Thursday, 16th January 2025
100x Defect Tolerance: How Cerebras Solved the Yield Problem (via) I learned a bunch about how chip manufacture works from this piece where Cerebras reveal some notes about how they manufacture chips that are 56x physically larger than NVIDIA's H100.
The key idea here is core redundancy: designing a chip such that if there are defects the end-product is still useful. This has been a technique for decades:
For example in 2006 Intel released the Intel Core Duo – a chip with two CPU cores. If one core was faulty, it was disabled and the product was sold as an Intel Core Solo. Nvidia, AMD, and others all embraced this core-level redundancy in the coming years.
Modern GPUs are deliberately designed with redundant cores: the H100 needs 132 but the wafer contains 144, so up to 12 can be defective without the chip failing.
Cerebras designed their monster (look at the size of this thing) with absolutely tiny cores: "approximately 0.05mm2" - with the whole chip needing 900,000 enabled cores out of the 970,000 total. This allows 93% of the silicon area to stay active in the finished chip, a notably high proportion.
We've adjusted prompt caching so that you now only need to specify cache write points in your prompts - we'll automatically check for cache hits at previous positions. No more manual tracking of read locations needed.
— Alex Albert, Anthropic
Evolving GitHub Issues (public preview). GitHub just shipped the largest set of changes to GitHub Issues I can remember in a few years. As an Issues power-user this is directly relevant to me.
The big new features are sub-issues, issue types and boolean operators in search.
Sub-issues look to be a more robust formalization of the existing feature where you could create a - [ ] #123 Markdown list of issues in the issue description to relate issue together and track a 3/5 progress bar. There are now explicit buttons for creating a sub-issue and managing the parent relationship of such, and clicking a sub-issue opens it in a side panel on top of the parent.
Issue types took me a moment to track down: it turns out they are an organization level feature, so they won't show up on repos that belong to a specific user.
Organizations can define issue types that will be available across all of their repos. I created a "Research" one to classify research tasks, joining the default task, bug and feature types.
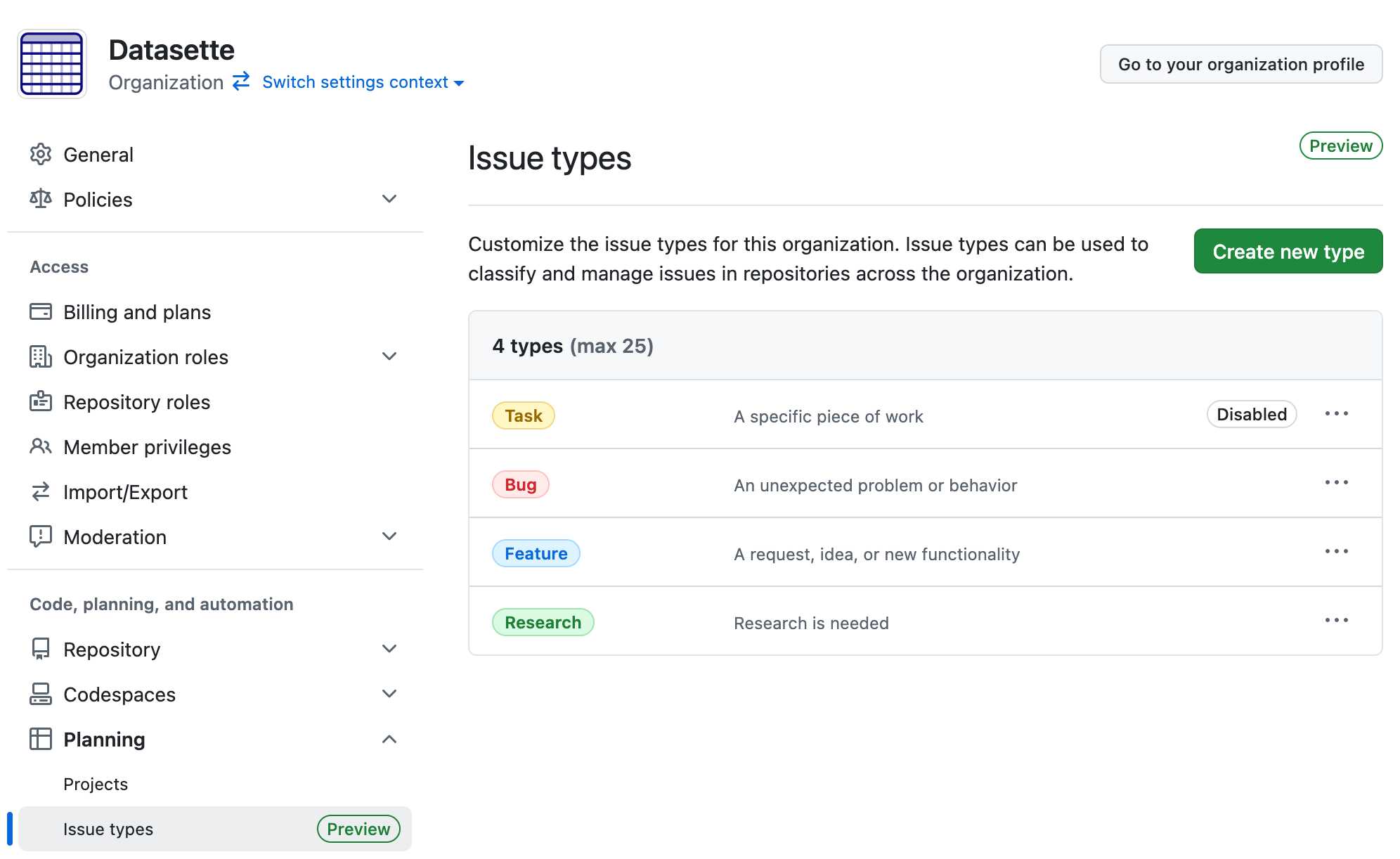
Unlike labels an issue can have just one issue type. You can then search for all issues of a specific type across an entire organization using org:datasette type:"Research" in GitHub search.
The new boolean logic in GitHub search looks like it could be really useful - it includes AND, OR and parenthesis for grouping.
(type:"Bug" AND assignee:octocat) OR (type:"Enhancement" AND assignee:hubot)
I'm not sure if these are available via the GitHub APIs yet.
Datasette Public Office Hours Application. We are running another Datasette Public Office Hours event on Discord tomorrow (Friday 17th January 2025) at 2pm Pacific / 5pm Eastern / 10pm GMT / more timezones here.
The theme this time around is lightning talks - we're looking for 5-8 minute long talks from community members about projects they are working on or things they have built using the Datasette family of tools (which includes LLM and sqlite-utils as well).
If you have a demo you'd like to share, please let us know via this form.
I'm going to be demonstrating my recent work on the next generation of Datasette Enrichments.
[...] much of the point of a model like o1 is not to deploy it, but to generate training data for the next model. Every problem that an o1 solves is now a training data point for an o3 (eg. any o1 session which finally stumbles into the right answer can be refined to drop the dead ends and produce a clean transcript to train a more refined intuition).
— gwern
Manual inspection of data has probably the highest value-to-prestige ratio of any activity in machine learning.
— Greg Brockman, OpenAI, Feb 2023