Experimenting with audio input and output for the OpenAI Chat Completion API
18th October 2024
OpenAI promised this at DevDay a few weeks ago and now it’s here: their Chat Completion API can now accept audio as input and return it as output. OpenAI still recommend their WebSocket-based Realtime API for audio tasks, but the Chat Completion API is a whole lot easier to write code against.
- Generating audio
- Audio input via a Bash script
- A web app for recording and prompting against audio
- The problem is the price
Generating audio
For the moment you need to use the new gpt-4o-audio-preview model. OpenAI tweeted this example:
curl https://api.openai.com/v1/chat/completions \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-4o-audio-preview",
"modalities": ["text", "audio"],
"audio": {
"voice": "alloy",
"format": "wav"
},
"messages": [
{
"role": "user",
"content": "Recite a haiku about zeros and ones."
}
]
}' | jq > response.jsonI tried running that and got back JSON with a HUGE base64 encoded block in it:
{
"id": "chatcmpl-AJaIpDBFpLleTUwQJefzs1JJE5p5g",
"object": "chat.completion",
"created": 1729231143,
"model": "gpt-4o-audio-preview-2024-10-01",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": null,
"refusal": null,
"audio": {
"id": "audio_6711f92b13a081908e8f3b61bf18b3f3",
"data": "UklGRsZr...AA==",
"expires_at": 1729234747,
"transcript": "Digits intertwine, \nIn dance of noughts and unity, \nCode's whispers breathe life."
}
},
"finish_reason": "stop",
"internal_metrics": []
}
],
"usage": {
"prompt_tokens": 17,
"completion_tokens": 181,
"total_tokens": 198,
"prompt_tokens_details": {
"cached_tokens": 0,
"cached_tokens_internal": 0,
"text_tokens": 17,
"image_tokens": 0,
"audio_tokens": 0
},
"completion_tokens_details": {
"reasoning_tokens": 0,
"text_tokens": 33,
"audio_tokens": 148
}
},
"system_fingerprint": "fp_6e2d124157"
}The full response is here—I’ve truncated that data field since the whole thing is 463KB long!
Next I used jq and base64 to save the decoded audio to a file:
cat response.json | jq -r '.choices[0].message.audio.data' \
| base64 -D > decoded.wavThat gave me a 7 second, 347K WAV file. I converted that to MP3 with the help of llm cmd and ffmpeg:
llm cmd ffmpeg convert decoded.wav to code-whispers.mp3
> ffmpeg -i decoded.wav -acodec libmp3lame -b:a 128k code-whispers.mp3That gave me a 117K MP3 file.
The "usage" field above shows that the output used 148 audio tokens. OpenAI’s pricing page says audio output tokens are $200/million, so I plugged that into my LLM pricing calculator and got back a cost of 2.96 cents.
Update 27th October 2024: I built an HTML and JavaScript tool for experimenting with audio output in a browser.
Audio input via a Bash script
Next I decided to try the audio input feature. You can now embed base64 encoded WAV files in the list of messages you send to the model, similar to how image inputs work.
I started by pasting a curl example of audio input into Claude and getting it to write me a Bash script wrapper. Here’s the full audio-prompt.sh script. The part that does the work (after some argument parsing) looks like this:
# Base64 encode the audio file
AUDIO_BASE64=$(base64 < "$AUDIO_FILE" | tr -d '\n')
# Construct the JSON payload
JSON_PAYLOAD=$(jq -n \
--arg model "gpt-4o-audio-preview" \
--arg text "$TEXT_PROMPT" \
--arg audio "$AUDIO_BASE64" \
'{
model: $model,
modalities: ["text"],
messages: [
{
role: "user",
content: [
{type: "text", text: $text},
{
type: "input_audio",
input_audio: {
data: $audio,
format: "wav"
}
}
]
}
]
}')
# Make the API call
curl -s "https://api.openai.com/v1/chat/completions" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d "$JSON_PAYLOAD" | jq .From the documentation it looks like you can send an "input_audio"."format" of either "wav" or "mp3".
You can run it like this:
./audio-prompt.sh 'describe this audio' decoded.wavThis dumps the raw JSON response to the console. Here’s what I got for that sound clip I generated above, which gets a little creative:
The audio features a spoken phrase that is poetic in nature. It discusses the intertwining of “digits” in a coordinated and harmonious manner, as if engaging in a dance of unity. It mentions “codes” in a way that suggests they have an almost life-like quality. The tone seems abstract and imaginative, possibly metaphorical, evoking imagery related to technology or numbers.
A web app for recording and prompting against audio
I decided to turn this into a tiny web application. I started by asking Claude to create a prototype with a “record” button, just to make sure that was possible:
Build an artifact - no React - that lets me click a button to start recording, shows a counter running up, then lets me click again to stop. I can then play back the recording in an audio element. The recording should be a WAV
Then I pasted in one of my curl experiments from earlier and told it:
Now add a textarea input called "prompt" and a button which, when clicked, submits the prompt and the base64 encoded audio file usingfetch()to this URL
The JSON that comes back should be displayed on the page, pretty-printed
The API key should come from localStorage - if localStorage does not have it ask the user for it with prompt()
I iterated through a few error messages and got to a working application! I then did one more round with Claude to add a basic pricing calculator showing how much the prompt had cost to run.
You can try the finished application here:
tools.simonwillison.net/openai-audio
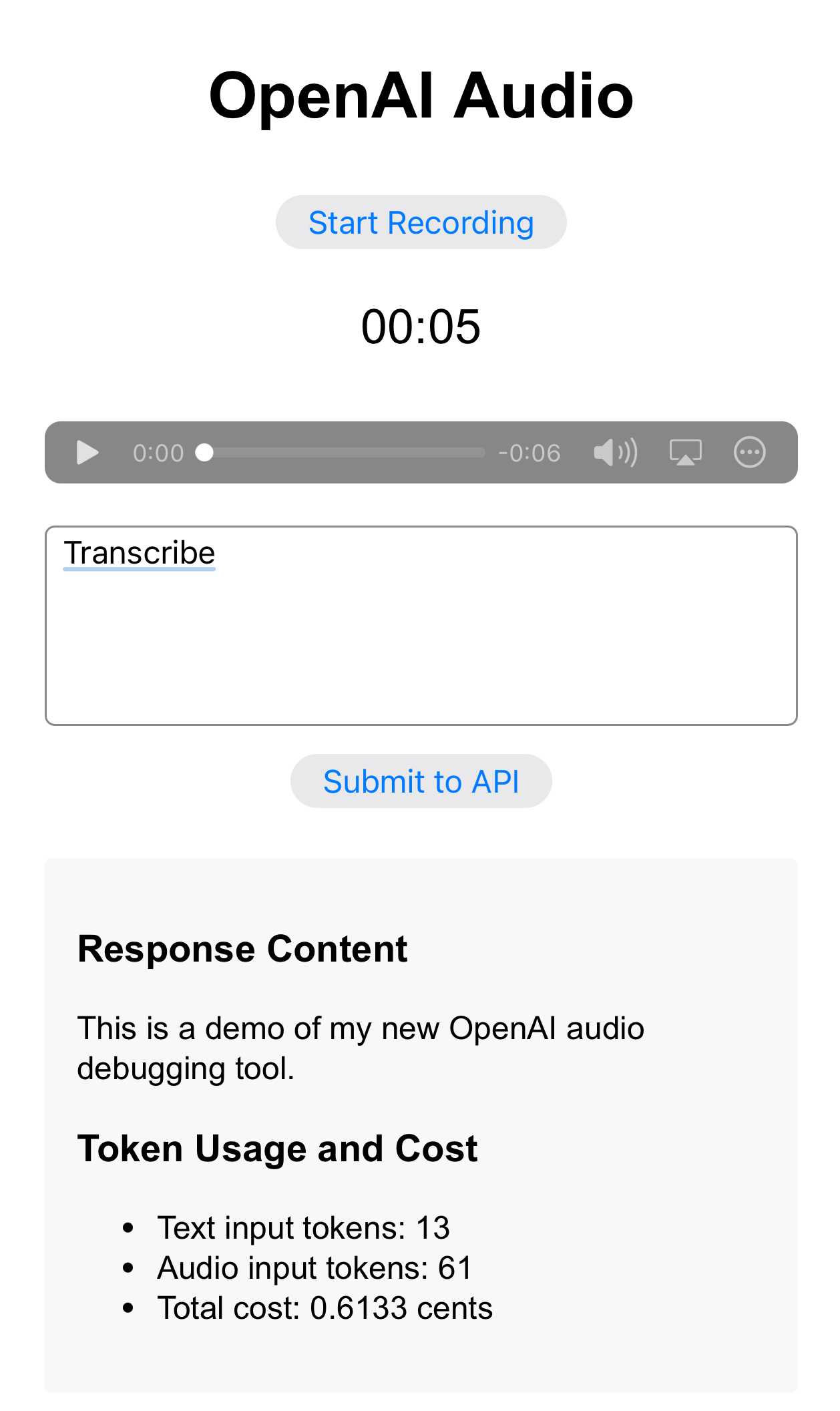
Here’s the finished code. It uses all sorts of APIs I’ve never used before: AudioContext().createMediaStreamSource(...) and a DataView() to build the WAV file from scratch, plus a trick with FileReader() .. readAsDataURL() for in-browser base64 encoding.
Audio inputs are charged at $100/million tokens, and processing 5 seconds of audio her cost 0.6 cents.
The problem is the price
Audio tokens are currently charged at $100/million for input and $200/million for output. Tokens are hard to reason about, but a note on the pricing page clarifies that:
Audio input costs approximately 6¢ per minute; Audio output costs approximately 24¢ per minute
Translated to price-per-hour, that’s $3.60 per hour of input and $14.40 per hour of output. I think the Realtime API pricing is about the same. These are not cheap APIs.
Meanwhile, Google’s Gemini models price audio at 25 tokens per second (for input only, they don’t yet handle audio output). That means that for their three models:
- Gemini 1.5 Pro is $1.25/million input tokens, so $0.11 per hour
- Gemini 1.5 Flash is $0.075/milllion, so $0.00675 per hour (that’s less than a cent)
- Gemini 1.5 Flash 8B is $0.0375/million, so $0.003375 per hour (a third of a cent!)
This means even Google’s most expensive Pro model is still 32 times less costly than OpenAI’s gpt-4o-audio-preview model when it comes to audio input, and Flash 8B is 1,066 times cheaper.
(I really hope I got those numbers right. I had ChatGPT double-check them. I keep find myself pricing out Gemini and not believing the results.)
I’m going to cross my fingers and hope for an OpenAI price drop in the near future, because it’s hard to justify building anything significant on top of these APIs at the current price point, especially given the competition.
Update 17th December 2024: OpenAI released a significant price drop for their realtime audio models—60% lower audio token costs, and a new API based on GPT-4o mini that’s cheaper still.
More recent articles
- The Axios supply chain attack used individually targeted social engineering - 3rd April 2026
- Highlights from my conversation about agentic engineering on Lenny's Podcast - 2nd April 2026
- Mr. Chatterbox is a (weak) Victorian-era ethically trained model you can run on your own computer - 30th March 2026