Building a tool showing how Gemini Pro can return bounding boxes for objects in images
26th August 2024
I was browsing through Google’s Gemini documentation while researching how different multi-model LLM APIs work when I stumbled across this note in the vision documentation:
You can ask the model for the coordinates of bounding boxes for objects in images. For object detection, the Gemini model has been trained to provide these coordinates as relative widths or heights in range
[0,1], scaled by 1000 and converted to an integer. Effectively, the coordinates given are for a 1000x1000 version of the original image, and need to be converted back to the dimensions of the original image.
This is a pretty neat capability! OpenAI’s GPT-4o and Anthropic’s Claude 3 and Claude 3.5 models can’t do this (yet).
I tried a few prompts using Google’s Python library and got back what looked like bounding boxes!
>>> import google.generativeai as genai
>>> genai.configure(api_key="...")
>>> model = genai.GenerativeModel(model_name="gemini-1.5-pro-latest")
>>> import PIL.Image
>>> goats = PIL.Image.open("/tmp/goats.jpeg")
>>> prompt = 'Return bounding boxes around every goat, for each one return [ymin, xmin, ymax, xmax]'
>>> response = model.generate_content([goats, prompt])
print(response.text)
>>> print(response.text)
- [200, 90, 745, 527]
- [300, 610, 904, 937]But how to verify that these were useful co-ordinates? I fired up Claude 3.5 Sonnet and started iterating on Artifacts there to try and visualize those co-ordinates against the original image.
After some fiddling around, I built an initial debug tool that I could paste co-ordinates into and select an image and see that image rendered.
A tool for prompting with an image and rendering the bounding boxes
I wrote the other day about Anthropic’s new support for CORS headers, enabling direct browser access to their APIs.
Google Gemini supports CORS as well! So do OpenAI, which means that all three of the largest LLM providers can now be accessed directly from the browser.
I decided to build a combined tool that could prompt Gemini 1.5 Pro with an image directly from the browser, then render the returned bounding boxes on that image.
The new tool lives here: https://tools.simonwillison.net/gemini-bbox
![Gemini API Image Bounding Box Visualization - browse for file goats.jpeg, prompt is Return bounding boxes as JSON arrays [ymin, xmin, ymax, xmax] - there follows output coordinates and then a red and a green box around the goats in a photo, with grid lines showing the coordinates from 0-1000 on both axes](https://static.simonwillison.net/static/2024/goats-bbox-fixed.jpg)
The first time you run a prompt it will ask you for a Gemini API key, which it stores in your browser’s localStorage. I promise not to add code that steals your keys in the future, but if you don’t want to trust that you can grab a copy of the code, verify it and then run it yourself.
Building this tool with Claude 3.5 Sonnet
This is yet another example of a tool that I mostly built by prompting Claude 3.5 Sonnet. Here are some more.
I started out with this lengthy conversation (transcript exported with this tool) to help build the original tool for opening an image and pasting in those bounding box coordinates. That sequence started like this:
Build an artifact where I can open an image from my browser and paste the following style of text into a textarea:
- [488, 945, 519, 999] - [460, 259, 487, 307] - [472, 574, 498, 612](The hyphens may not be there, so scan with a regex for [ num, num, num, num ])
Each of those represent [ymin, xmin, ymax, xmax] coordinates on the image—but they are numbers between 0 and 1000 so they correspond to the image is if it had been resized to 1000x1000
As soon as the coords are pasted the corresponding boxes should be drawn on the images, corrected for its actual dimensions
The image should be show with a width of 80% of the page
The boxes should be in different colours, and hovering over each box should show the original bounding box coordinates below the image
Once that tool appeared to be doing the right thing (I had to muck around with how the coordinates were processed a bunch) I used my favourite prompting trick to build the combined tool that called the Gemini API. I found this example that calls the @google/generative-ai API from a browser, pasted the full example into Claude along with my previous bounding box visualization tool and had it combine them to achieve the desired result:
Based on that example text, build me an HTML page with Vanilla JS that loads the Gemini API from esm.run—it should have a file input and a textarea and a submit button—you attach an image, enter a prompt and then click the button and it does a Gemini prompt with that image and prompt and injects the returned result into a div on the page
Then this follow-up prompt:
now incorporate the logic from this tool (I pasted in that HTML too), such that when the response is returned from the prompt the image is displayed with any rendered bounding boxes
Dealing with image orientation bugs
Bounding boxes are fiddly things. The code I had produced above seemed to work... but in some of my testing the boxes didn’t show up in quite the right place. Was this just Gemini 1.5 Pro being unreliable in how it returned the boxes? That seemed likely, but I had some nagging doubts.
On a hunch, I took an image that was behaving strangely, took a screenshot of it and tried that screenshot as a JPEG. The bounding boxes that came back were different—they appeared rotated!
{kind=link}
{kind=link}
I’ve seen this kind of thing before with photos taken on an iPhone. There’s an obscure piece of JPEG metadata which can set the orientation on a photo, and some software fails to respect that.
Was that affecting my bounding box tool? I started digging into those photos to figure that out, using a combination of ChatGPT Code Interpreter (since that can read JPEG binary data using Python) and Claude Artifacts (to build me a visible UI for exploring my photos).
My hunch turned out to be correct: my iPhone photos included TIFF orientation metadata which the Gemini API appeared not to respect. As a result, some photos taken by my phone would return bounding boxes that were rotated 180 degrees.
My eventual fix was to take the image provided by the user, render it to a <canvas> element and then export it back out as a JPEG again—code here. I got Claude to add that for me based on code I pasted in from my earlier image resize quality tool, also built for me by Claude.
As part of this investigation I built another tool, which can read orientation TIFF data from a JPEG entirely in JavaScript and help show what’s going on:
https://tools.simonwillison.net/tiff-orientation
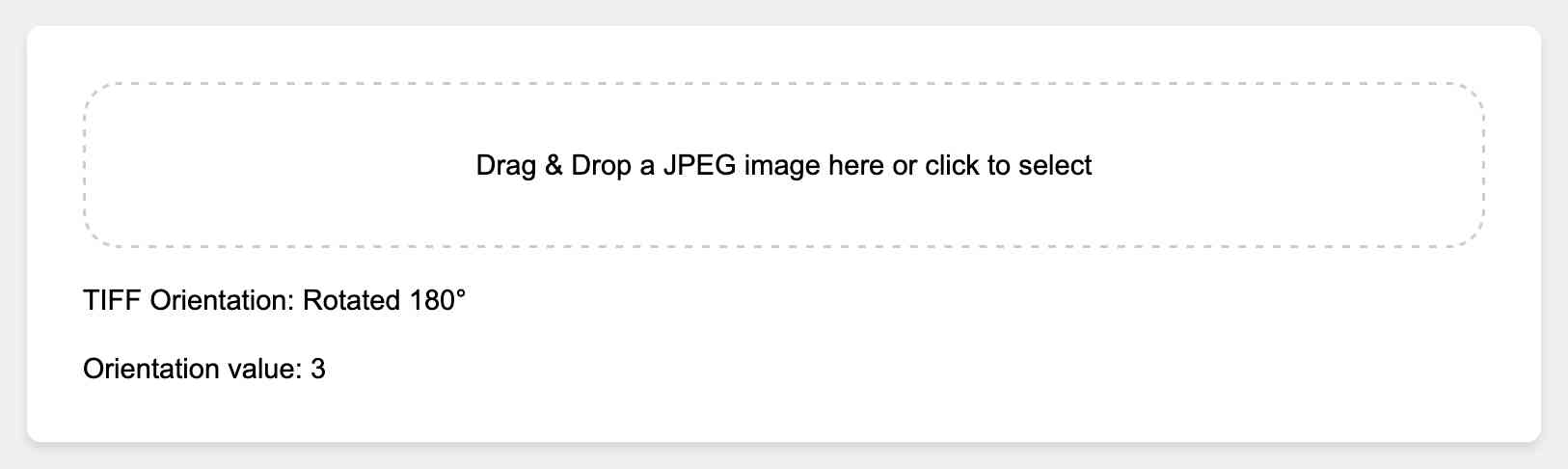
Here’s the source code for that. The source code is a great example of the kind of thing that LLMs can do much more effectively than I can—here’s an illustrative snippet:
// Determine endianness
const endian = view.getUint16(tiffStart, false);
const isLittleEndian = (endian === 0x4949); // 'II' in ASCII
debugInfo += `Endianness: ${isLittleEndian ? 'Little Endian' : 'Big Endian'}\n`;
// Check TIFF header validity
const tiffMagic = view.getUint16(tiffStart + 2, isLittleEndian);
if (tiffMagic !== 42) {
throw Object.assign(new Error('Not a valid TIFF header'), { debugInfo });
}
debugInfo += 'Valid TIFF header\n';
// Get offset to first IFD
const ifdOffset = view.getUint32(tiffStart + 4, isLittleEndian);
const ifdStart = tiffStart + ifdOffset;
debugInfo += `IFD start: ${ifdStart}\n`;LLMs know their binary file formats, so I frequently find myself asking them to write me custom binary processing code like this.
Here’s the Claude conversation I had to build that tool. After failing to get it to work several times I pasted in Python code that I’d built using ChatGPT Code Interpreter and prompted:
Here’s Python code that finds it correctly:
Which turned out to provide the missing details to help it build me the JavaScript version I could run in my browser. Here’s the ChatGPT conversation that got me that Python code.
Mixing up a whole bunch of models
This whole process was very messy, but it’s a pretty accurate representation of my workflow when using these models. I used three different tools here:
- Gemini 1.5 Pro and the Gemini API to take images and a prompt and return bounding boxes
- Claude 3.5 Sonnet and Claude Artifacts to write code for working against that API and build me interactive tools for visualizing the results
- GPT-4o and ChatGPT Code Interpreter to write and execute Python code to try and help me figure out what was going on with my weird JPEG image orientation bugs
I copied code between models a bunch of times too—pasting Python code written by GPT-4o into Claude 3.5 Sonnet to help it write the correct JavaScript for example.
How good is the code that I produced by the end of this all? It honestly doesn’t matter very much to me: this is a very low-stakes project, where the goal was a single web page tool that can run a prompt through a model and visualize the response.
If I was writing code “for production”—for a long-term project, or code that I intended to package up and release as an open source library—I would sweat the details a whole lot more. But for this kind of exploratory and prototyping work I’m increasingly comfortable hacking away at whatever the models spit out until it achieves the desired effect.
More recent articles
- The Axios supply chain attack used individually targeted social engineering - 3rd April 2026
- Highlights from my conversation about agentic engineering on Lenny's Podcast - 2nd April 2026
- Mr. Chatterbox is a (weak) Victorian-era ethically trained model you can run on your own computer - 30th March 2026