25 posts tagged “software-architecture”
2026
Serving the For You feed. One of Bluesky's most interesting features is that anyone can run their own custom "feed" implementation and make it available to other users - effectively enabling custom algorithms that can use any mechanism they like to recommend posts.
spacecowboy runs the For You Feed, used by around 72,000 people. This guest post on the AT Protocol blog explains how it works.
The architecture is fascinating. The feed is served by a single Go process using SQLite on a "gaming" PC in spacecowboy's living room - 16 cores, 96GB of RAM and 4TB of attached NVMe storage.
Recommendations are based on likes: what else are the people who like the same things as you liking on the platform?
That Go server consumes the Bluesky firehose and stores the relevant details in SQLite, keeping the last 90 days of relevant data, which currently uses around 419GB of SQLite storage.
Public internet traffic is handled by a $7/month VPS on OVH, which talks to the living room server via Tailscale.
Total cost is now $30/month: $20 in electricity, $7 in VPS and $3 for the two domain names. spacecowboy estimates that the existing system could handle all ~1 million daily active Bluesky users if they were to switch to the cheapest algorithm they have found to work.
The Design & Implementation of Sprites (via) I wrote about Sprites last week. Here's Thomas Ptacek from Fly with the insider details on how they work under the hood.
I like this framing of them as "disposable computers":
Sprites are ball-point disposable computers. Whatever mark you mean to make, we’ve rigged it so you’re never more than a second or two away from having a Sprite to do it with.
I've noticed that new Fly Machines can take a while (up to around a minute) to provision. Sprites solve that by keeping warm pools of unused machines in multiple regions, which is enabled by them all using the same container:
Now, today, under the hood, Sprites are still Fly Machines. But they all run from a standard container. Every physical worker knows exactly what container the next Sprite is going to start with, so it’s easy for us to keep pools of “empty” Sprites standing by. The result: a Sprite create doesn’t have any heavy lifting to do; it’s basically just doing the stuff we do when we start a Fly Machine.
The most interesting detail is how the persistence layer works. Sprites only charge you for data you have written that differs from the base image and provide ~300ms checkpointing and restores - it turns out that's power by a custom filesystem on top of S3-compatible storage coordinated by Litestream-replicated local SQLite metadata:
We still exploit NVMe, but not as the root of storage. Instead, it’s a read-through cache for a blob on object storage. S3-compatible object stores are the most trustworthy storage technology we have. I can feel my blood pressure dropping just typing the words “Sprites are backed by object storage.” [...]
The Sprite storage stack is organized around the JuiceFS model (in fact, we currently use a very hacked-up JuiceFS, with a rewritten SQLite metadata backend). It works by splitting storage into data (“chunks”) and metadata (a map of where the “chunks” are). Data chunks live on object stores; metadata lives in fast local storage. In our case, that metadata store is kept durable with Litestream. Nothing depends on local storage.
2025
I designed Dropbox's storage system and modeled its durability. Durability numbers (11 9's etc) are meaningless because competent providers don't lose data because of disk failures, they lose data because of bugs and operator error. [...]
The best thing you can do for your own durability is to choose a competent provider and then ensure you don't accidentally delete or corrupt own data on it:
- Ideally never mutate an object in S3, add a new version instead.
- Never live-delete any data. Mark it for deletion and then use a lifecycle policy to clean it up after a week.
This way you have time to react to a bug in your own stack.
Microservices only pay off when you have real scaling bottlenecks, large teams, or independently evolving domains. Before that? You’re paying the price without getting the benefit: duplicated infra, fragile local setups, and slow iteration.
— Oleg Pustovit, Microservices Are a Tax Your Startup Probably Can’t Afford
2024
DSQL Vignette: Reads and Compute. Marc Brooker is one of the engineers behind AWS's new Aurora DSQL horizontally scalable database. Here he shares all sorts of interesting details about how it works under the hood.
The system is built around the principle of separating storage from compute: storage uses S3, while compute runs in Firecracker:
Each transaction inside DSQL runs in a customized Postgres engine inside a Firecracker MicroVM, dedicated to your database. When you connect to DSQL, we make sure there are enough of these MicroVMs to serve your load, and scale up dynamically if needed. We add MicroVMs in the AZs and regions your connections are coming from, keeping your SQL query processor engine as close to your client as possible to optimize for latency.
We opted to use PostgreSQL here because of its pedigree, modularity, extensibility, and performance. We’re not using any of the storage or transaction processing parts of PostgreSQL, but are using the SQL engine, an adapted version of the planner and optimizer, and the client protocol implementation.
The system then provides strong repeatable-read transaction isolation using MVCC and EC2's high precision clocks, enabling reads "as of time X" including against nearby read replicas.
The storage layer supports index scans, which means the compute layer can push down some operations allowing it to load a subset of the rows it needs, reducing round-trips that are affected by speed-of-light latency.
The overall approach here is disaggregation: we’ve taken each of the critical components of an OLTP database and made it a dedicated service. Each of those services is independently horizontally scalable, most of them are shared-nothing, and each can make the design choices that is most optimal in its domain.
Amazon S3 adds new functionality for conditional writes (via)
Amazon S3 can now perform conditional writes that evaluate if an object is unmodified before updating it. This helps you coordinate simultaneous writes to the same object and prevents multiple concurrent writers from unintentionally overwriting the object without knowing the state of its content. You can use this capability by providing the ETag of an object [...]
This new conditional header can help improve the efficiency of your large-scale analytics, distributed machine learning, and other highly parallelized workloads by reliably offloading compare and swap operations to S3.
(Both Azure Blob Storage and Google Cloud have this feature already.)
When AWS added conditional write support just for if an object with that key exists or not back in August I wrote about Gunnar Morling's trick for Leader Election With S3 Conditional Writes. This new capability opens up a whole set of new patterns for implementing distributed locking systems along those lines.
Here's a useful illustrative example by lxgr on Hacker News:
As a (horribly inefficient, in case of non-trivial write contention) toy example, you could use S3 as a lock-free concurrent SQLite storage backend: Reads work as expected by fetching the entire database and satisfying the operation locally; writes work like this:
- Download the current database copy
- Perform your write locally
- Upload it back using "Put-If-Match" and the pre-edit copy as the matched object.
- If you get success, consider the transaction successful.
- If you get failure, go back to step 1 and try again.
AWS also just added the ability to enforce conditional writes in bucket policies:
To enforce conditional write operations, you can now use s3:if-none-match or s3:if-match condition keys to write a bucket policy that mandates the use of HTTP if-none-match or HTTP if-match conditional headers in S3 PutObject and CompleteMultipartUpload API requests. With this bucket policy in place, any attempt to write an object to your bucket without the required conditional header will be rejected.
Amazon S3 Express One Zone now supports the ability to append data to an object. This is a first for Amazon S3: it is now possible to append data to an existing object in a bucket, where previously the only supported operation was to atomically replace the object with an updated version.
This is only available for S3 Express One Zone, a bucket class introduced a year ago which provides storage in just a single availability zone, providing significantly lower latency at the cost of reduced redundancy and a much higher price (16c/GB/month compared to 2.3c for S3 standard tier).
The fact that appends have never been supported for multi-availability zone S3 provides an interesting clue as to the underlying architecture. Guaranteeing that every copy of an object has received and applied an append is significantly harder than doing a distributed atomic swap to a new version.
More details from the documentation:
There is no minimum size requirement for the data you can append to an object. However, the maximum size of the data that you can append to an object in a single request is 5GB. This is the same limit as the largest request size when uploading data using any Amazon S3 API.
With each successful append operation, you create a part of the object and each object can have up to 10,000 parts. This means you can append data to an object up to 10,000 times. If an object is created using S3 multipart upload, each uploaded part is counted towards the total maximum of 10,000 parts. For example, you can append up to 9,000 times to an object created by multipart upload comprising of 1,000 parts.
That 10,000 limit means this won't quite work for constantly appending to a log file in a bucket.
Presumably it will be possible to "tail" an object that is receiving appended updates using the HTTP Range header.
Zero-latency SQLite storage in every Durable Object (via) Kenton Varda introduces the next iteration of Cloudflare's Durable Object platform, which recently upgraded from a key/value store to a full relational system based on SQLite.
For useful background on the first version of Durable Objects take a look at Cloudflare's durable multiplayer moat by Paul Butler, who digs into its popularity for building WebSocket-based realtime collaborative applications.
The new SQLite-backed Durable Objects is a fascinating piece of distributed system design, which advocates for a really interesting way to architect a large scale application.
The key idea behind Durable Objects is to colocate application logic with the data it operates on. A Durable Object comprises code that executes on the same physical host as the SQLite database that it uses, resulting in blazingly fast read and write performance.
How could this work at scale?
A single object is inherently limited in throughput since it runs on a single thread of a single machine. To handle more traffic, you create more objects. This is easiest when different objects can handle different logical units of state (like different documents, different users, or different "shards" of a database), where each unit of state has low enough traffic to be handled by a single object
Kenton presents the example of a flight booking system, where each flight can map to a dedicated Durable Object with its own SQLite database - thousands of fresh databases per airline per day.
Each DO has a unique name, and Cloudflare's network then handles routing requests to that object wherever it might live on their global network.
The technical details are fascinating. Inspired by Litestream, each DO constantly streams a sequence of WAL entries to object storage - batched every 16MB or every ten seconds. This also enables point-in-time recovery for up to 30 days through replaying those logged transactions.
To ensure durability within that ten second window, writes are also forwarded to five replicas in separate nearby data centers as soon as they commit, and the write is only acknowledged once three of them have confirmed it.
The JavaScript API design is interesting too: it's blocking rather than async, because the whole point of the design is to provide fast single threaded persistence operations:
let docs = sql.exec(`
SELECT title, authorId FROM documents
ORDER BY lastModified DESC
LIMIT 100
`).toArray();
for (let doc of docs) {
doc.authorName = sql.exec(
"SELECT name FROM users WHERE id = ?",
doc.authorId).one().name;
}This one of their examples deliberately exhibits the N+1 query pattern, because that's something SQLite is uniquely well suited to handling.
The system underlying Durable Objects is called Storage Relay Service, and it's been powering Cloudflare's existing-but-different D1 SQLite system for over a year.
I was curious as to where the objects are created. According to this (via Hacker News):
Durable Objects do not currently change locations after they are created. By default, a Durable Object is instantiated in a data center close to where the initial
get()request is made. [...] To manually create Durable Objects in another location, provide an optionallocationHintparameter toget().
And in a footnote:
Dynamic relocation of existing Durable Objects is planned for the future.
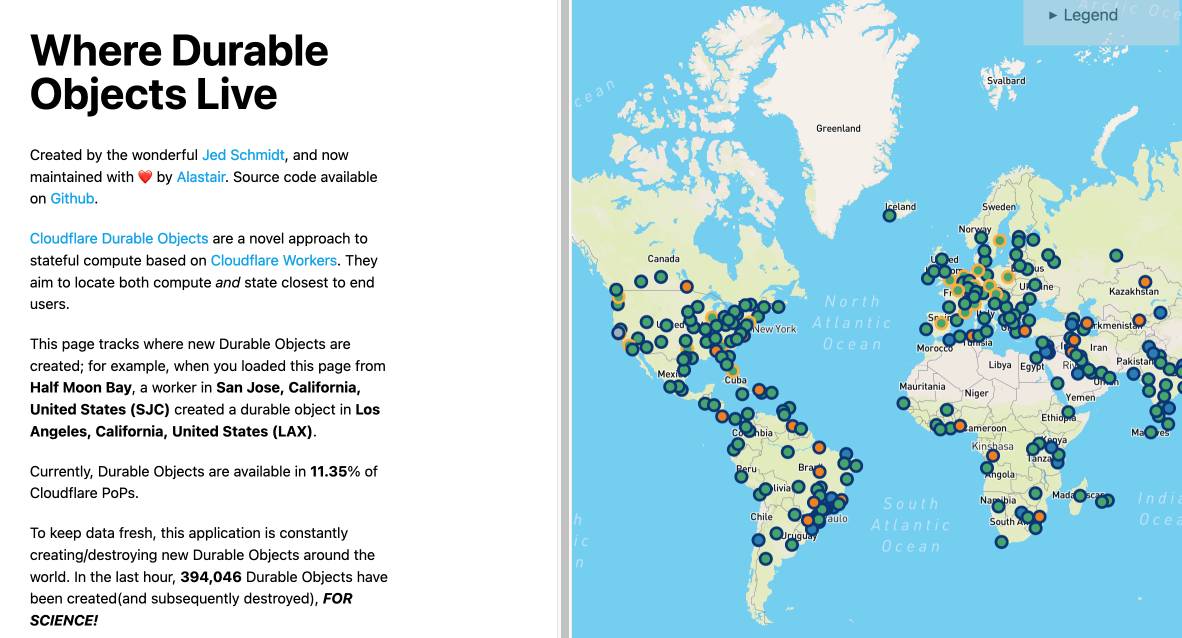
where.durableobjects.live is a neat site that tracks where in the Cloudflare network DOs are created - I just visited it and it said:
This page tracks where new Durable Objects are created; for example, when you loaded this page from Half Moon Bay, a worker in San Jose, California, United States (SJC) created a durable object in San Jose, California, United States (SJC).
Leader Election With S3 Conditional Writes (via) Amazon S3 added support for conditional writes last week, so you can now write a key to S3 with a reliable failure if someone else has has already created it.
This is a big deal. It reminds me of the time in 2020 when S3 added read-after-write consistency, an astonishing piece of distributed systems engineering.
Gunnar Morling demonstrates how this can be used to implement a distributed leader election system. The core flow looks like this:
- Scan an S3 bucket for files matching
lock_*- likelock_0000000001.json. If the highest number contains{"expired": false}then that is the leader - If the highest lock has expired, attempt to become the leader yourself: increment that lock ID and then attempt to create
lock_0000000002.jsonwith a PUT request that includes the newIf-None-Match: *header - set the file content to{"expired": false} - If that succeeds, you are the leader! If not then someone else beat you to it.
- To resign from leadership, update the file with
{"expired": true}
There's a bit more to it than that - Gunnar also describes how to implement lock validity timeouts such that a crashed leader doesn't leave the system leaderless.
(Almost) Every infrastructure decision I endorse or regret after 4 years running infrastructure at a startup (via) Absolutely fascinating post by Jack Lindamood talking about services, tools and processes used by his startup and which ones turned out to work well v.s. which ones are now regretted.
I’d love to see more companies produce lists like this.
2023
Stamina: tutorial (via) Stamina is Hynek’s new Python library that implements an opinionated wrapper on top of Tenacity, providing a decorator for easily implementing exponential backoff retries. This tutorial includes a concise, clear explanation as to why this is such an important concept in building distributed systems.
Large teams spend more time dealing with coordination and are more likely to reach for architecture and abstractions that they hope will reduce coordination costs, aka if I architect this well enough I don’t have to speak to my colleagues. Microservices, event buses, and schema free databases are all examples of attempts to architect our way around coordination. A decade in we’ve learned that these patterns raise the cost of reasoning about a system, during onboarding, during design, and during incidents and outages.
2022
The Amazon Builders’ Library (via) “How Amazon builds and operates software”—an extraordinarily valuable collection of detailed articles about how AWS works and operates under the hood.
Architecture Notes: Datasette (via) I was interviewed for the first edition of Architecture Notes—a new publication (website and newsletter) about software architecture created by Mahdi Yusuf. We covered a bunch of topics in detail: ASGI, SQLIte and asyncio, Baked Data, plugin hook design, Python in WebAssembly, Python in an Electron app and more. Mahdi also turned my scrappy diagrams into beautiful illustrations for the piece.
2021
Behind the scenes, AWS Lambda (via) Bruno Schaatsbergen pulled together details about how AWS Lambda works under the hood from a detailed review of the AWS documentation, the Firecracker paper and various talks at AWS re:Invent.
2020
If microservices are implemented incorrectly or used as a band-aid without addressing some of the root flaws in your system, you'll be unable to do new product development because you're drowning in the complexity.
2019
Serverless Microservice Patterns for AWS (via) A handy collection of 19 architectural patterns for AWS Lambda collected by Jeremy Daly.
2018
How the Citus distributed database rebalances your data. Citus is a fascinating implementation of database sharding built on top of PostgreSQL primitives. PostgreSQL 10 introduced extremely flexible logical replication—in this post Craig Kerstiens explains how Citus use this new ability to re-balance shards (e.g. when you move from two to four physical PostgreSQL nodes) without downtime.
2017
The denormalized query engine design pattern

I presented this talk at DjangoCon 2017 in Spokane, Washington. Below is the abstract, the slides and the YouTube video of the talk.
[... 356 words]2012
What are good ways to develop software architectures using multiple languages?
There are a bunch of options for communicating between different languages, but these days the simplest is definitely JSON—it maps directly to common data structures in PHP, Python, Ruby and so on. Treat it as your common interchange format and you can’t go far wrong. It’s very easy to build simple internal web services on top of JSON.
[... 109 words]2010
What companies are using Node.js in production in Texas?
There’s a list on this page: https://github.com/joyent/node/w...
[... 23 words]The easiest way to have no-downtime upgrades is have an architecture that can tolerate some subset of their processes to be down at any time. De-SPOF and this gets easier (not that de-SPOFing is always trivial).
2009
Twitter, an Evolving Architecture. The most detailed write-up of Twitter’s current architecture I’ve seen, explaining the four layers of cache (all memcached) used by the Twitter API.
2008
Twitter, or Architecture Will Not Save You. Kellan is not an armchair architect. He also doesn’t mention Rails once. Well worth reading.
The GigaOM Interview: Mark Zuckerberg. Some interesting titbits on Facebook’s architecture.