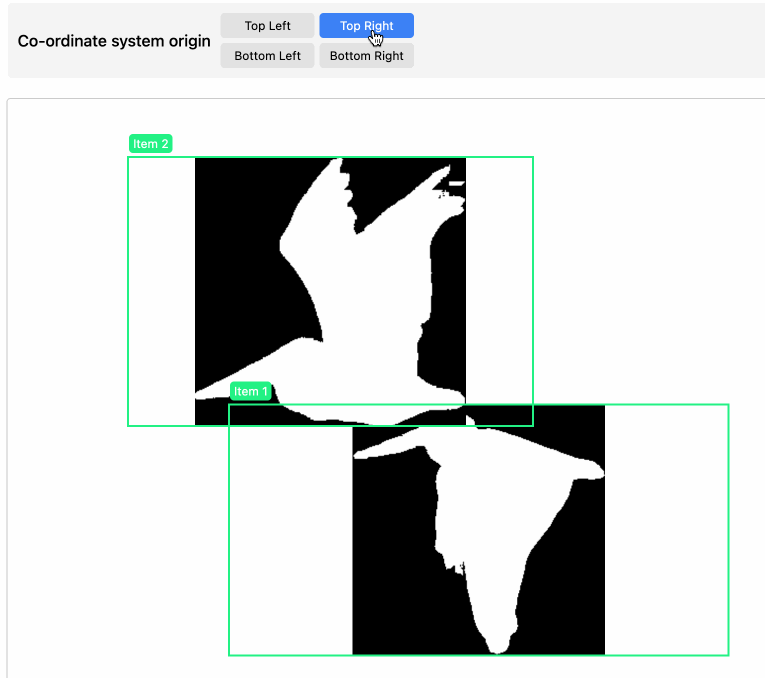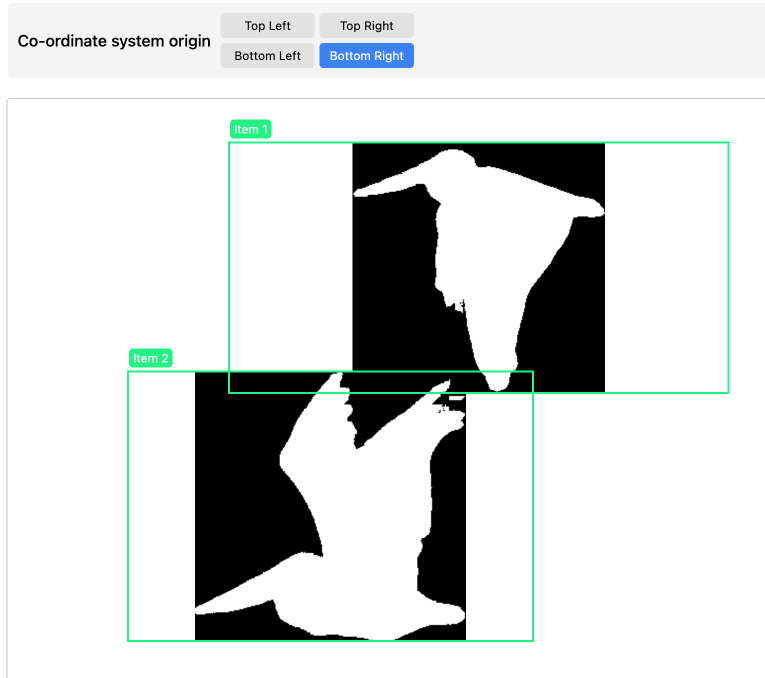
}I vibe coded a tool for visualizing that JSON—paste it into tools.simonwillison.net/mask-visualizer to see the results.
I wasn’t sure of the origin for the co-ordinate system when I first built the tool so I had Claude add buttons for switching that to see which one fit. Then I left the buttons in because you can use them to make my pelican outlines flap around the page!
More recent articles
- Mr. Chatterbox is a (weak) Victorian-era ethically trained model you can run on your own computer - 30th March 2026
- Vibe coding SwiftUI apps is a lot of fun - 27th March 2026
- Experimenting with Starlette 1.0 with Claude skills - 22nd March 2026