Claude and ChatGPT for ad-hoc sidequests
22nd March 2024
Here is a short, illustrative example of one of the ways in which I use Claude and ChatGPT on a daily basis.
I recently learned that the Adirondack Park is the single largest park in the contiguous United States, taking up a fifth of the state of New York.
Naturally, my first thought was that it would be neat to have a GeoJSON file representing the boundary of the park.
A quick search landed me on the Adirondack Park Agency GIS data page, which offered me a shapefile of the “Outer boundary of the New York State Adirondack Park as described in Section 9-0101 of the New York Environmental Conservation Law”. Sounds good!
I knew there were tools for converting shapefiles to GeoJSON, but I couldn’t remember what they were. Since I had a terminal window open already, I typed the following:
llm -m opus -c 'give me options on macOS for CLI tools to turn a shapefile into GeoJSON'Here I am using my LLM tool (and llm-claude-3 plugin) to run a prompt through the new Claude 3 Opus, my current favorite language model.
It replied with a couple of options, but the first was this:
ogr2ogr -f GeoJSON output.geojson input.shpSo I ran that against the shapefile, and then pasted the resulting GeoJSON into geojson.io to check if it worked... and nothing displayed. Then I looked at the GeoJSON and spotted this:
"coordinates": [ [ -8358911.527799999341369, 5379193.197800002992153 ] ...
That didn’t look right. Those co-ordinates aren’t the correct scale for latitude and longitude values.
So I sent a follow-up prompt to the model (the -c option means “continue previous conversation”):
llm -c 'i tried using ogr2ogr but it gave me back GeoJSON with a weird coordinate system that was not lat/lon that i am used to'It suggested this new command:
ogr2ogr -f GeoJSON -t_srs EPSG:4326 output.geojson input.shpThis time it worked! The shapefile has now been converted to GeoJSON.
Time elapsed so far: 2.5 minutes (I can tell from my LLM logs).
I pasted it into Datasette (with datasette-paste and datasette-leaflet-geojson) to take a look at it more closely, and got this:
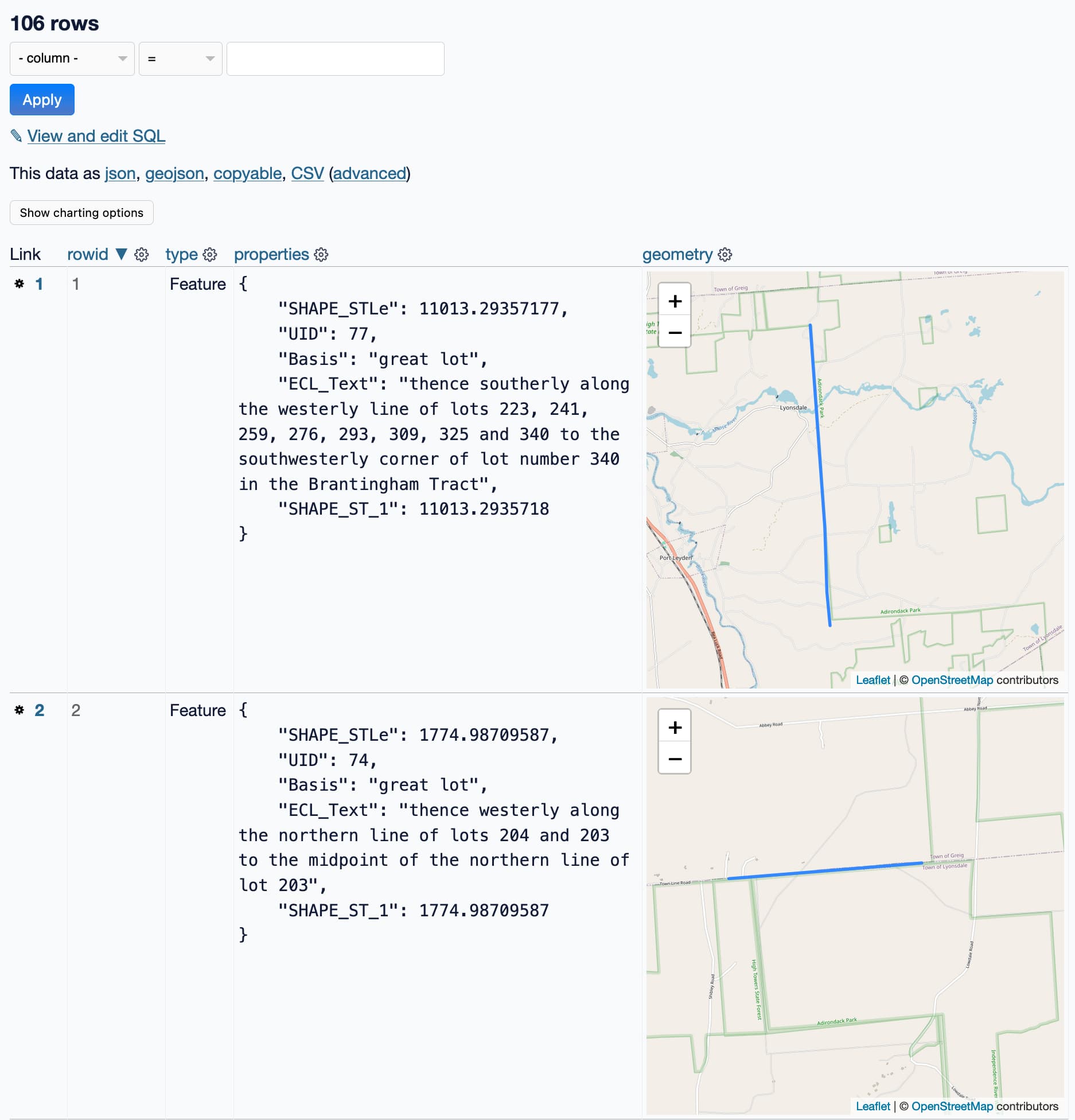
That’s not a single polygon! That’s 106 line segments... and they are fascinating. Look at those descriptions:
thence westerly along the northern line of lots 204 and 203 to the midpoint of the northern line of lot 203
This is utterly delightful. The shapefile description did say “as described in Section 9-0101 of the New York Environmental Conservation Law”, so I guess this is how you write geographically boundaries into law!
But it’s not what I wanted. I want a single polygon of the whole park, not 106 separate lines.
I decided to switch models. ChatGPT has access to Code Interpreter, and I happen to know that Code Interpreter is quite effective at processing GeoJSON.
I opened a new ChatGPT (with GPT-4) browser tab, uploaded my GeoJSON file and prompted it:
This GeoJSON file is full of line segments. Use them to create me a single shape that is a Polygon
OK, so it wrote some Python code and ran it. But did it work?
I happen to know that Code Interpreter can save files to disk and provide links to download them, so I told it to do that:
Save it to a GeoJSON file for me to download
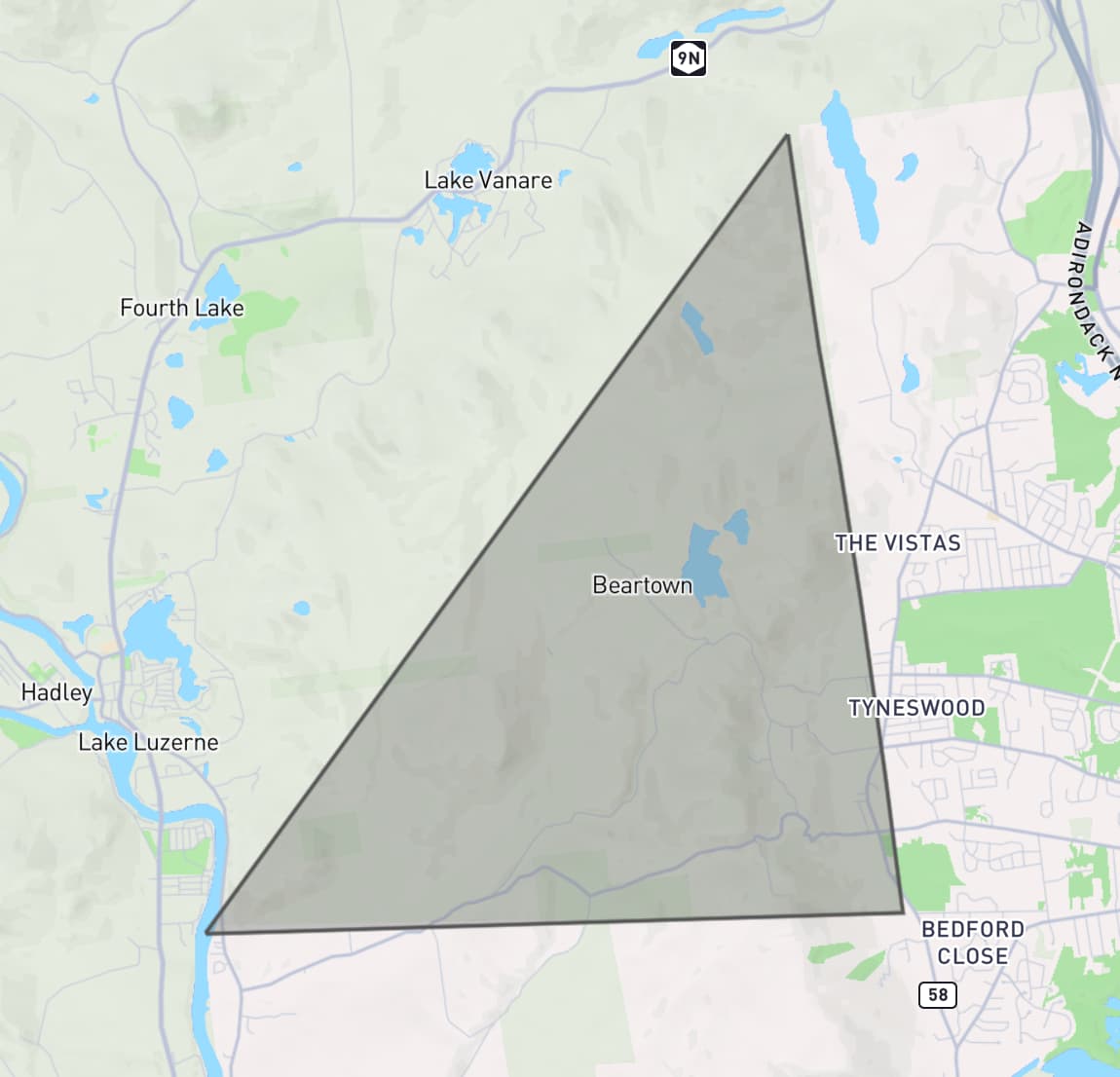
I pasted that into geojson.io, and it was clearly wrong:
So I told it to try again. I didn’t think very hard about this prompt, I basically went with a version of “do better”:
that doesn’t look right to me, check that it has all of the lines in it
It gave me a new file, optimistically named complete_polygon.geojson. Here’s what that one looked like:
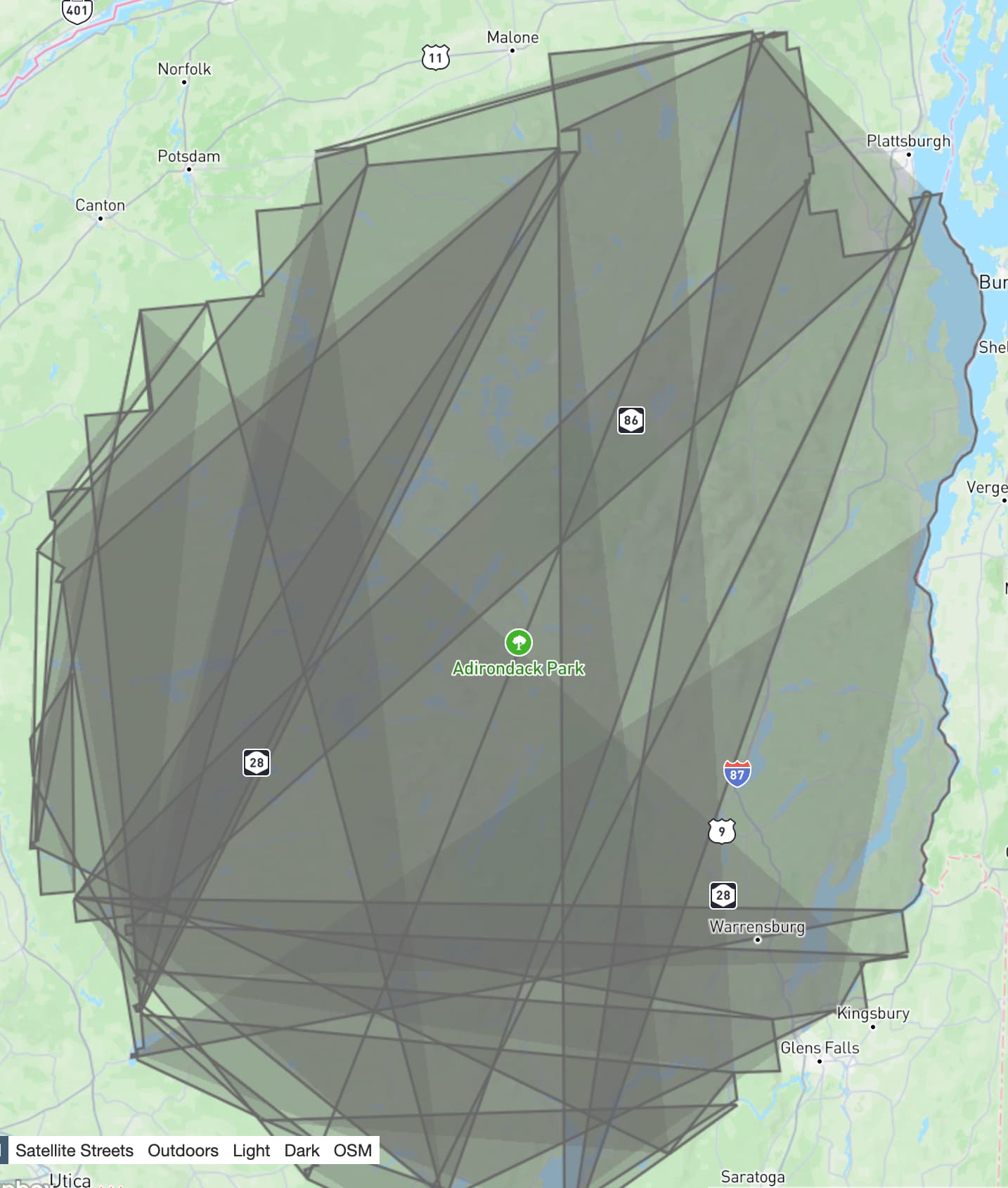
This is getting a lot closer! Note how the right hand boundary of the park looks correct, but the rest of the image is scrambled.
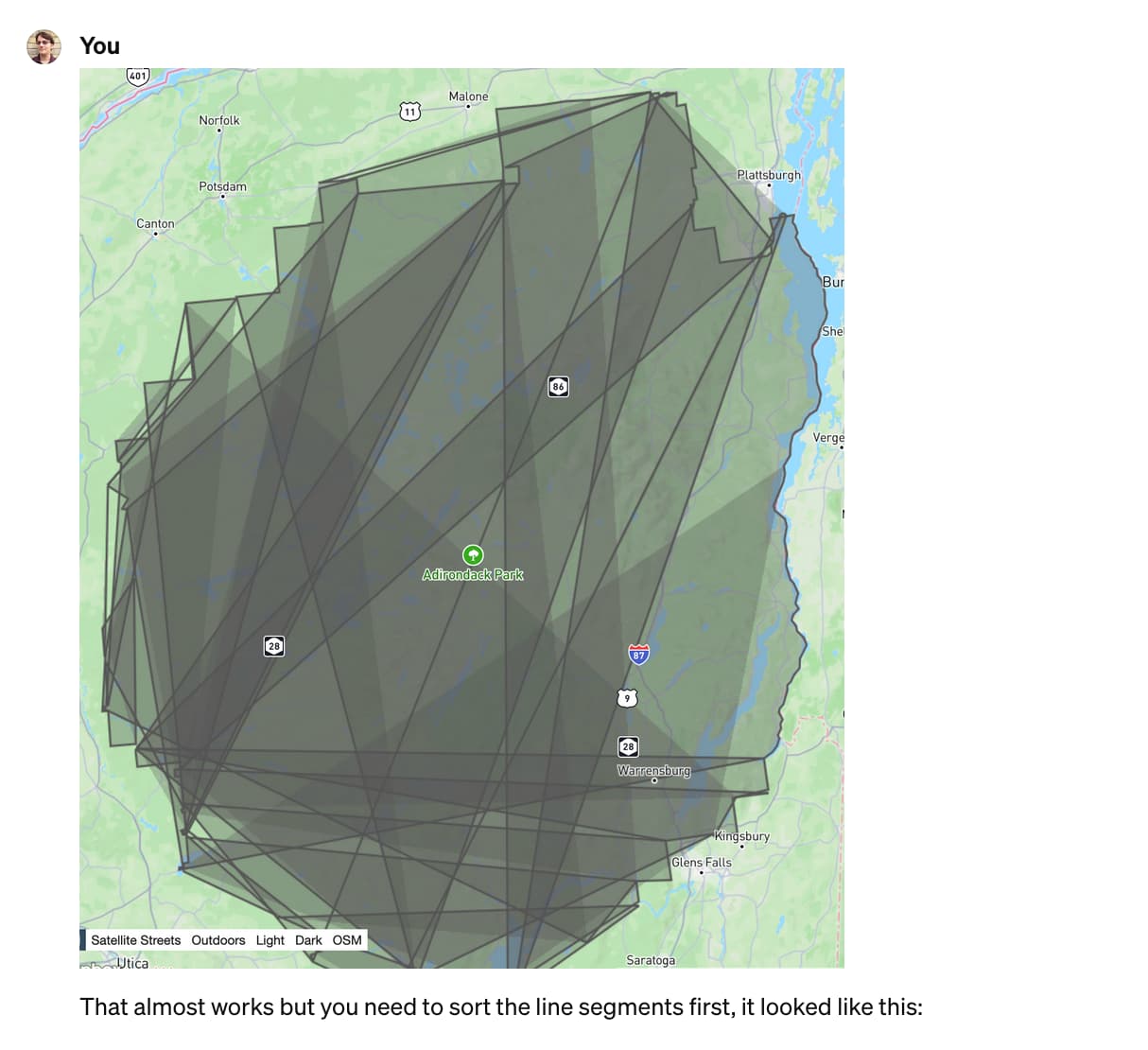
I had a hunch about the fix. I pasted in a screenshot of where we were so far and added my hunch about the solution:
That almost works but you need to sort the line segments first, it looked like this:
Honestly, pasting in the screenshot probably wasn’t necessary here, but it amused me.
... and ChatGPT churned away again ...
sorted_polygon.geojson is spot on! Here’s what it looks like:
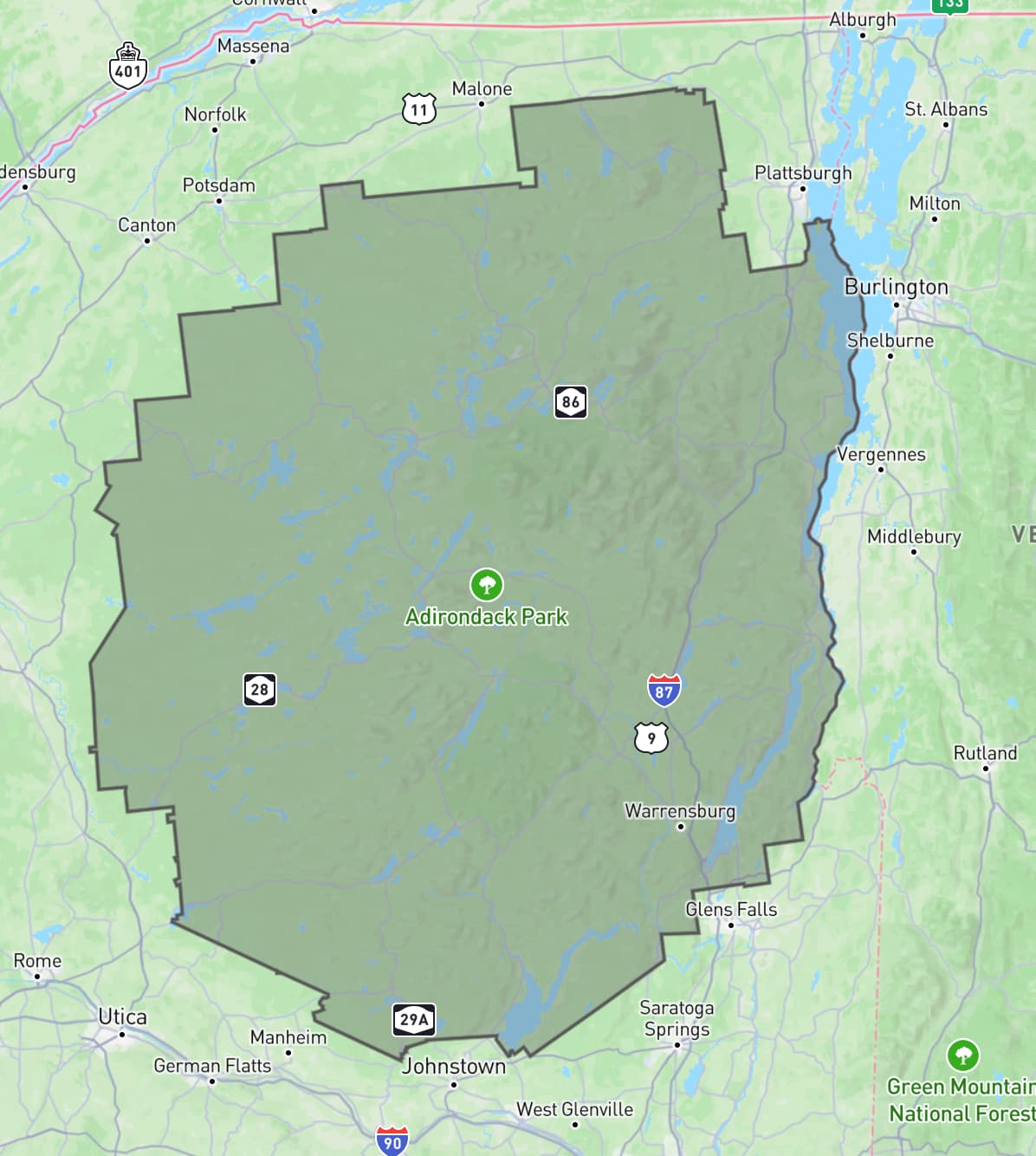
Total time spent in ChatGPT: 3 minutes and 35 seconds. Plus 2.5 minutes with Claude 3 earlier, so an overall total of just over 6 minutes.
Here’s the full Claude transcript and the full transcript from ChatGPT.
This isn’t notable
The most notable thing about this example is how completely not notable it is.
I get results like this from these tools several times a day. I’m not at all surprised that this worked, in fact, I would’ve been mildly surprised if it had not.
Could I have done this without LLM assistance? Yes, but not nearly as quickly. And this was not a task on my critical path for the day—it was a sidequest at best and honestly more of a distraction.
So, without LLM tools, I would likely have given this one up at the first hurdle.
A year ago I wrote about how AI-enhanced development makes me more ambitious with my projects. They are now so firmly baked into my daily work that they influence not just side projects but tiny sidequests like this one as well.
This certainly wasn’t simple
Something else I like about this example is that it illustrates quite how much depth there is to getting great results out of these systems.
In those few minutes I used two different interfaces to call two different models. I sent multiple follow-up prompts. I triggered Code Interpreter, took advantage of GPT-4 Vision and mixed in external tools like geojson.io and Datasette as well.
I leaned a lot on my existing knowledge and experience:
- I knew that tools existed for commandline processing of shapefiles and GeoJSON
- I instinctively knew that Claude 3 Opus was likely to correctly answer my initial prompt
- I knew the capabilities of Code Interpreter, including that it has libraries that can process geometries, what to say to get it to kick into action and how to get it to give me files to download
- My limited GIS knowledge was strong enough to spot a likely coordinate system problem, and I guessed the fix for the jumbled lines
- My prompting intuition is developed to the point that I didn’t have to think very hard about what to say to get the best results
If you have the right combination of domain knowledge and hard-won experience driving LLMs, you can fly with these things.
Isn’t this a bit trivial?
Yes it is, and that’s the point. This was a five minute sidequest. Writing about it here took ten times longer than the exercise itself.
I take on LLM-assisted sidequests like this one dozens of times a week. Many of them are substantially larger and more useful. They are having a very material impact on my work: I can get more done and solve much more interesting problems, because I’m not wasting valuable cycles figuring out ogr2ogr invocations or mucking around with polygon libraries.
Not to mention that I find working this way fun! It feels like science fiction every time I do it. Our AI-assisted future is here right now and I’m still finding it weird, fascinating and deeply entertaining.
LLMs are useful
There are many legitimate criticisms of LLMs. The copyright issues involved in their training, their enormous power consumption and the risks of people trusting them when they shouldn’t (considering both accuracy and bias) are three that I think about a lot.
The one criticism I wont accept is that they aren’t useful.
One of the greatest misconceptions concerning LLMs is the idea that they are easy to use. They really aren’t: getting great results out of them requires a great deal of experience and hard-fought intuition, combined with deep domain knowledge of the problem you are applying them to.
I use these things every day. They help me take on much more interesting and ambitious problems than I could otherwise. I would miss them terribly if they were no longer available to me.
More recent articles
- Anthropic's Project Glasswing - restricting Claude Mythos to security researchers - sounds necessary to me - 7th April 2026
- The Axios supply chain attack used individually targeted social engineering - 3rd April 2026
- Highlights from my conversation about agentic engineering on Lenny's Podcast - 2nd April 2026