7th March 2025 - Link Blog
Mistral OCR (via) New closed-source specialist OCR model by Mistral - you can feed it images or a PDF and it produces Markdown with optional embedded images.
It's available via their API, or it's "available to self-host on a selective basis" for people with stringent privacy requirements who are willing to talk to their sales team.
I decided to try out their API, so I copied and pasted example code from their notebook into my custom Claude project and told it:
Turn this into a CLI app, depends on mistralai - it should take a file path and an optional API key defauling to env vironment called MISTRAL_API_KEY
After some further iteration / vibe coding I got to something that worked, which I then tidied up and shared as mistral_ocr.py.
You can try it out like this:
export MISTRAL_API_KEY='...'
uv run http://tools.simonwillison.net/python/mistral_ocr.py \
mixtral.pdf --html --inline-images > mixtral.html
I fed in the Mixtral paper as a PDF. The API returns Markdown, but my --html option renders that Markdown as HTML and the --inline-images option takes any images and inlines them as base64 URIs (inspired by monolith). The result is mixtral.html, a 972KB HTML file with images and text bundled together.
This did a pretty great job!
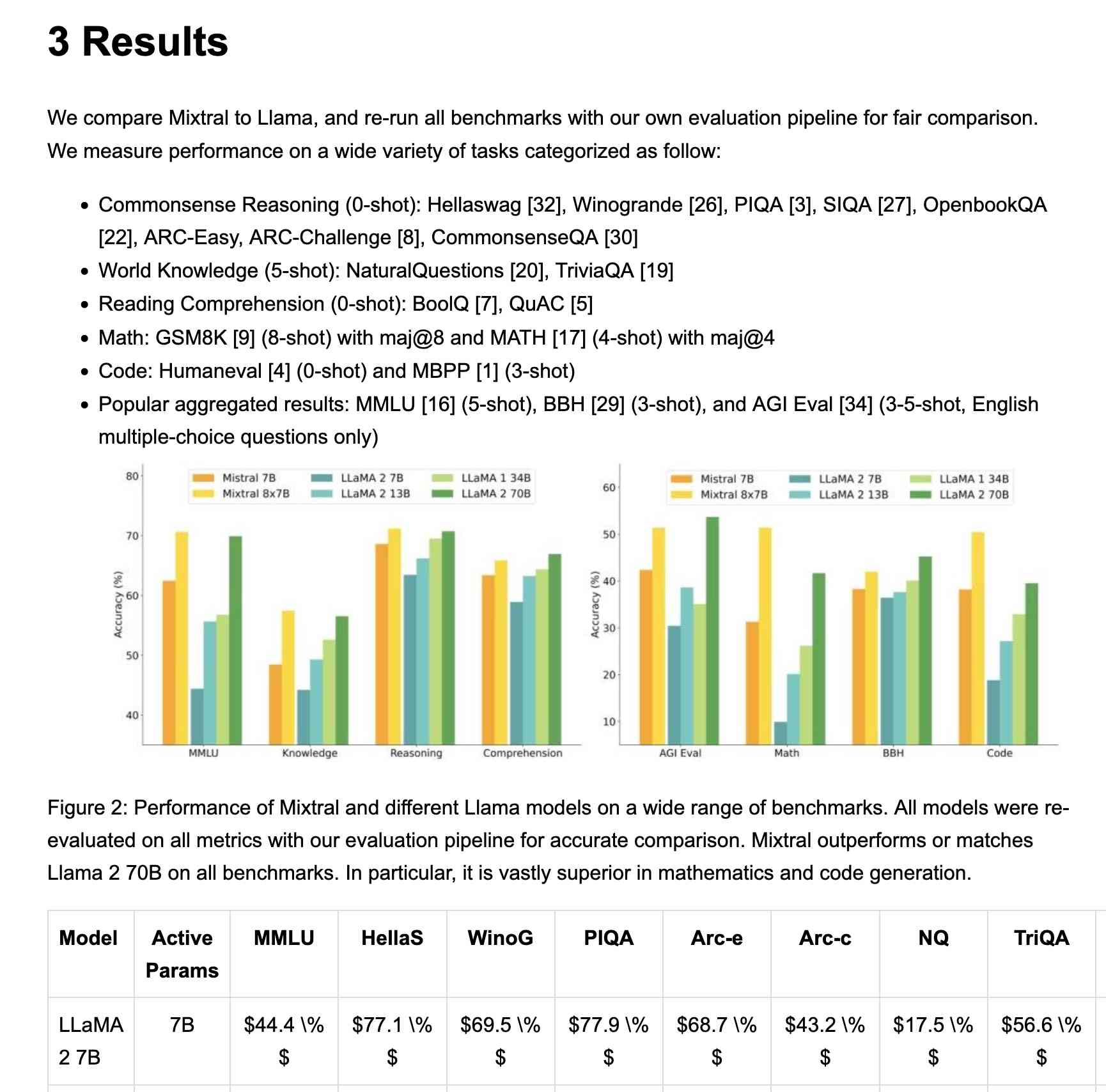
My script renders Markdown tables but I haven't figured out how to render inline Markdown MathML yet. I ran the command a second time and requested Markdown output (the default) like this:
uv run http://tools.simonwillison.net/python/mistral_ocr.py \
mixtral.pdf > mixtral.md
Here's that Markdown rendered as a Gist - there are a few MathML glitches so clearly the Mistral OCR MathML dialect and the GitHub Formatted Markdown dialect don't quite line up.
My tool can also output raw JSON as an alternative to Markdown or HTML - full details in the documentation.
The Mistral API is priced at roughly 1000 pages per dollar, with a 50% discount for batch usage.
The big question with LLM-based OCR is always how well it copes with accidental instructions in the text (can you safely OCR a document full of prompting examples?) and how well it handles text it can't write.
Mistral's Sophia Yang says it "should be robust" against following instructions in the text, and invited people to try and find counter-examples.
Alexander Doria noted that Mistral OCR can hallucinate text when faced with handwriting that it cannot understand.
Recent articles
- The Axios supply chain attack used individually targeted social engineering - 3rd April 2026
- Highlights from my conversation about agentic engineering on Lenny's Podcast - 2nd April 2026
- Mr. Chatterbox is a (weak) Victorian-era ethically trained model you can run on your own computer - 30th March 2026