Items tagged llama in Jul
Filters: Month: Jul × llama × Sorted by date
One interesting observation is the impact of environmental factors on training performance at scale. For Llama 3 405B , we noted a diurnal 1-2% throughput variation based on time-of-day. This fluctuation is the result of higher mid-day temperatures impacting GPU dynamic voltage and frequency scaling.
During training, tens of thousands of GPUs may increase or decrease power consumption at the same time, for example, due to all GPUs waiting for checkpointing or collective communications to finish, or the startup or shutdown of the entire training job. When this happens, it can result in instant fluctuations of power consumption across the data center on the order of tens of megawatts, stretching the limits of the power grid. This is an ongoing challenge for us as we scale training for future, even larger Llama models.
llm-gguf. I just released a new alpha plugin for LLM which adds support for running models from Meta's new Llama 3.1 family that have been packaged as GGUF files - it should work for other GGUF chat models too.
If you've already installed LLM the following set of commands should get you setup with Llama 3.1 8B:
llm install llm-gguf
llm gguf download-model \
https://huggingface.co/lmstudio-community/Meta-Llama-3.1-8B-Instruct-GGUF/resolve/main/Meta-Llama-3.1-8B-Instruct-Q4_K_M.gguf \
--alias llama-3.1-8b-instruct --alias l31i
This will download a 4.92GB GGUF from lmstudio-community/Meta-Llama-3.1-8B-Instruct-GGUF on Hugging Face and save it (at least on macOS) to your ~/Library/Application Support/io.datasette.llm/gguf/models folder.
Once installed like that, you can run prompts through the model like so:
llm -m l31i "five great names for a pet lemur"
Or use the llm chat command to keep the model resident in memory and run an interactive chat session with it:
llm chat -m l31i
I decided to ship a new alpha plugin rather than update my existing llm-llama-cpp plugin because that older plugin has some design decisions baked in from the Llama 2 release which no longer make sense, and having a fresh plugin gave me a fresh slate to adopt the latest features from the excellent underlying llama-cpp-python library by Andrei Betlen.
I believe the Llama 3.1 release will be an inflection point in the industry where most developers begin to primarily use open source, and I expect that approach to only grow from here.
Introducing Llama 3.1: Our most capable models to date. We've been waiting for the largest release of the Llama 3 model for a few months, and now we're getting a whole new model family instead.
Meta are calling Llama 3.1 405B "the first frontier-level open source AI model" and it really is benchmarking in that GPT-4+ class, competitive with both GPT-4o and Claude 3.5 Sonnet.
I'm equally excited by the new 8B and 70B 3.1 models - both of which now support a 128,000 token context and benchmark significantly higher than their Llama 3 equivalents. Same-sized models getting more powerful and capable a very reassuring trend. I expect the 8B model (or variants of it) to run comfortably on an array of consumer hardware, and I've run a 70B model on a 64GB M2 in the past.
The 405B model can at least be run on a single server-class node:
To support large-scale production inference for a model at the scale of the 405B, we quantized our models from 16-bit (BF16) to 8-bit (FP8) numerics, effectively lowering the compute requirements needed and allowing the model to run within a single server node.
Meta also made a significant change to the license:
We’ve also updated our license to allow developers to use the outputs from Llama models — including 405B — to improve other models for the first time.
We’re excited about how this will enable new advancements in the field through synthetic data generation and model distillation workflows, capabilities that have never been achieved at this scale in open source.
I'm really pleased to see this. Using models to help improve other models has been a crucial technique in LLM research for over a year now, especially for fine-tuned community models release on Hugging Face. Researchers have mostly been ignoring this restriction, so it's reassuring to see the uncertainty around that finally cleared up.
Lots more details about the new models in the paper The Llama 3 Herd of Models including this somewhat opaque note about the 15 trillion token training data:
Our final data mix contains roughly 50% of tokens corresponding to general knowledge, 25% of mathematical and reasoning tokens, 17% code tokens, and 8% multilingual tokens.
Update: I got the Llama 3.1 8B Instruct model working with my LLM tool via a new plugin, llm-gguf.
Llama 2: The New Open LLM SOTA. I’m in this Latent Space podcast, recorded yesterday, talking about the Llama 2 release.
llama2-mac-gpu.sh (via) Adrien Brault provided this recipe for compiling llama.cpp on macOS with GPU support enabled (“LLAMA_METAL=1 make”) and then downloading and running a GGML build of Llama 2 13B.
Ollama (via) This tool for running LLMs on your own laptop directly includes an installer for macOS (Apple Silicon) and provides a terminal chat interface for interacting with models. They already have Llama 2 support working, with a model that downloads directly from their own registry service without need to register for an account or work your way through a waiting list.
Accessing Llama 2 from the command-line with the llm-replicate plugin
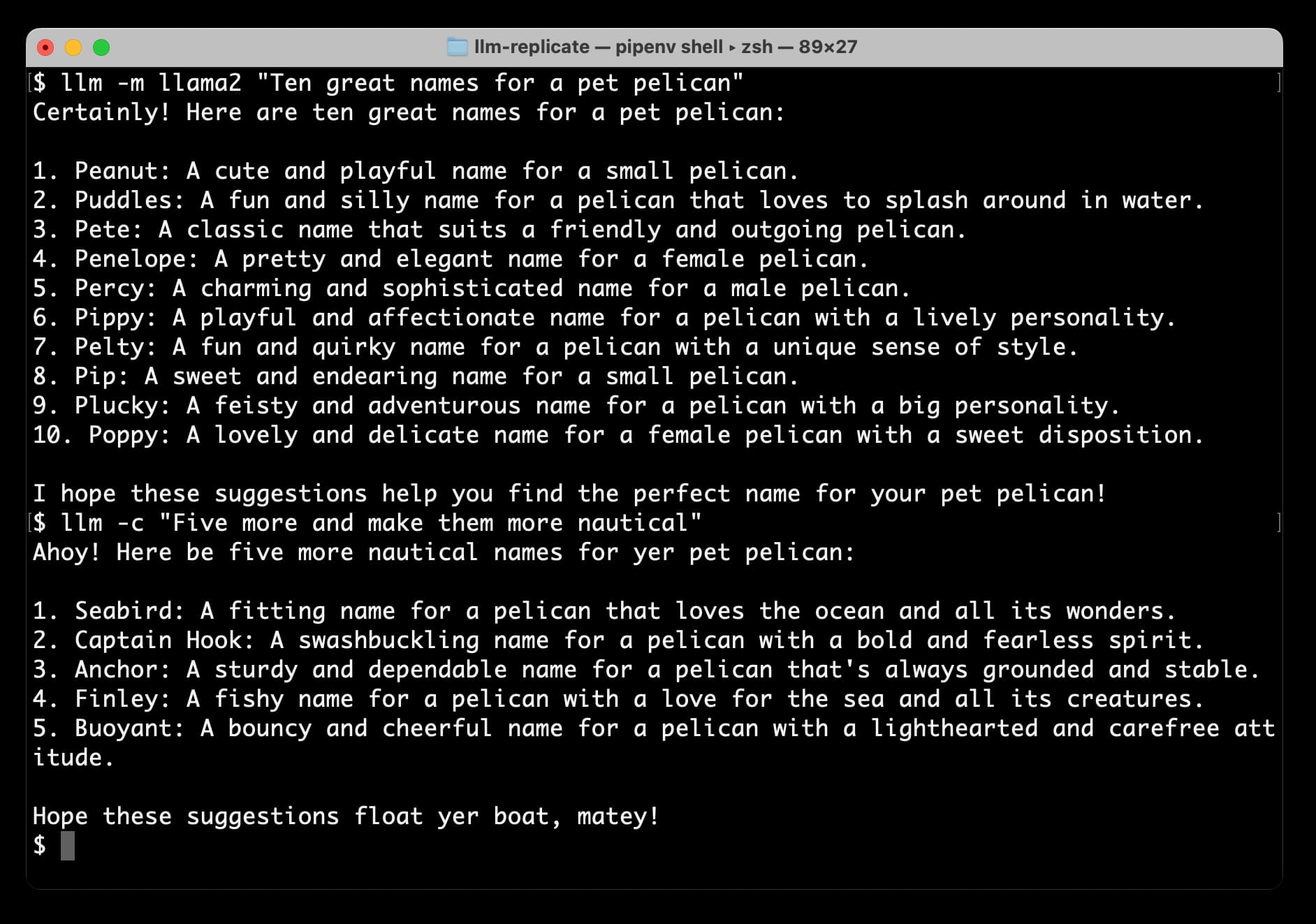
The big news today is Llama 2, the new openly licensed Large Language Model from Meta AI. It’s a really big deal:
[... 1,206 words]