Wednesday, 25th June 2025
Gemini CLI. First there was Claude Code in February, then OpenAI Codex (CLI) in April, and now Gemini CLI in June. All three of the largest AI labs now have their own version of what I am calling a "terminal agent" - a CLI tool that can read and write files and execute commands on your behalf in the terminal.
I'm honestly a little surprised at how significant this category has become: I had assumed that terminal tools like this would always be something of a niche interest, but given the number of people I've heard from spending hundreds of dollars a month on Claude Code this niche is clearly larger and more important than I had thought!
I had a few days of early access to the Gemini one. It's very good - it takes advantage of Gemini's million token context and has good taste in things like when to read a file and when to run a command.
Like OpenAI Codex and unlike Claude Code it's open source (Apache 2) - the full source code can be found in google-gemini/gemini-cli on GitHub. The core system prompt lives in core/src/core/prompts.ts - I've extracted that out as a rendered Markdown Gist.
As usual, the system prompt doubles as extremely accurate and concise documentation of what the tool can do! Here's what it has to say about comments, for example:
- Comments: Add code comments sparingly. Focus on why something is done, especially for complex logic, rather than what is done. Only add high-value comments if necessary for clarity or if requested by the user. Do not edit comments that are seperate from the code you are changing. NEVER talk to the user or describe your changes through comments.
The list of preferred technologies is interesting too:
When key technologies aren't specified prefer the following:
- Websites (Frontend): React (JavaScript/TypeScript) with Bootstrap CSS, incorporating Material Design principles for UI/UX.
- Back-End APIs: Node.js with Express.js (JavaScript/TypeScript) or Python with FastAPI.
- Full-stack: Next.js (React/Node.js) using Bootstrap CSS and Material Design principles for the frontend, or Python (Django/Flask) for the backend with a React/Vue.js frontend styled with Bootstrap CSS and Material Design principles.
- CLIs: Python or Go.
- Mobile App: Compose Multiplatform (Kotlin Multiplatform) or Flutter (Dart) using Material Design libraries and principles, when sharing code between Android and iOS. Jetpack Compose (Kotlin JVM) with Material Design principles or SwiftUI (Swift) for native apps targeted at either Android or iOS, respectively.
- 3d Games: HTML/CSS/JavaScript with Three.js.
- 2d Games: HTML/CSS/JavaScript.
As far as I can tell Gemini CLI only defines a small selection of tools:
edit: To modify files programmatically.glob: To find files by pattern.grep: To search for content within files.ls: To list directory contents.shell: To execute a command in the shellmemoryTool: To remember user-specific facts.read-file: To read a single filewrite-file: To write a single fileread-many-files: To read multiple files at once.web-fetch: To get content from URLs.web-search: To perform a web search (using Grounding with Google Search via the Gemini API).
I found most of those by having Gemini CLI inspect its own code for me! Here's that full transcript, which used just over 300,000 tokens total.
How much does it cost? The announcement describes a generous free tier:
To use Gemini CLI free-of-charge, simply login with a personal Google account to get a free Gemini Code Assist license. That free license gets you access to Gemini 2.5 Pro and its massive 1 million token context window. To ensure you rarely, if ever, hit a limit during this preview, we offer the industry’s largest allowance: 60 model requests per minute and 1,000 requests per day at no charge.
It's not yet clear to me if your inputs can be used to improve Google's models if you are using the free tier - that's been the situation with free prompt inference they have offered in the past.
You can also drop in your own paid API key, at which point your data will not be used for model improvements and you'll be billed based on your token usage.
Creating art is a nonlinear process. I start with a rough goal. But then I head into dead ends and get lost or stuck.
The secret to my process is to be on high alert in this deep jungle for unexpected twists and turns, because this is where a new idea is born.
I can't make art when I'm excluded from the most crucial moments.
— Christoph Niemann, An Illustrator Confronts His Fears About A.I. Art
Build and share AI-powered apps with Claude. Anthropic have added one of the most important missing features to Claude Artifacts: apps built as artifacts now have the ability to run their own prompts against Claude via a new API.
Claude Artifacts are web apps that run in a strictly controlled browser sandbox: their access to features like localStorage or the ability to access external APIs via fetch() calls is restricted by CSP headers and the <iframe sandbox="..." mechanism.
The new window.claude.complete() method opens a hole that allows prompts composed by the JavaScript artifact application to be run against Claude.
As before, you can publish apps built using artifacts such that anyone can see them. The moment your app tries to execute a prompt the current user will be required to sign into their own Anthropic account so that the prompt can be billed against them, and not against you.
I'm amused that Anthropic turned "we added a window.claude.complete() function to Artifacts" into what looks like a major new product launch, but I can't say it's bad marketing for them to do that!
As always, the crucial details about how this all works are tucked away in tool descriptions in the system prompt. Thankfully this one was easy to leak. Here's the full set of instructions, which start like this:
When using artifacts and the analysis tool, you have access to window.claude.complete. This lets you send completion requests to a Claude API. This is a powerful capability that lets you orchestrate Claude completion requests via code. You can use this capability to do sub-Claude orchestration via the analysis tool, and to build Claude-powered applications via artifacts.
This capability may be referred to by the user as "Claude in Claude" or "Claudeception".
[...]
The API accepts a single parameter -- the prompt you would like to complete. You can call it like so:
const response = await window.claude.complete('prompt you would like to complete')
I haven't seen "Claudeception" in any of their official documentation yet!
That window.claude.complete(prompt) method is also available to the Claude analysis tool. It takes a string and returns a string.
The new function only handles strings. The tool instructions provide tips to Claude about prompt engineering a JSON response that will look frustratingly familiar:
- Use strict language: Emphasize that the response must be in JSON format only. For example: “Your entire response must be a single, valid JSON object. Do not include any text outside of the JSON structure, including backticks ```.”
- Be emphatic about the importance of having only JSON. If you really want Claude to care, you can put things in all caps – e.g., saying “DO NOT OUTPUT ANYTHING OTHER THAN VALID JSON. DON’T INCLUDE LEADING BACKTICKS LIKE ```json.”.
Talk about Claudeception... now even Claude itself knows that you have to YELL AT CLAUDE to get it to output JSON sometimes.
The API doesn't provide a mechanism for handling previous conversations, but Anthropic works round that by telling the artifact builder how to represent a prior conversation as a JSON encoded array:
Structure your prompt like this:
const conversationHistory = [ { role: "user", content: "Hello, Claude!" }, { role: "assistant", content: "Hello! How can I assist you today?" }, { role: "user", content: "I'd like to know about AI." }, { role: "assistant", content: "Certainly! AI, or Artificial Intelligence, refers to..." }, // ... ALL previous messages should be included here ]; const prompt = ` The following is the COMPLETE conversation history. You MUST consider ALL of these messages when formulating your response: ${JSON.stringify(conversationHistory)} IMPORTANT: Your response should take into account the ENTIRE conversation history provided above, not just the last message. Respond with a JSON object in this format: { "response": "Your response, considering the full conversation history", "sentiment": "brief description of the conversation's current sentiment" } Your entire response MUST be a single, valid JSON object. `; const response = await window.claude.complete(prompt);
There's another example in there showing how the state of play for a role playing game should be serialized as JSON and sent with every prompt as well.
The tool instructions acknowledge another limitation of the current Claude Artifacts environment: code that executes there is effectively invisible to the main LLM - error messages are not automatically round-tripped to the model. As a result it makes the following recommendation:
Using
window.claude.completemay involve complex orchestration across many different completion requests. Once you create an Artifact, you are not able to see whether or not your completion requests are orchestrated correctly. Therefore, you SHOULD ALWAYS test your completion requests first in the analysis tool before building an artifact.
I've already seen it do this in my own experiments: it will fire up the "analysis" tool (which allows it to run JavaScript directly and see the results) to perform a quick prototype before it builds the full artifact.
Here's my first attempt at an AI-enabled artifact: a translation app. I built it using the following single prompt:
Let’s build an AI app that uses Claude to translate from one language to another
Here's the transcript. You can try out the resulting app here - the app it built me looks like this:
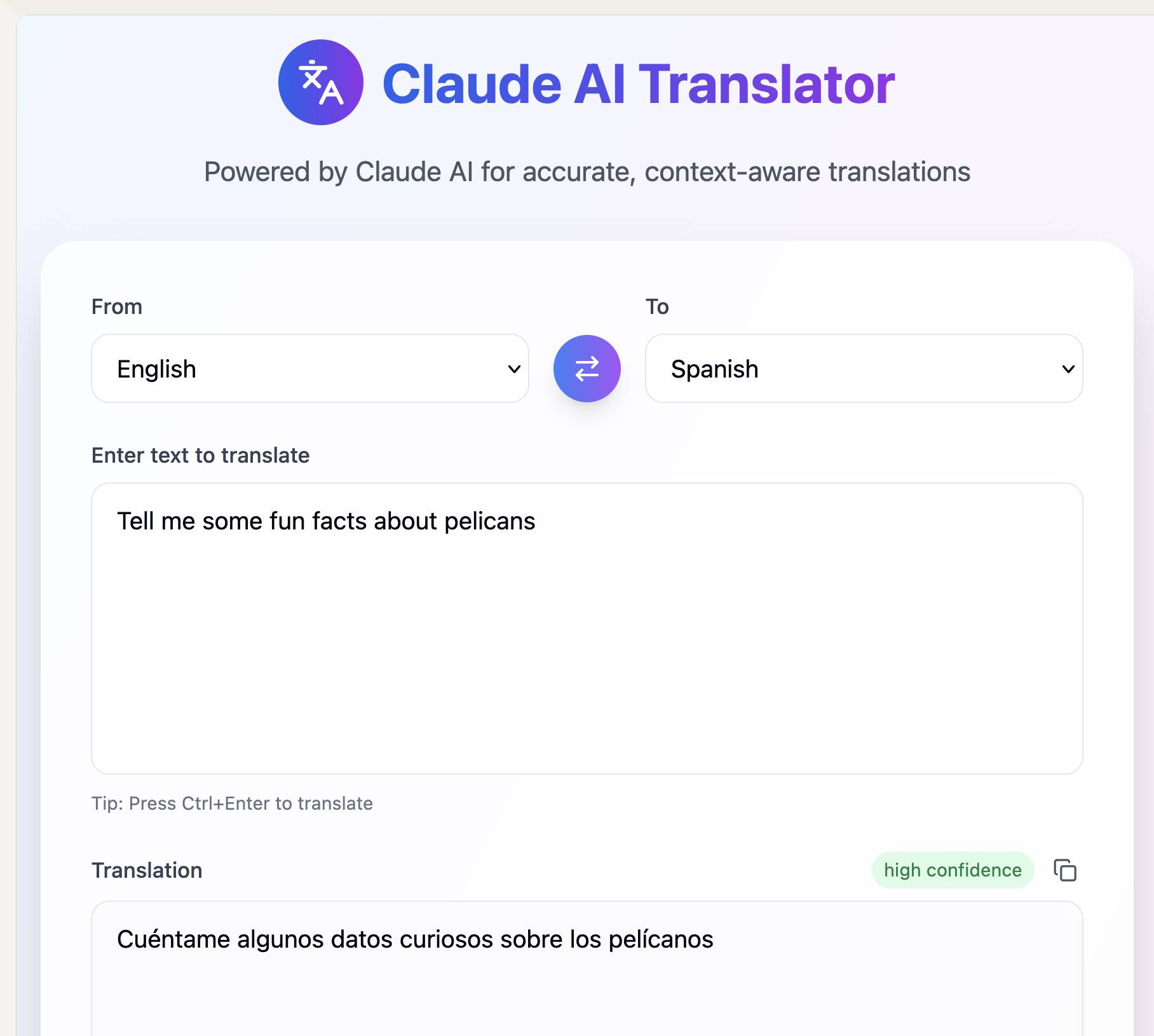
If you want to use this feature yourself you'll need to turn on "Create AI-powered artifacts" in the "Feature preview" section at the bottom of your "Settings -> Profile" section. I had to do that in the Claude web app as I couldn't find the feature toggle in the Claude iOS application. This claude.ai/settings/profile page should have it for your account.
Update 31st July 2025: Anthropic changed how this works. Here's details of the updated mechanism.