Wednesday, 29th October 2025
Composer: Building a fast frontier model with RL (via) Cursor released Cursor 2.0 today, with a refreshed UI focused on agentic coding (and running agents in parallel) and a new model that's unique to Cursor called Composer 1.
As far as I can tell there's no way to call the model directly via an API, so I fired up "Ask" mode in Cursor's chat side panel and asked it to "Generate an SVG of a pelican riding a bicycle":
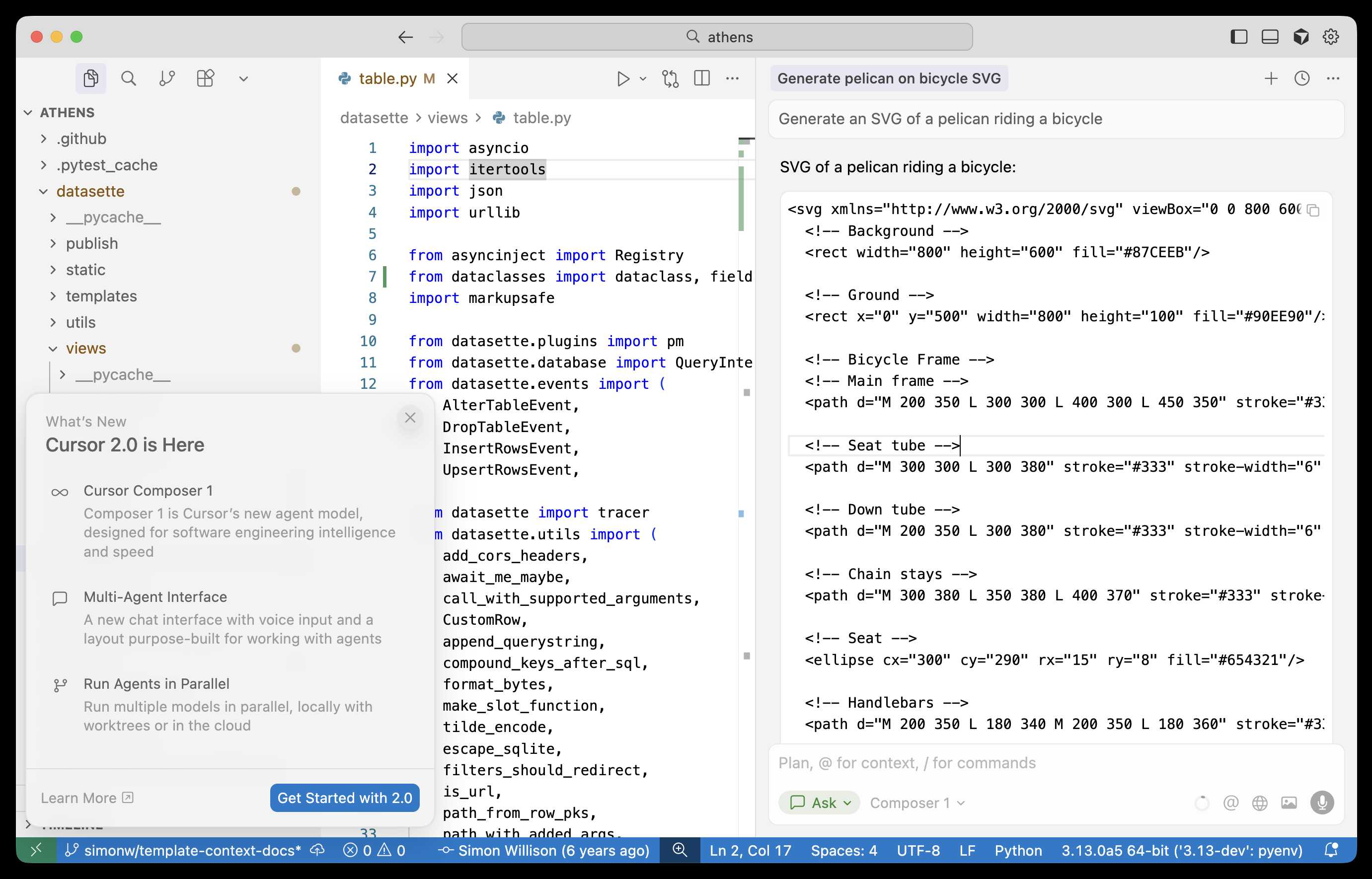
Here's the result:

The notable thing about Composer-1 is that it is designed to be fast. The pelican certainly came back quickly, and in their announcement they describe it as being "4x faster than similarly intelligent models".
It's interesting to see Cursor investing resources in training their own code-specific model - similar to GPT-5-Codex or Qwen3-Coder. From their post:
Composer is a mixture-of-experts (MoE) language model supporting long-context generation and understanding. It is specialized for software engineering through reinforcement learning (RL) in a diverse range of development environments. [...]
Efficient training of large MoE models requires significant investment into building infrastructure and systems research. We built custom training infrastructure leveraging PyTorch and Ray to power asynchronous reinforcement learning at scale. We natively train our models at low precision by combining our MXFP8 MoE kernels with expert parallelism and hybrid sharded data parallelism, allowing us to scale training to thousands of NVIDIA GPUs with minimal communication cost. [...]
During RL, we want our model to be able to call any tool in the Cursor Agent harness. These tools allow editing code, using semantic search, grepping strings, and running terminal commands. At our scale, teaching the model to effectively call these tools requires running hundreds of thousands of concurrent sandboxed coding environments in the cloud.
One detail that's notably absent from their description: did they train the model from scratch, or did they start with an existing open-weights model such as something from Qwen or GLM?
Cursor researcher Sasha Rush has been answering questions on Hacker News, but has so far been evasive in answering questions about the base model. When directly asked "is Composer a fine tune of an existing open source base model?" they replied:
Our primary focus is on RL post-training. We think that is the best way to get the model to be a strong interactive agent.
Sasha did confirm that rumors of an earlier Cursor preview model, Cheetah, being based on a model by xAI's Grok were "Straight up untrue."
MiniMax M2 & Agent: Ingenious in Simplicity. MiniMax M2 was released on Monday 27th October by MiniMax, a Chinese AI lab founded in December 2021.
It's a very promising model. Their self-reported benchmark scores show it as comparable to Claude Sonnet 4, and Artificial Analysis are ranking it as the best currently available open weight model according to their intelligence score:
MiniMax’s M2 achieves a new all-time-high Intelligence Index score for an open weights model and offers impressive efficiency with only 10B active parameters (200B total). [...]
The model’s strengths include tool use and instruction following (as shown by Tau2 Bench and IFBench). As such, while M2 likely excels at agentic use cases it may underperform other open weights leaders such as DeepSeek V3.2 and Qwen3 235B at some generalist tasks. This is in line with a number of recent open weights model releases from Chinese AI labs which focus on agentic capabilities, likely pointing to a heavy post-training emphasis on RL.
The size is particularly significant: the model weights are 230GB on Hugging Face, significantly smaller than other high performing open weight models. That's small enough to run on a 256GB Mac Studio, and the MLX community have that working already.
MiniMax offer their own API, and recommend using their Anthropic-compatible endpoint and the official Anthropic SDKs to access it. MiniMax Head of Engineering Skyler Miao provided some background on that:
M2 is a agentic thinking model, it do interleaved thinking like sonnet 4.5, which means every response will contain its thought content. Its very important for M2 to keep the chain of thought. So we must make sure the history thought passed back to the model. Anthropic API support it for sure, as sonnet needs it as well. OpenAI only support it in their new Response API, no support for in ChatCompletion.
MiniMax are offering the new model via their API for free until November 7th, after which the cost will be $0.30/million input tokens and $1.20/million output tokens - similar in price to Gemini 2.5 Flash and GPT-5 Mini, see price comparison here on my llm-prices.com site.
I released a new plugin for LLM called llm-minimax providing support for M2 via the MiniMax API:
llm install llm-minimax
llm keys set minimax
# Paste key here
llm -m m2 -o max_tokens 10000 "Generate an SVG of a pelican riding a bicycle"
Here's the result:

51 input, 4,017 output. At $0.30/m input and $1.20/m output that pelican would cost 0.4836 cents - less than half a cent.
This is the first plugin I've written for an Anthropic-API-compatible model. I released llm-anthropic 0.21 first adding the ability to customize the base_url parameter when using that model class. This meant the new plugin was less than 30 lines of Python.
Introducing SWE-1.5: Our Fast Agent Model (via) Here's the second fast coding model released by a coding agent IDE in the same day - the first was Composer-1 by Cursor. This time it's Windsurf releasing SWE-1.5:
Today we’re releasing SWE-1.5, the latest in our family of models optimized for software engineering. It is a frontier-size model with hundreds of billions of parameters that achieves near-SOTA coding performance. It also sets a new standard for speed: we partnered with Cerebras to serve it at up to 950 tok/s – 6x faster than Haiku 4.5 and 13x faster than Sonnet 4.5.
Like Composer-1 it's only available via their editor, no separate API yet. Also like Composer-1 they don't appear willing to share details of the "leading open-source base model" they based their new model on.
I asked it to generate an SVG of a pelican riding a bicycle and got this:

This one felt really fast. Partnering with Cerebras for inference is a very smart move.
They share a lot of details about their training process in the post:
SWE-1.5 is trained on our state-of-the-art cluster of thousands of GB200 NVL72 chips. We believe SWE-1.5 may be the first public production model trained on the new GB200 generation. [...]
Our RL rollouts require high-fidelity environments with code execution and even web browsing. To achieve this, we leveraged our VM hypervisor
otterlinkthat allows us to scale Devin to tens of thousands of concurrent machines (learn more about blockdiff). This enabled us to smoothly support very high concurrency and ensure the training environment is aligned with our Devin production environments.
That's another similarity to Cursor's Composer-1! Cursor talked about how they ran "hundreds of thousands of concurrent sandboxed coding environments in the cloud" in their description of their RL training as well.
This is a notable trend: if you want to build a really great agentic coding tool there's clearly a lot to be said for using reinforcement learning to fine-tune a model against your own custom set of tools using large numbers of sandboxed simulated coding environments as part of that process.
Update: I think it's built on GLM.