23rd October 2024 - Link Blog
Running prompts against images and PDFs with Google Gemini. New TIL. I've been experimenting with the Google Gemini APIs for running prompts against images and PDFs (in preparation for finally adding multi-modal support to LLM) - here are my notes on how to send images or PDF files to their API using curl and the base64 -i macOS command.
I figured out the curl incantation first and then got Claude to build me a Bash script that I can execute like this:
prompt-gemini 'extract text' example-handwriting.jpg
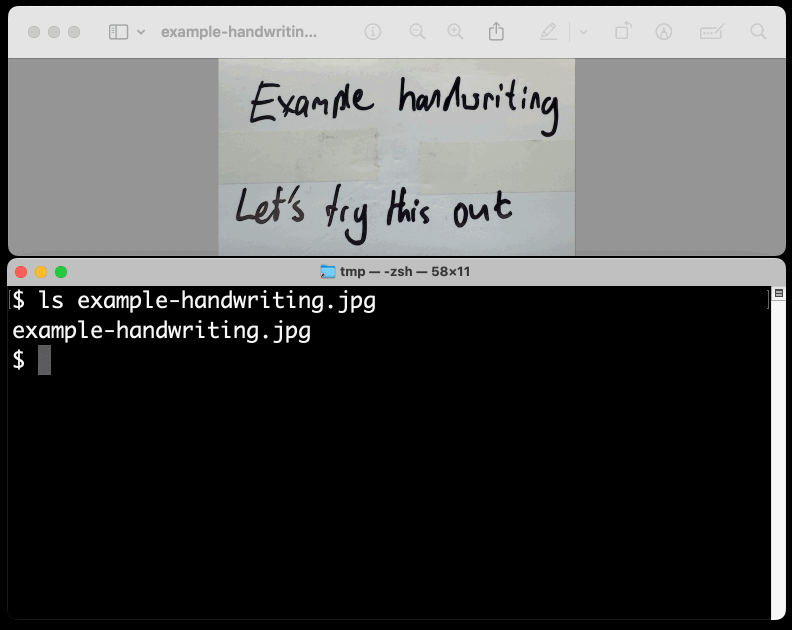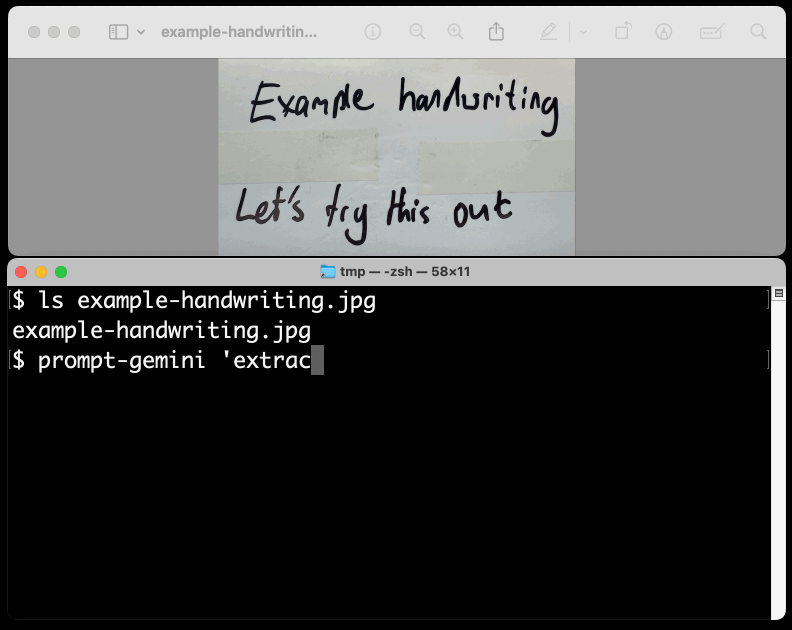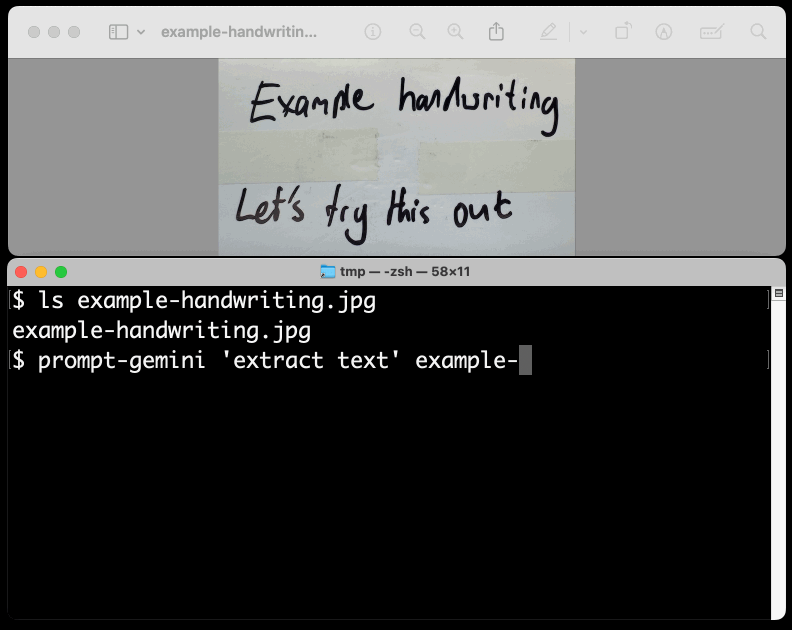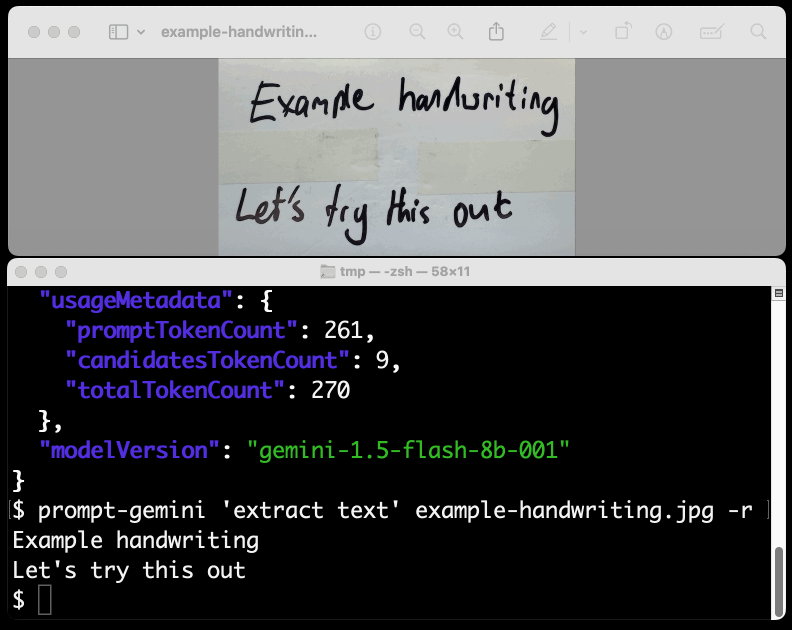
Playing with this is really fun. The Gemini models charge less than 1/10th of a cent per image, so it's really inexpensive to try them out.
Recent articles
- Meta's new model is Muse Spark, and meta.ai chat has some interesting tools - 8th April 2026
- Anthropic's Project Glasswing - restricting Claude Mythos to security researchers - sounds necessary to me - 7th April 2026
- The Axios supply chain attack used individually targeted social engineering - 3rd April 2026