11 posts tagged “digital-literacy”
2025
Is the LLM response wrong, or have you just failed to iterate it? (via) More from Mike Caulfield (see also the SIFT method). He starts with a fantastic example of Google's AI mode usually correctly handling a common piece of misinformation but occasionally falling for it (the curse of non-deterministic systems), then shows an example if what he calls a "sorting prompt" as a follow-up:
What is the evidence for and against this being a real photo of Shirley Slade?
The response starts with a non-committal "there is compelling evidence for and against...", then by the end has firmly convinced itself that the photo is indeed a fake. It reads like a fact-checking variant of "think step by step".
Mike neatly describes a problem I've also observed recently where "hallucination" is frequently mis-applied as meaning any time a model makes a mistake:
The term hallucination has become nearly worthless in the LLM discourse. It initially described a very weird, mostly non-humanlike behavior where LLMs would make up things out of whole cloth that did not seem to exist as claims referenced any known source material or claims inferable from any known source material. Hallucinations as stuff made up out of nothing. Subsequently people began calling any error or imperfect summary a hallucination, rendering the term worthless.
In this example is the initial incorrect answers were not hallucinations: they correctly summarized online content that contained misinformation. The trick then is to encourage the model to look further, using "sorting prompts" like these:
- Facts and misconceptions and hype about what I posted
- What is the evidence for and against the claim I posted
- Look at the most recent information on this issue, summarize how it shifts the analysis (if at all), and provide link to the latest info
I appreciated this closing footnote:
Should platforms have more features to nudge users to this sort of iteration? Yes. They should. Getting people to iterate investigation rather than argue with LLMs would be a good first step out of this mess that the chatbot model has created.
The SIFT method (via) The SIFT method is "an evaluation strategy developed by digital literacy expert, Mike Caulfield, to help determine whether online content can be trusted for credible or reliable sources of information."
This looks extremely useful as a framework for helping people more effectively consume information online (increasingly gathered with the help of LLMs).
- Stop. "Be aware of your emotional response to the headline or information in the article" to protect against clickbait, and don't read further or share until you've applied the other three steps.
- Investigate the Source. Apply lateral reading, checking what others say about the source rather than just trusting their "about" page.
- Find Better Coverage. "Use lateral reading to see if you can find other sources corroborating the same information or disputing it" and consult trusted fact checkers if necessary.
- Trace Claims, Quotes, and Media to their Original Context. Try to find the original report or referenced material to learn more and check it isn't being represented out of context.
This framework really resonates with me: it formally captures and improves on a bunch of informal techniques I've tried to apply in my own work.
Tips on prompting ChatGPT for UK technology secretary Peter Kyle
Back in March New Scientist reported on a successful Freedom of Information request they had filed requesting UK Secretary of State for Science, Innovation and Technology Peter Kyle’s ChatGPT logs:
[... 1,189 words]I still don’t think companies serve you ads based on spying through your microphone
One of my weirder hobbies is trying to convince people that the idea that companies are listening to you through your phone’s microphone and serving you targeted ads is a conspiracy theory that isn’t true. I wrote about this previously: Facebook don’t spy on you through your microphone.
[... 698 words]2024
Project: VERDAD—tracking misinformation in radio broadcasts using Gemini 1.5
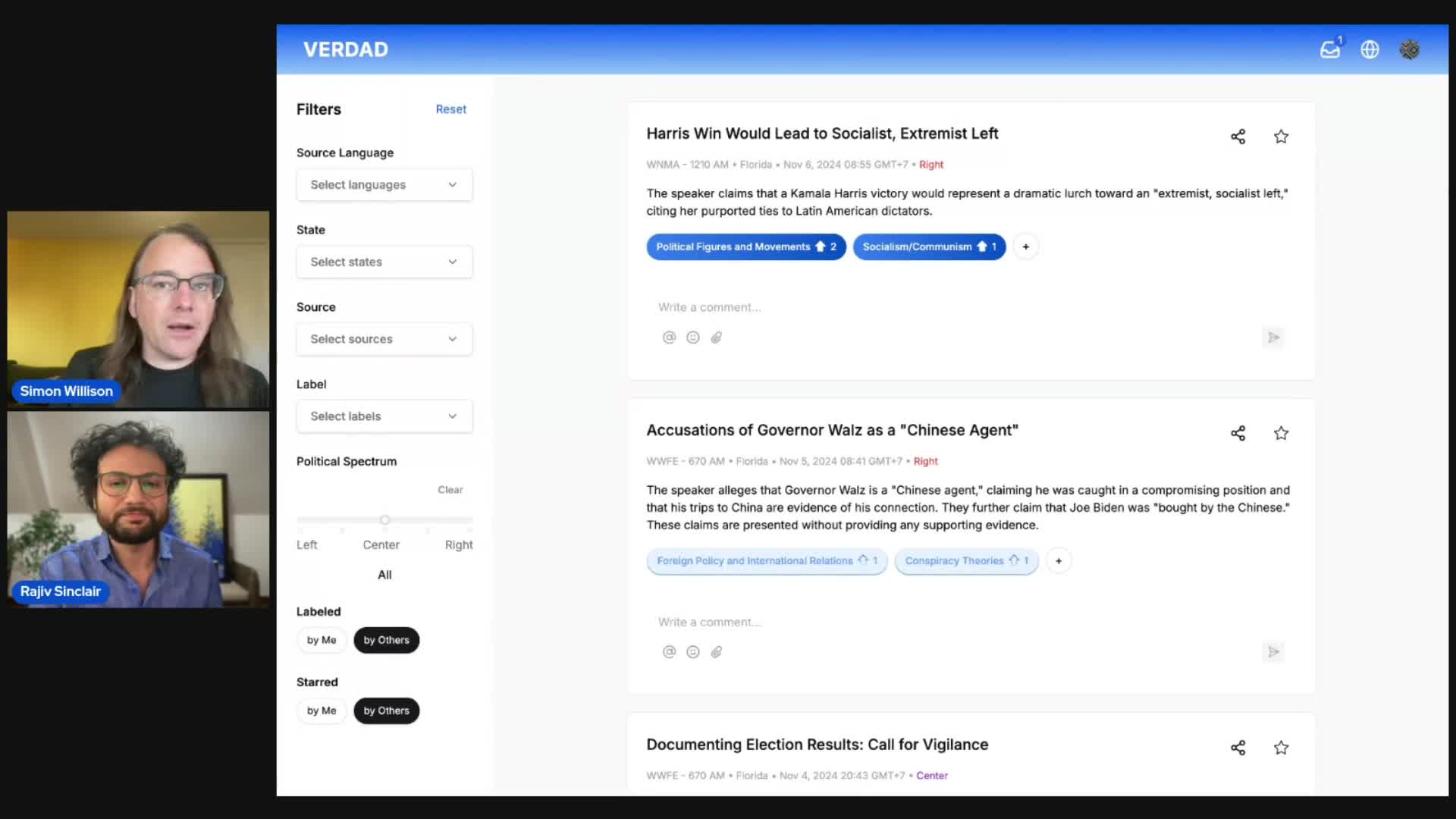
I’m starting a new interview series called Project. The idea is to interview people who are building interesting data projects and talk about what they’ve built, how they built it, and what they learned along the way.
[... 1,025 words]The primary use of “misinformation” is not to change the beliefs of other people at all. Instead, the vast majority of misinformation is offered as a service for people to maintain their beliefs in face of overwhelming evidence to the contrary.
— Mike Caulfield, via Charlie Warzel
2023
The AI trust crisis
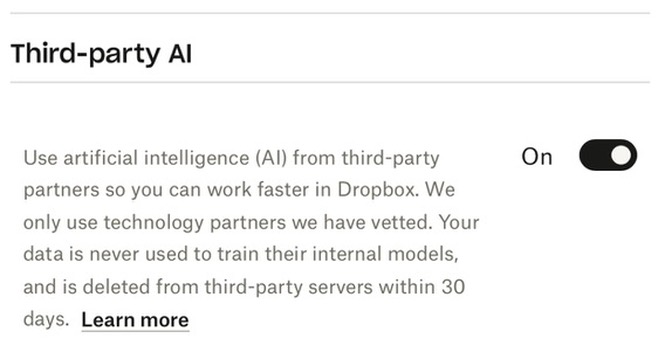
Dropbox added some new AI features. In the past couple of days these have attracted a firestorm of criticism. Benj Edwards rounds it up in Dropbox spooks users with new AI features that send data to OpenAI when used.
[... 1,733 words]Can We Trust Search Engines with Generative AI? A Closer Look at Bing’s Accuracy for News Queries (via) Computational journalism professor Nick Diakopoulos takes a deeper dive into the quality of the summarizations provided by AI-assisted Bing. His findings are troubling: for news queries, which are a great test for AI summarization since they include recent information that may have sparse or conflicting stories, Bing confidently produces answers with important errors: claiming the Ohio train derailment happened on February 9th when it actually happened on February 3rd for example.
2020
Seniors generally report having more trust in the people around them, a characteristic that may make them more credulous of information that comes from friends and family. There is also the issue of context: Misinformation appears in a stream that also includes baby pictures, recipes and career updates. Users may not expect to toggle between light socializing and heavy truth-assessing when they’re looking at their phone for a few minutes in line at the grocery store.
I’ve often joked with other internet culture reporters about what I call the “normie tipping point.” In every emerging internet trend, there is a point at which “normies” — people who don’t spend all day online, and whose brains aren’t rotted by internet garbage — start calling, texting and emailing us to ask what’s going on. Why are kids eating Tide Pods? What is the Momo Challenge? Who is Logan Paul, and why did he film himself with a dead body?
The normie tipping point is a joke, but it speaks to one of the thorniest questions in modern journalism, specifically on this beat: When does the benefit of informing people about an emerging piece of misinformation outweigh the possible harms?
2017
This Is What Happens When Millions Of People Suddenly Get The Internet (via) “Countries which come online quickly rank lowest in digital literacy & are most likely to fall for scams, fake news”