4 posts tagged “justine-tunney”
2024
llamafile v0.8.13 (and whisperfile)
(via)
The latest release of llamafile (previously) adds support for Gemma 2B (pre-bundled llamafiles available here), significant performance improvements and new support for the Whisper speech-to-text model, based on whisper.cpp, Georgi Gerganov's C++ implementation of Whisper that pre-dates his work on llama.cpp.
I got whisperfile working locally by first downloading the cross-platform executable attached to the GitHub release and then grabbing a whisper-tiny.en-q5_1.bin model from Hugging Face:
wget -O whisper-tiny.en-q5_1.bin \
https://huggingface.co/ggerganov/whisper.cpp/resolve/main/ggml-tiny.en-q5_1.bin
Then I ran chmod 755 whisperfile-0.8.13 and then executed it against an example .wav file like this:
./whisperfile-0.8.13 -m whisper-tiny.en-q5_1.bin -f raven_poe_64kb.wav --no-prints
The --no-prints option suppresses the debug output, so you just get text that looks like this:
[00:00:00.000 --> 00:00:12.000] This is a LibraVox recording. All LibraVox recordings are in the public domain. For more information please visit LibraVox.org.
[00:00:12.000 --> 00:00:20.000] Today's reading The Raven by Edgar Allan Poe, read by Chris Scurringe.
[00:00:20.000 --> 00:00:40.000] Once upon a midnight dreary, while I pondered weak and weary, over many a quaint and curious volume of forgotten lore. While I nodded nearly napping, suddenly there came a tapping as of someone gently rapping, rapping at my chamber door.
There are quite a few undocumented options - to write out JSON to a file called transcript.json (example output):
./whisperfile-0.8.13 -m whisper-tiny.en-q5_1.bin -f /tmp/raven_poe_64kb.wav --no-prints --output-json --output-file transcript
I had to convert my own audio recordings to 16kHz .wav files in order to use them with whisperfile. I used ffmpeg to do this:
ffmpeg -i runthrough-26-oct-2023.wav -ar 16000 /tmp/out.wav
Then I could transcribe that like so:
./whisperfile-0.8.13 -m whisper-tiny.en-q5_1.bin -f /tmp/out.wav --no-prints
Update: Justine says:
I've just uploaded new whisperfiles to Hugging Face which use miniaudio.h to automatically resample and convert your mp3/ogg/flac/wav files to the appropriate format.
With that whisper-tiny model this took just 11s to transcribe a 10m41s audio file!
I also tried the much larger Whisper Medium model - I chose to use the 539MB ggml-medium-q5_0.bin quantized version of that from huggingface.co/ggerganov/whisper.cpp:
./whisperfile-0.8.13 -m ggml-medium-q5_0.bin -f out.wav --no-prints
This time it took 1m49s, using 761% of CPU according to Activity Monitor.
I tried adding --gpu auto to exercise the GPU on my M2 Max MacBook Pro:
./whisperfile-0.8.13 -m ggml-medium-q5_0.bin -f out.wav --no-prints --gpu auto
That used just 16.9% of CPU and 93% of GPU according to Activity Monitor, and finished in 1m08s.
I tried this with the tiny model too but the performance difference there was imperceptible.
gemma-2-27b-it-llamafile (via) Justine Tunney shipped llamafile packages of Google's new openly licensed (though definitely not open source) Gemma 2 27b model this morning.
I downloaded the gemma-2-27b-it.Q5_1.llamafile version (20.5GB) to my Mac, ran chmod 755 gemma-2-27b-it.Q5_1.llamafile and then ./gemma-2-27b-it.Q5_1.llamafile and now I'm trying it out through the llama.cpp default web UI in my browser. It works great.
It's a very capable model - currently sitting at position 12 on the LMSYS Arena making it the highest ranked open weights model - one position ahead of Llama-3-70b-Instruct and within striking distance of the GPT-4 class models.
2023
llamafile is the new best way to run an LLM on your own computer
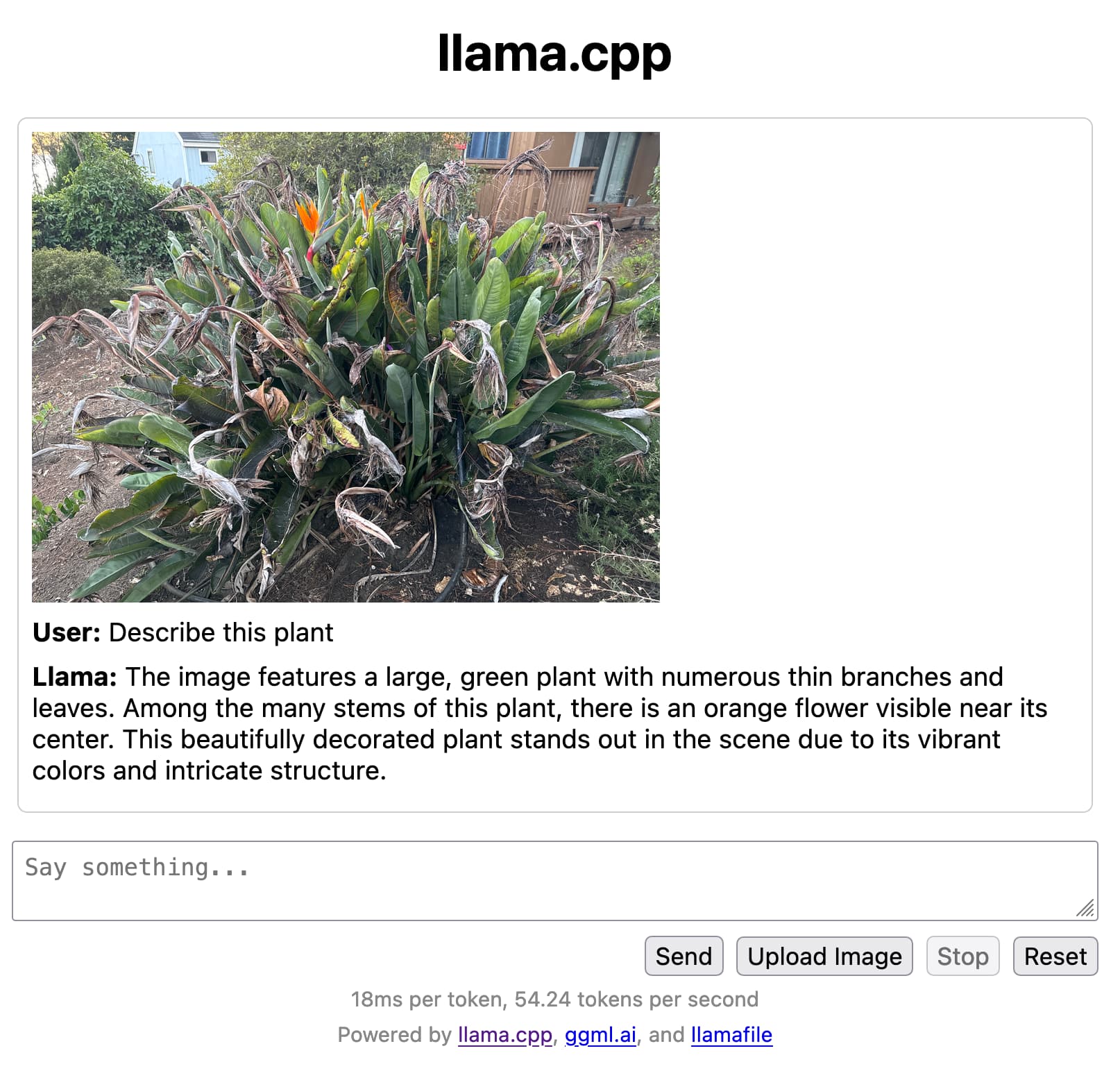
Mozilla’s innovation group and Justine Tunney just released llamafile, and I think it’s now the single best way to get started running Large Language Models (think your own local copy of ChatGPT) on your own computer.
[... 650 words]2022
Cosmopolitan: Compiling Python. Cosmopolitan is Justine Tunney’s “build-once run-anywhere C library”—part of the αcτµαlly pδrταblε εxεcµταblε effort, which produces wildly clever binary executable files that work on multiple different platforms, and is the secret sauce behind redbean. I hadn’t realized this was happening but there’s an active project to get Python to work as this format, producing a new way of running Python applications as standalone executables, only these ones have the potential to run unmodified on Windows, Linux and macOS.