Could you train a ChatGPT-beating model for $85,000 and run it in a browser?
17th March 2023
I think it’s now possible to train a large language model with similar functionality to GPT-3 for $85,000. And I think we might soon be able to run the resulting model entirely in the browser, and give it capabilities that leapfrog it ahead of ChatGPT.
This is currently wild speculation on my part, but bear with me because I think this is worth exploring further.
Large language models with GPT-3-like capabilities cost millions of dollars to build, thanks to the cost of running the expensive GPU servers needed to train them. Whether you are renting or buying those machines, there are still enormous energy costs to cover.
Just one example of this: the BLOOM large language model was trained in France with the support of the French government. The cost was estimated as $2-5M, it took almost four months to train and boasts about its low carbon footprint because most of the power came from a nuclear reactor!
[ Fun fact: as of a few days ago you can now run the openly licensed BLOOM on your own laptop, using Nouamane Tazi’s adaptive copy of the llama.cpp code that made that possible for LLaMA ]
Recent developments have made me suspect that these costs could be made dramatically lower. I think a capable language model can now be trained from scratch for around $85,000.
It’s all about that LLaMA
The LLaMA plus Alpaca combination is the key here.
I wrote about these two projects previously:
- Large language models are having their Stable Diffusion moment discusses the significance of LLaMA
- Stanford Alpaca, and the acceleration of on-device large language model development describes Alpaca
To recap: LLaMA by Meta research provided a GPT-3 class model trained entirely on documented, available public training information, as opposed to OpenAI’s continuing practice of not revealing the sources of their training data.
This makes the model training a whole lot more likely to be replicable by other teams.
The paper also describes some enormous efficiency improvements they made to the training process.
The LLaMA research was still extremely expensive though. From the paper:
... we estimate that we used 2048 A100-80GB for a period of approximately 5 months to develop our models
My friends at Replicate told me that a simple rule of thumb for A100 cloud costs is $1/hour.
2048 * 5 * 30 * 24 = $7,372,800
But... that $7M was the cost to both iterate on the model and to train all four sizes of LLaMA that they tried: 7B, 13B, 33B, and 65B.
Here’s Table 15 from the paper, showing the cost of training each model.
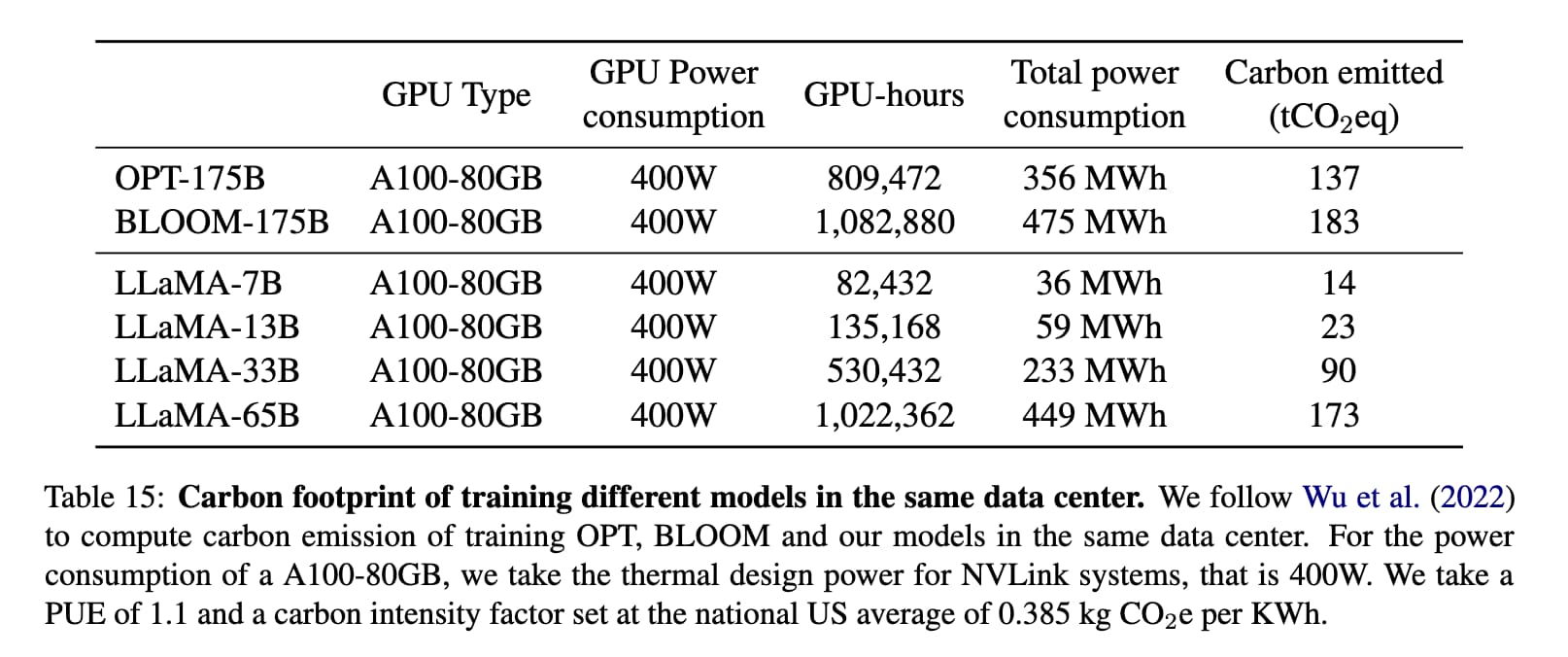
This shows that the smallest model, LLaMA-7B, was trained on 82,432 hours of A100-80GB GPUs, costing 36MWh and generating 14 tons of CO2.
(That’s about 28 people flying from London to New York.)
Going by the $1/hour rule of thumb, this means that provided you get everything right on your first run you can train a LLaMA-7B scale model for around $82,432.
Upgrading to Alpaca
You can run LLaMA 7B on your own laptop (or even on a phone), but you may find it hard to get good results out of. That’s because it hasn’t been instruction tuned, so it’s not great at answering the kind of prompts that you might send to ChatGPT or GPT-3 or 4.
Alpaca is the project from Stanford that fixes that. They fine-tuned LLaMA on 52,000 instructions (of somewhat dubious origin) and claim to have gotten ChatGPT-like performance as a result... from that smallest 7B LLaMA model!
You can try out their demo (update: no you can’t, “Our live demo is suspended until further notice”) and see for yourself that it really does capture at least some of that ChatGPT magic.
The best bit? The Alpaca fine-tuning can be done for less than $100. The Replicate team have repeated the training process and published a tutorial about how they did it.
Other teams have also been able to replicate the Alpaca fine-tuning process, for example antimatter15/alpaca.cpp on GitHub.
We are still within our $85,000 budget! And Alpaca—or an Alpaca-like model using different fine tuning data—is the ChatGPT on your own device model that we’ve all been hoping for.
Could we run it in a browser?
Alpaca is effectively the same size as LLaMA 7B—around 3.9GB (after 4-bit quantization ala llama.cpp). And LLaMA 7B has already been shown running on a whole bunch of different personal devices: laptops, Raspberry Pis (very slowly) and even a Pixel 5 phone at a decent speed!
The next frontier: running it in the browser.
I saw two tech demos yesterday that made me think this may be possible in the near future.
The first is Transformers.js. This is a WebAssembly port of the Hugging Face Transformers library of models—previously only available for server-side Python.
It’s worth spending some time with their demos, which include some smaller language models and some very impressive image analysis languages too.
The second is Web Stable Diffusion. This team managed to get the Stable Diffusion generative image model running entirely in the browser as well!
Web Stable Diffusion uses WebGPU, a still emerging standard that’s currently only working in Chrome Canary. But it does work! It rendered me this image of two raccoons eating a pie in the forest in 38 seconds.
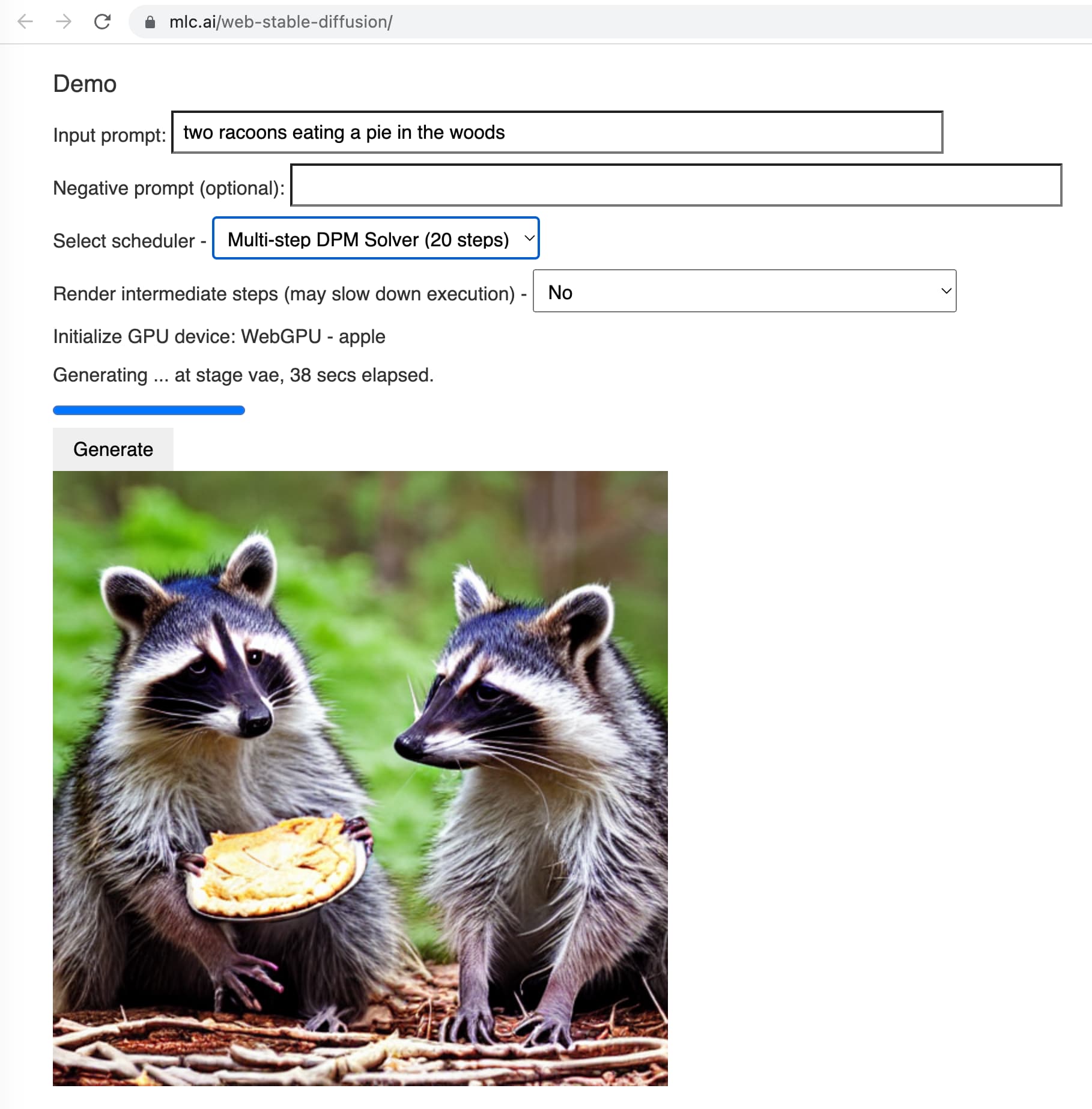
The Stable Diffusion model this loads into the browser is around 1.9GB.
LLaMA/Alpaca at 4bit quantization is 3.9GB.
The sizes of these two models are similar enough that I would not be at all surprised to see an Alpaca-like model running in the browser in the not-too-distant future. I wouldn’t be surprised if someone is working on that right now.
Now give it extra abilities with ReAct
A model running in your browser that behaved like a less capable version of ChatGPT would be pretty impressive. But what if it could be MORE capable than ChatGPT?
The ReAct prompt pattern is a simple, proven way of expanding a language model’s abilities by giving it access to extra tools.
Matt Webb explains the significance of the pattern in The surprising ease and effectiveness of AI in a loop.
I got it working with a few dozen lines of Python myself, which I described in A simple Python implementation of the ReAct pattern for LLMs.
Here’s the short version: you tell the model that it must think out loud and now has access to tools. It can then work through a question like this:
Question: Population of Paris, squared?
Thought: I should look up the population of paris and then multiply it
Action: search_wikipedia: Paris
Then it stops. Your code harness for the model reads that last line, sees the action and goes and executes an API call against Wikipedia. It continues the dialog with the model like this:
Observation: <truncated content from the Wikipedia page, including the 2,248,780 population figure>
The model continues:
Thought: Paris population is 2,248,780 I should square that
Action: calculator: 2248780 ** 2
Control is handed back to the harness, which passes that to a calculator and returns:
Observation: 5057011488400
The model then provides the answer:
Answer: The population of Paris squared is 5,057,011,488,400
Adding new actions to this system is trivial: each one can be a few lines of code.
But as the ReAct paper demonstrates, adding these capabilities to even an under-powered model (such as LLaMA 7B) can dramatically improve its abilities, at least according to several common language model benchmarks.
This is essentially what Bing is! It’s GPT-4 with the added ability to run searches against the Bing search index.
Obviously if you’re going to give a language model the ability to execute API calls and evaluate code you need to do it in a safe environment! Like for example... a web browser, which runs code from untrusted sources as a matter of habit and has the most thoroughly tested sandbox mechanism of any piece of software we’ve ever created.
Adding it all together
There are a lot more groups out there that can afford to spend $85,000 training a model than there are that can spend $2M or more.
I think LLaMA and Alpaca are going to have a lot of competition soon, from an increasing pool of openly licensed models.
A fine-tuned LLaMA scale model is leaning in the direction of a ChatGPT competitor already. But... if you hook in some extra capabilities as seen in ReAct and Bing even that little model should be able to way outperform ChatGPT in terms of actual ability to solve problems and do interesting things.
And we might be able to run such a thing on our phones... or even in our web browsers... sooner than you think.
And it’s only going to get cheaper
H100s are shipping and you can half this again. Twice (or more) if fp8 works.
- tobi lutke (@tobi) March 17, 2023
The H100 is the new Tensor Core GPU from NVIDIA, which they claim can offer up to a 30x performance improvement over their current A100s.
More recent articles
- Vibe coding SwiftUI apps is a lot of fun - 27th March 2026
- Experimenting with Starlette 1.0 with Claude skills - 22nd March 2026
- Profiling Hacker News users based on their comments - 21st March 2026