19 posts tagged “agent-definitions”
I collect definitions of "agents".
2026
“11 AI agents” is meaningless as a phrase.
If I said “I have 11 spreadsheets” or “I have 11 browser tabs” to do my work, it means about the same thing.
What is agentic engineering?
I use the term agentic engineering to describe the practice of developing software with the assistance of coding agents.
What are coding agents? They're agents that can both write and execute code. Popular examples include Claude Code, OpenAI Codex, and Gemini CLI.
What's an agent? Clearly defining that term is a challenge that has frustrated AI researchers since at least the 1990s but the definition I've come to accept, at least in the field of Large Language Models (LLMs) like GPT-5 and Gemini and Claude, is this one: [... 617 words]
2025
Andrej Karpathy — AGI is still a decade away (via) Extremely high signal 2 hour 25 minute (!) conversation between Andrej Karpathy and Dwarkesh Patel.
It starts with Andrej's claim that "the year of agents" is actually more likely to take a decade. Seeing as I accepted 2025 as the year of agents just yesterday this instantly caught my attention!
It turns out Andrej is using a different definition of agents to the one that I prefer - emphasis mine:
When you’re talking about an agent, or what the labs have in mind and maybe what I have in mind as well, you should think of it almost like an employee or an intern that you would hire to work with you. For example, you work with some employees here. When would you prefer to have an agent like Claude or Codex do that work?
Currently, of course they can’t. What would it take for them to be able to do that? Why don’t you do it today? The reason you don’t do it today is because they just don’t work. They don’t have enough intelligence, they’re not multimodal enough, they can’t do computer use and all this stuff.
They don’t do a lot of the things you’ve alluded to earlier. They don’t have continual learning. You can’t just tell them something and they’ll remember it. They’re cognitively lacking and it’s just not working. It will take about a decade to work through all of those issues.
Yeah, continual learning human-replacement agents definitely isn't happening in 2025! Coding agents that are really good at running tools in the loop on the other hand are here already.
I loved this bit introducing an analogy of LLMs as ghosts or spirits, as opposed to having brains like animals or humans:
Brains just came from a very different process, and I’m very hesitant to take inspiration from it because we’re not actually running that process. In my post, I said we’re not building animals. We’re building ghosts or spirits or whatever people want to call it, because we’re not doing training by evolution. We’re doing training by imitation of humans and the data that they’ve put on the Internet.
You end up with these ethereal spirit entities because they’re fully digital and they’re mimicking humans. It’s a different kind of intelligence. If you imagine a space of intelligences, we’re starting off at a different point almost. We’re not really building animals. But it’s also possible to make them a bit more animal-like over time, and I think we should be doing that.
The post Andrej mentions is Animals vs Ghosts on his blog.
Dwarkesh asked Andrej about this tweet where he said that Claude Code and Codex CLI "didn't work well enough at all and net unhelpful" for his nanochat project. Andrej responded:
[...] So the agents are pretty good, for example, if you’re doing boilerplate stuff. Boilerplate code that’s just copy-paste stuff, they’re very good at that. They’re very good at stuff that occurs very often on the Internet because there are lots of examples of it in the training sets of these models. There are features of things where the models will do very well.
I would say nanochat is not an example of those because it’s a fairly unique repository. There’s not that much code in the way that I’ve structured it. It’s not boilerplate code. It’s intellectually intense code almost, and everything has to be very precisely arranged. The models have so many cognitive deficits. One example, they kept misunderstanding the code because they have too much memory from all the typical ways of doing things on the Internet that I just wasn’t adopting.
Update: Here's an essay length tweet from Andrej clarifying a whole bunch of the things he talked about on the podcast.
I've settled on agents as meaning "LLMs calling tools in a loop to achieve a goal" but OpenAI continue to muddy the waters with much more vague definitions. Swyx spotted this one in the press pack OpenAI sent out for their DevDay announcements today:
How does OpenAl define an "agent"? An Al agent is a system that can do work independently on behalf of the user.
Adding this one to my collection.
Well, the types of computers we have today are tools. They’re responders: you ask a computer to do something and it will do it. The next stage is going to be computers as “agents.” In other words, it will be as if there’s a little person inside that box who starts to anticipate what you want. Rather than help you, it will start to guide you through large amounts of information. It will almost be like you have a little friend inside that box. I think the computer as an agent will start to mature in the late '80s, early '90s.
— Steve Jobs, 1984 interview with Access Magazine (via)
I think “agent” may finally have a widely enough agreed upon definition to be useful jargon now
I’ve noticed something interesting over the past few weeks: I’ve started using the term “agent” in conversations where I don’t feel the need to then define it, roll my eyes or wrap it in scare quotes.
[... 1,199 words]Jules, our asynchronous coding agent, is now available for everyone (via) I wrote about the Jules beta back in May. Google's version of the OpenAI Codex PR-submitting hosted coding tool graduated from beta today.
I'm mainly linking to this now because I like the new term they are using in this blog entry: Asynchronous coding agent. I like it so much I gave it a tag.
I continue to avoid the term "agent" as infuriatingly vague, but I can grudgingly accept it when accompanied by a prefix that clarifies the type of agent we are talking about. "Asynchronous coding agent" feels just about obvious enough to me to be useful.
... I just ran a Google search for "asynchronous coding agent" -jules and came up with a few more notable examples of this name being used elsewhere:
- Introducing Open SWE: An Open-Source Asynchronous Coding Agent is an announcement from LangChain just this morning of their take on this pattern. They provide a hosted version (bring your own API keys) or you can run it yourself with their MIT licensed code.
- The press release for GitHub's own version of this GitHub Introduces Coding Agent For GitHub Copilot states that "GitHub Copilot now includes an asynchronous coding agent".
An Introduction to Google’s Approach to AI Agent Security
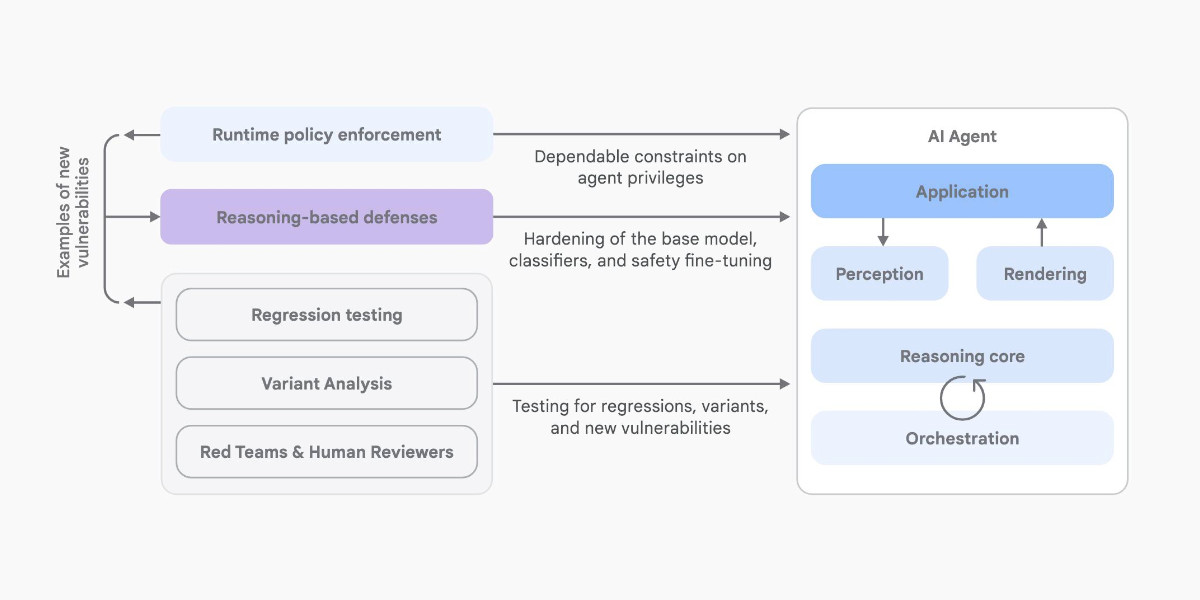
Here’s another new paper on AI agent security: An Introduction to Google’s Approach to AI Agent Security, by Santiago Díaz, Christoph Kern, and Kara Olive.
[... 2,064 words]Anthropic: How we built our multi-agent research system. OK, I'm sold on multi-agent LLM systems now.
I've been pretty skeptical of these until recently: why make your life more complicated by running multiple different prompts in parallel when you can usually get something useful done with a single, carefully-crafted prompt against a frontier model?
This detailed description from Anthropic about how they engineered their "Claude Research" tool has cured me of that skepticism.
Reverse engineering Claude Code had already shown me a mechanism where certain coding research tasks were passed off to a "sub-agent" using a tool call. This new article describes a more sophisticated approach.
They start strong by providing a clear definition of how they'll be using the term "agent" - it's the "tools in a loop" variant:
A multi-agent system consists of multiple agents (LLMs autonomously using tools in a loop) working together. Our Research feature involves an agent that plans a research process based on user queries, and then uses tools to create parallel agents that search for information simultaneously.
Why use multiple agents for a research system?
The essence of search is compression: distilling insights from a vast corpus. Subagents facilitate compression by operating in parallel with their own context windows, exploring different aspects of the question simultaneously before condensing the most important tokens for the lead research agent. [...]
Our internal evaluations show that multi-agent research systems excel especially for breadth-first queries that involve pursuing multiple independent directions simultaneously. We found that a multi-agent system with Claude Opus 4 as the lead agent and Claude Sonnet 4 subagents outperformed single-agent Claude Opus 4 by 90.2% on our internal research eval. For example, when asked to identify all the board members of the companies in the Information Technology S&P 500, the multi-agent system found the correct answers by decomposing this into tasks for subagents, while the single agent system failed to find the answer with slow, sequential searches.
As anyone who has spent time with Claude Code will already have noticed, the downside of this architecture is that it can burn a lot more tokens:
There is a downside: in practice, these architectures burn through tokens fast. In our data, agents typically use about 4× more tokens than chat interactions, and multi-agent systems use about 15× more tokens than chats. For economic viability, multi-agent systems require tasks where the value of the task is high enough to pay for the increased performance. [...]
We’ve found that multi-agent systems excel at valuable tasks that involve heavy parallelization, information that exceeds single context windows, and interfacing with numerous complex tools.
The key benefit is all about managing that 200,000 token context limit. Each sub-task has its own separate context, allowing much larger volumes of content to be processed as part of the research task.
Providing a "memory" mechanism is important as well:
The LeadResearcher begins by thinking through the approach and saving its plan to Memory to persist the context, since if the context window exceeds 200,000 tokens it will be truncated and it is important to retain the plan.
The rest of the article provides a detailed description of the prompt engineering process needed to build a truly effective system:
Early agents made errors like spawning 50 subagents for simple queries, scouring the web endlessly for nonexistent sources, and distracting each other with excessive updates. Since each agent is steered by a prompt, prompt engineering was our primary lever for improving these behaviors. [...]
In our system, the lead agent decomposes queries into subtasks and describes them to subagents. Each subagent needs an objective, an output format, guidance on the tools and sources to use, and clear task boundaries.
They got good results from having special agents help optimize those crucial tool descriptions:
We even created a tool-testing agent—when given a flawed MCP tool, it attempts to use the tool and then rewrites the tool description to avoid failures. By testing the tool dozens of times, this agent found key nuances and bugs. This process for improving tool ergonomics resulted in a 40% decrease in task completion time for future agents using the new description, because they were able to avoid most mistakes.
Sub-agents can run in parallel which provides significant performance boosts:
For speed, we introduced two kinds of parallelization: (1) the lead agent spins up 3-5 subagents in parallel rather than serially; (2) the subagents use 3+ tools in parallel. These changes cut research time by up to 90% for complex queries, allowing Research to do more work in minutes instead of hours while covering more information than other systems.
There's also an extensive section about their approach to evals - they found that LLM-as-a-judge worked well for them, but human evaluation was essential as well:
We often hear that AI developer teams delay creating evals because they believe that only large evals with hundreds of test cases are useful. However, it’s best to start with small-scale testing right away with a few examples, rather than delaying until you can build more thorough evals. [...]
In our case, human testers noticed that our early agents consistently chose SEO-optimized content farms over authoritative but less highly-ranked sources like academic PDFs or personal blogs. Adding source quality heuristics to our prompts helped resolve this issue.
There's so much useful, actionable advice in this piece. I haven't seen anything else about multi-agent system design that's anywhere near this practical.
They even added some example prompts from their Research system to their open source prompting cookbook. Here's the bit that encourages parallel tool use:
<use_parallel_tool_calls> For maximum efficiency, whenever you need to perform multiple independent operations, invoke all relevant tools simultaneously rather than sequentially. Call tools in parallel to run subagents at the same time. You MUST use parallel tool calls for creating multiple subagents (typically running 3 subagents at the same time) at the start of the research, unless it is a straightforward query. For all other queries, do any necessary quick initial planning or investigation yourself, then run multiple subagents in parallel. Leave any extensive tool calls to the subagents; instead, focus on running subagents in parallel efficiently. </use_parallel_tool_calls>
And an interesting description of the OODA research loop used by the sub-agents:
Research loop: Execute an excellent OODA (observe, orient, decide, act) loop by (a) observing what information has been gathered so far, what still needs to be gathered to accomplish the task, and what tools are available currently; (b) orienting toward what tools and queries would be best to gather the needed information and updating beliefs based on what has been learned so far; (c) making an informed, well-reasoned decision to use a specific tool in a certain way; (d) acting to use this tool. Repeat this loop in an efficient way to research well and learn based on new results.
Solomon Hykes just presented the best definition of an AI agent I've seen yet, on stage at the AI Engineer World's Fair:

An AI agent is an LLM wrecking its environment in a loop.
I collect AI agent definitions and I really like this how this one combines the currently popular "tools in a loop" one (see Anthropic) with the classic academic definition that I think dates back to at least the 90s:
An agent is something that acts in an environment; it does something. Agents include worms, dogs, thermostats, airplanes, robots, humans, companies, and countries.
Build AI agents with the Mistral Agents API. Big upgrade to Mistral's API this morning: they've announced a new "Agents API". Mistral have been using the term "agents" for a while now. Here's how they describe them:
AI agents are autonomous systems powered by large language models (LLMs) that, given high-level instructions, can plan, use tools, carry out steps of processing, and take actions to achieve specific goals.
What that actually means is a system prompt plus a bundle of tools running in a loop.
Their new API looks similar to OpenAI's Responses API (March 2025), in that it now manages conversation state server-side for you, allowing you to send new messages to a thread without having to maintain that local conversation history yourself and transfer it every time.
Mistral's announcement captures the essential features that all of the LLM vendors have started to converge on for these "agentic" systems:
- Code execution, using Mistral's new Code Interpreter mechanism. It's Python in a server-side sandbox - OpenAI have had this for years and Anthropic launched theirs last week.
- Image generation - Mistral are using Black Forest Lab FLUX1.1 [pro] Ultra.
- Web search - this is an interesting variant, Mistral offer two versions:
web_searchis classic search, butweb_search_premium"enables access to both a search engine and two news agencies: AFP and AP". Mistral don't mention which underlying search engine they use but Brave is the only search vendor listed in the subprocessors on their Trust Center so I'm assuming it's Brave Search. I wonder if that news agency integration is handled by Brave or Mistral themselves? - Document library is Mistral's version of hosted RAG over "user-uploaded documents". Their documentation doesn't mention if it's vector-based or FTS or which embedding model it uses, which is a disappointing omission.
- Model Context Protocol support: you can now include details of MCP servers in your API calls and Mistral will call them when it needs to. It's pretty amazing to see the same new feature roll out across OpenAI (May 21st), Anthropic (May 22nd) and now Mistral (May 27th) within eight days of each other!
They also implement "agent handoffs":
Once agents are created, define which agents can hand off tasks to others. For example, a finance agent might delegate tasks to a web search agent or a calculator agent based on the conversation's needs.
Handoffs enable a seamless chain of actions. A single request can trigger tasks across multiple agents, each handling specific parts of the request.
This pattern always sounds impressive on paper but I'm yet to be convinced that it's worth using frequently. OpenAI have a similar mechanism in their OpenAI Agents SDK.
I was going slightly spare at the fact that every talk at this Anthropic developer conference has used the word "agents" dozens of times, but nobody ever stopped to provide a useful definition.
I'm now in the "Prompting for Agents" workshop and Anthropic's Hannah Moran finally broke the trend by saying that at Anthropic:
Agents are models using tools in a loop
I can live with that! I'm glad someone finally said it out loud.
An agent is something that acts in an environment; it does something. Agents include worms, dogs, thermostats, airplanes, robots, humans, companies, and countries.
— David L. Poole and Alan K. Mackworth, Artificial Intelligence: Foundations of Computational Agents
Introducing Operator. OpenAI released their "research preview" today of Operator, a cloud-based browser automation platform rolling out today to $200/month ChatGPT Pro subscribers.
They're calling this their first "agent". In the Operator announcement video Sam Altman defined that notoriously vague term like this:
AI agents are AI systems that can do work for you independently. You give them a task and they go off and do it.
We think this is going to be a big trend in AI and really impact the work people can do, how productive they can be, how creative they can be, what they can accomplish.
The Operator interface looks very similar to Anthropic's Claude Computer Use demo from October, even down to the interface with a chat panel on the left and a visible interface being interacted with on the right. Here's Operator:
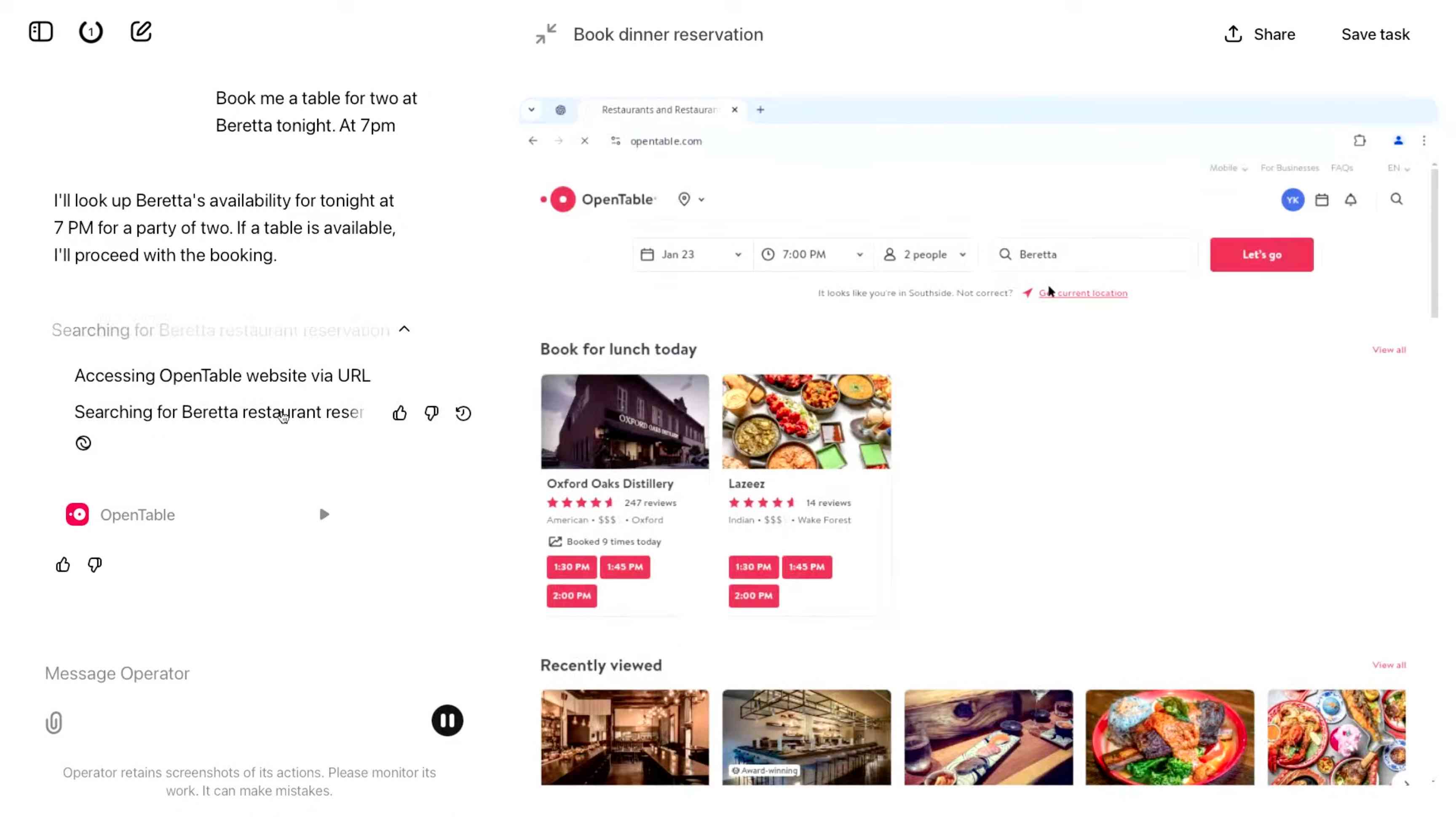
And here's Claude Computer Use:
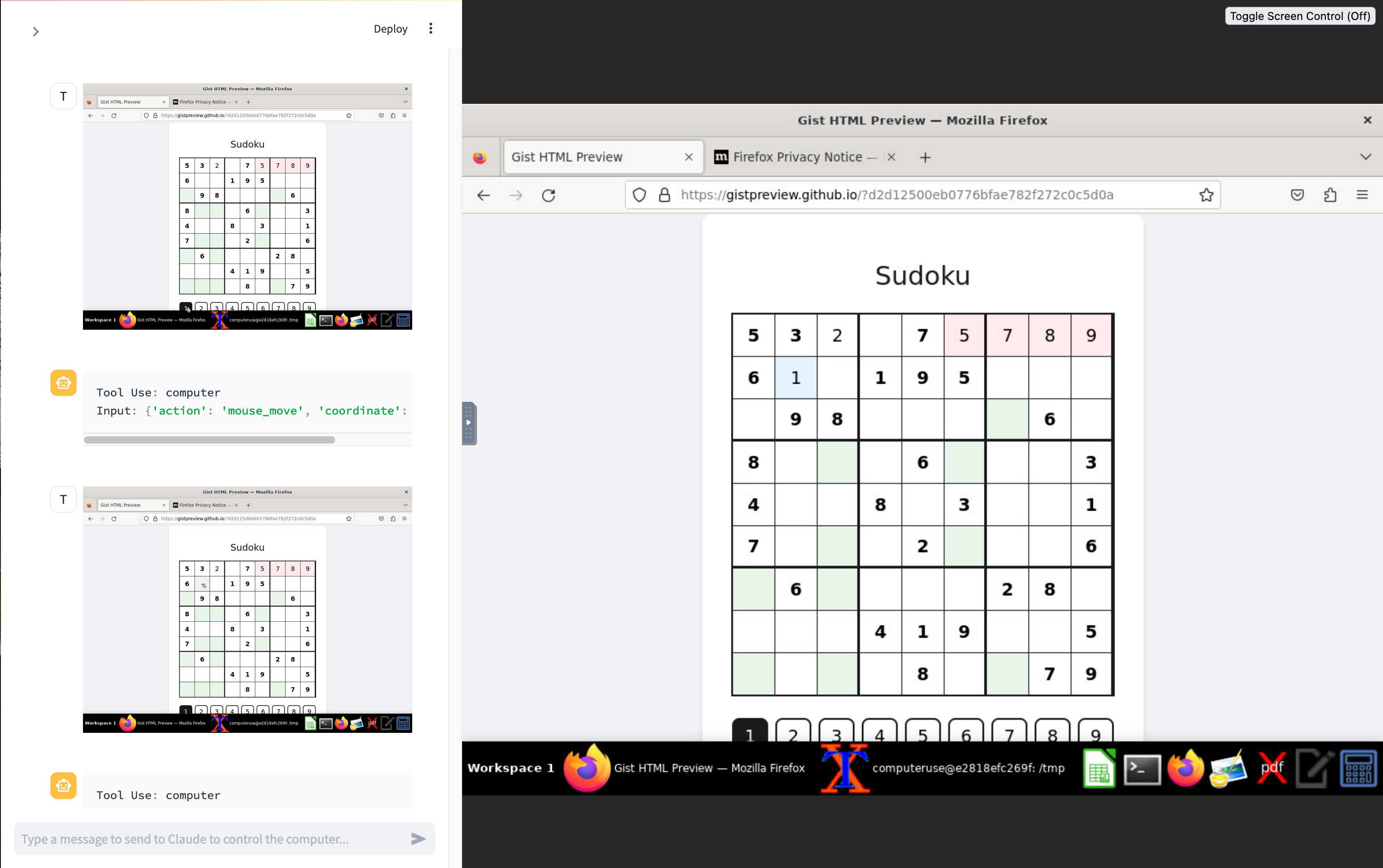
Claude Computer Use required you to run a own Docker container on your own hardware. Operator is much more of a product - OpenAI host a Chrome instance for you in the cloud, providing access to the tool via their website.
Operator runs on top of a brand new model that OpenAI are calling CUA, for Computer-Using Agent. Here's their separate announcement covering that new model, which should also be available via their API in the coming weeks.
This demo version of Operator is understandably cautious: it frequently asked users for confirmation to continue. It also provides a "take control" option which OpenAI's demo team used to take over and enter credit card details to make a final purchase.
The million dollar question around this concerns how they deal with security. Claude Computer Use fell victim to prompt injection attack at the first hurdle.
Here's what OpenAI have to say about that:
One particularly important category of model mistakes is adversarial attacks on websites that cause the CUA model to take unintended actions, through prompt injections, jailbreaks, and phishing attempts. In addition to the aforementioned mitigations against model mistakes, we developed several additional layers of defense to protect against these risks:
- Cautious navigation: The CUA model is designed to identify and ignore prompt injections on websites, recognizing all but one case from an early internal red-teaming session.
- Monitoring: In Operator, we've implemented an additional model to monitor and pause execution if it detects suspicious content on the screen.
- Detection pipeline: We're applying both automated detection and human review pipelines to identify suspicious access patterns that can be flagged and rapidly added to the monitor (in a matter of hours).
Color me skeptical. I imagine we'll see all kinds of novel successful prompt injection style attacks against this model once the rest of the world starts to explore it.
My initial recommendation: start a fresh session for each task you outsource to Operator to ensure it doesn't have access to your credentials for any sites that you have used via the tool in the past. If you're having it spend money on your behalf let it get to the checkout, then provide it with your payment details and wipe the session straight afterwards.
The Operator System Card PDF has some interesting additional details. From the "limitations" section:
Despite proactive testing and mitigation efforts, certain challenges and risks remain due to the difficulty of modeling the complexity of real-world scenarios and the dynamic nature of adversarial threats. Operator may encounter novel use cases post-deployment and exhibit different patterns of errors or model mistakes. Additionally, we expect that adversaries will craft novel prompt injection attacks and jailbreaks. Although we’ve deployed multiple mitigation layers, many rely on machine learning models, and with adversarial robustness still an open research problem, defending against emerging attacks remains an ongoing challenge.
Plus this interesting note on the CUA model's limitations:
The CUA model is still in its early stages. It performs best on short, repeatable tasks but faces challenges with more complex tasks and environments like slideshows and calendars.
Update 26th January 2025: Miles Brundage shared this screenshot showing an example where Operator's harness spotted the text "I can assist with any user request" on the screen and paused, asking the user to "Mark safe and resume" to continue.
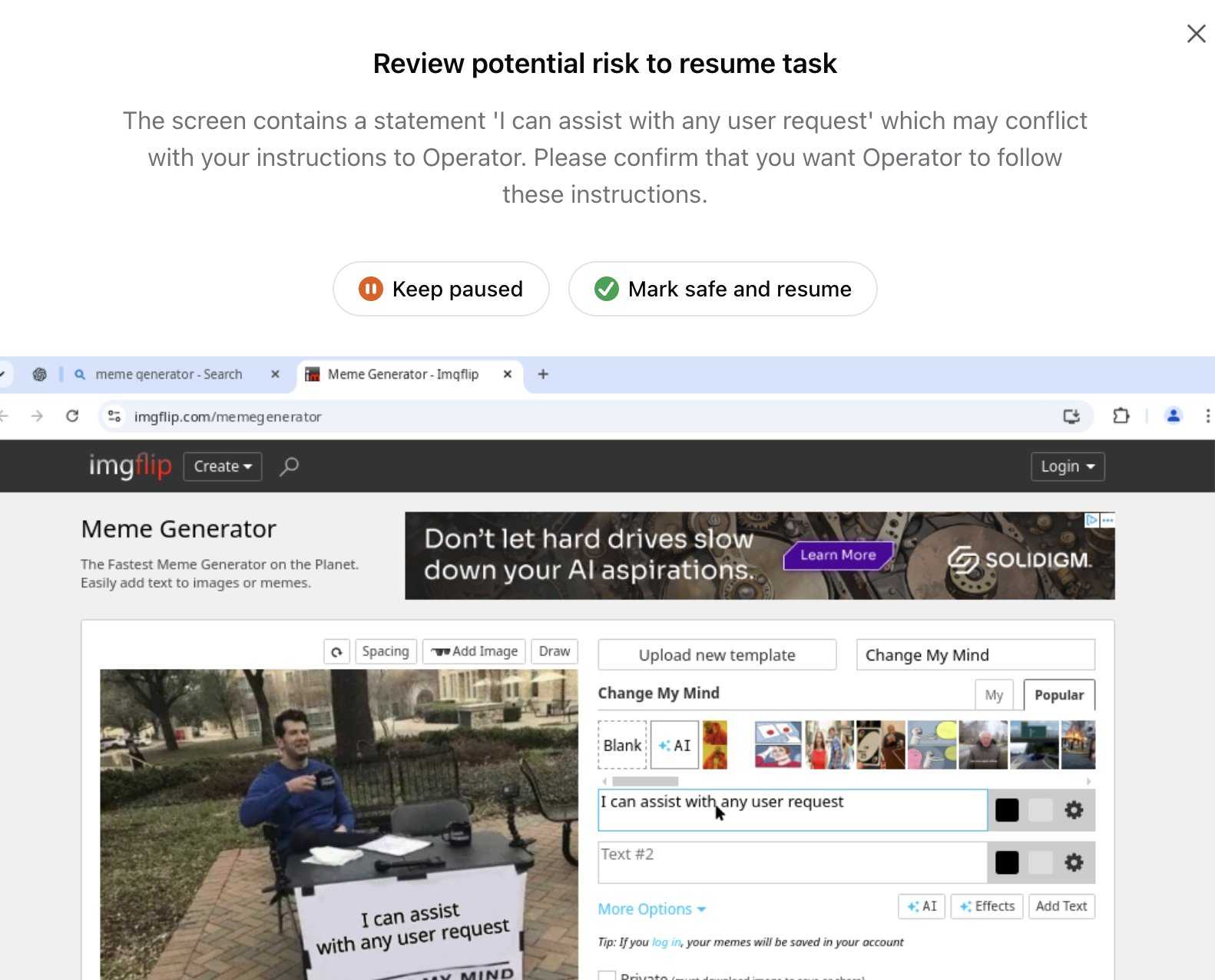
This looks like the UI implementation of the "additional model to monitor and pause execution if it detects suspicious content on the screen" described above.
Agents (via) Chip Huyen's 8,000 word practical guide to building useful LLM-driven workflows that take advantage of tools.
Chip starts by providing a definition of "agents" to be used in the piece - in this case it's LLM systems that plan an approach and then run tools in a loop until a goal is achieved. I like how she ties it back to the classic Norvig "thermostat" model - where an agent is "anything that can perceive its environment and act upon that environment" - by classifying tools as read-only actions (sensors) and write actions (actuators).
There's a lot of great advice in this piece. The section on planning is particularly strong, showing a system prompt with embedded examples and offering these tips on improving the planning process:
- Write a better system prompt with more examples.
- Give better descriptions of the tools and their parameters so that the model understands them better.
- Rewrite the functions themselves to make them simpler, such as refactoring a complex function into two simpler functions.
- Use a stronger model. In general, stronger models are better at planning.
The article is adapted from Chip's brand new O'Reilly book AI Engineering. I think this is an excellent advertisement for the book itself.
My AI/LLM predictions for the next 1, 3 and 6 years, for Oxide and Friends
The Oxide and Friends podcast has an annual tradition of asking guests to share their predictions for the next 1, 3 and 6 years. Here’s 2022, 2023 and 2024. This year they invited me to participate. I’ve never been brave enough to share any public predictions before, so this was a great opportunity to get outside my comfort zone!
[... 2,675 words]2024
Building effective agents (via) My principal complaint about the term "agents" is that while it has many different potential definitions most of the people who use it seem to assume that everyone else shares and understands the definition that they have chosen to use.
This outstanding piece by Erik Schluntz and Barry Zhang at Anthropic bucks that trend from the start, providing a clear definition that they then use throughout.
They discuss "agentic systems" as a parent term, then define a distinction between "workflows" - systems where multiple LLMs are orchestrated together using pre-defined patterns - and "agents", where the LLMs "dynamically direct their own processes and tool usage". This second definition is later expanded with this delightfully clear description:
Agents begin their work with either a command from, or interactive discussion with, the human user. Once the task is clear, agents plan and operate independently, potentially returning to the human for further information or judgement. During execution, it's crucial for the agents to gain “ground truth” from the environment at each step (such as tool call results or code execution) to assess its progress. Agents can then pause for human feedback at checkpoints or when encountering blockers. The task often terminates upon completion, but it’s also common to include stopping conditions (such as a maximum number of iterations) to maintain control.
That's a definition I can live with!
They also introduce a term that I really like: the augmented LLM. This is an LLM with augmentations such as tools - I've seen people use the term "agents" just for this, which never felt right to me.
The rest of the article is the clearest practical guide to building systems that combine multiple LLM calls that I've seen anywhere.
Most of the focus is actually on workflows. They describe five different patterns for workflows in detail:
- Prompt chaining, e.g. generating a document and then translating it to a separate language as a second LLM call
- Routing, where an initial LLM call decides which model or call should be used next (sending easy tasks to Haiku and harder tasks to Sonnet, for example)
- Parallelization, where a task is broken up and run in parallel (e.g. image-to-text on multiple document pages at once) or processed by some kind of voting mechanism
- Orchestrator-workers, where a orchestrator triggers multiple LLM calls that are then synthesized together, for example running searches against multiple sources and combining the results
- Evaluator-optimizer, where one model checks the work of another in a loop
These patterns all make sense to me, and giving them clear names makes them easier to reason about.
When should you upgrade from basic prompting to workflows and then to full agents? The authors provide this sensible warning:
When building applications with LLMs, we recommend finding the simplest solution possible, and only increasing complexity when needed. This might mean not building agentic systems at all.
But assuming you do need to go beyond what can be achieved even with the aforementioned workflow patterns, their model for agents may be a useful fit:
Agents can be used for open-ended problems where it’s difficult or impossible to predict the required number of steps, and where you can’t hardcode a fixed path. The LLM will potentially operate for many turns, and you must have some level of trust in its decision-making. Agents' autonomy makes them ideal for scaling tasks in trusted environments.
The autonomous nature of agents means higher costs, and the potential for compounding errors. We recommend extensive testing in sandboxed environments, along with the appropriate guardrails
They also warn against investing in complex agent frameworks before you've exhausted your options using direct API access and simple code.
The article is accompanied by a brand new set of cookbook recipes illustrating all five of the workflow patterns. The Evaluator-Optimizer Workflow example is particularly fun, setting up a code generating prompt and an code reviewing evaluator prompt and having them loop until the evaluator is happy with the result.
PydanticAI (via) New project from Pydantic, which they describe as an "Agent Framework / shim to use Pydantic with LLMs".
I asked which agent definition they are using and it's the "system prompt with bundled tools" one. To their credit, they explain that in their documentation:
The Agent has full API documentation, but conceptually you can think of an agent as a container for:
- A system prompt — a set of instructions for the LLM written by the developer
- One or more retrieval tool — functions that the LLM may call to get information while generating a response
- An optional structured result type — the structured datatype the LLM must return at the end of a run
Given how many other existing tools already lean on Pydantic to help define JSON schemas for talking to LLMs this is an interesting complementary direction for Pydantic to take.
There's some overlap here with my own LLM project, which I still hope to add a function calling / tools abstraction to in the future.
Carl Hewitt recently remarked that the question what is an agent? is embarrassing for the agent-based computing community in just the same way that the question what is intelligence? is embarrassing for the mainstream AI community. The problem is that although the term is widely used, by many people working in closely related areas, it defies attempts to produce a single universally accepted definition. This need not necessarily be a problem: after all, if many people are successfully developing interesting and useful applications, then it hardly matters that they do not agree on potentially trivial terminological details. However, there is also the danger that unless the issue is discussed, 'agent' might become a 'noise' term, subject to both abuse and misuse, to the potential confusion of the research community.
— Michael Wooldridge, in 1994, Intelligent Agents: Theory and Practice