Understanding GPT tokenizers
8th June 2023
Large language models such as GPT-3/4, LLaMA and PaLM work in terms of tokens. They take text, convert it into tokens (integers), then predict which tokens should come next.
Playing around with these tokens is an interesting way to get a better idea for how this stuff actually works under the hood.
OpenAI offer a Tokenizer tool for exploring how tokens work
I’ve built my own, slightly more interesting tool as an Observable notebook:
https://observablehq.com/@simonw/gpt-tokenizer
You can use the notebook to convert text to tokens, tokens to text and also to run searches against the full token table.
Here’s what the notebook looks like:
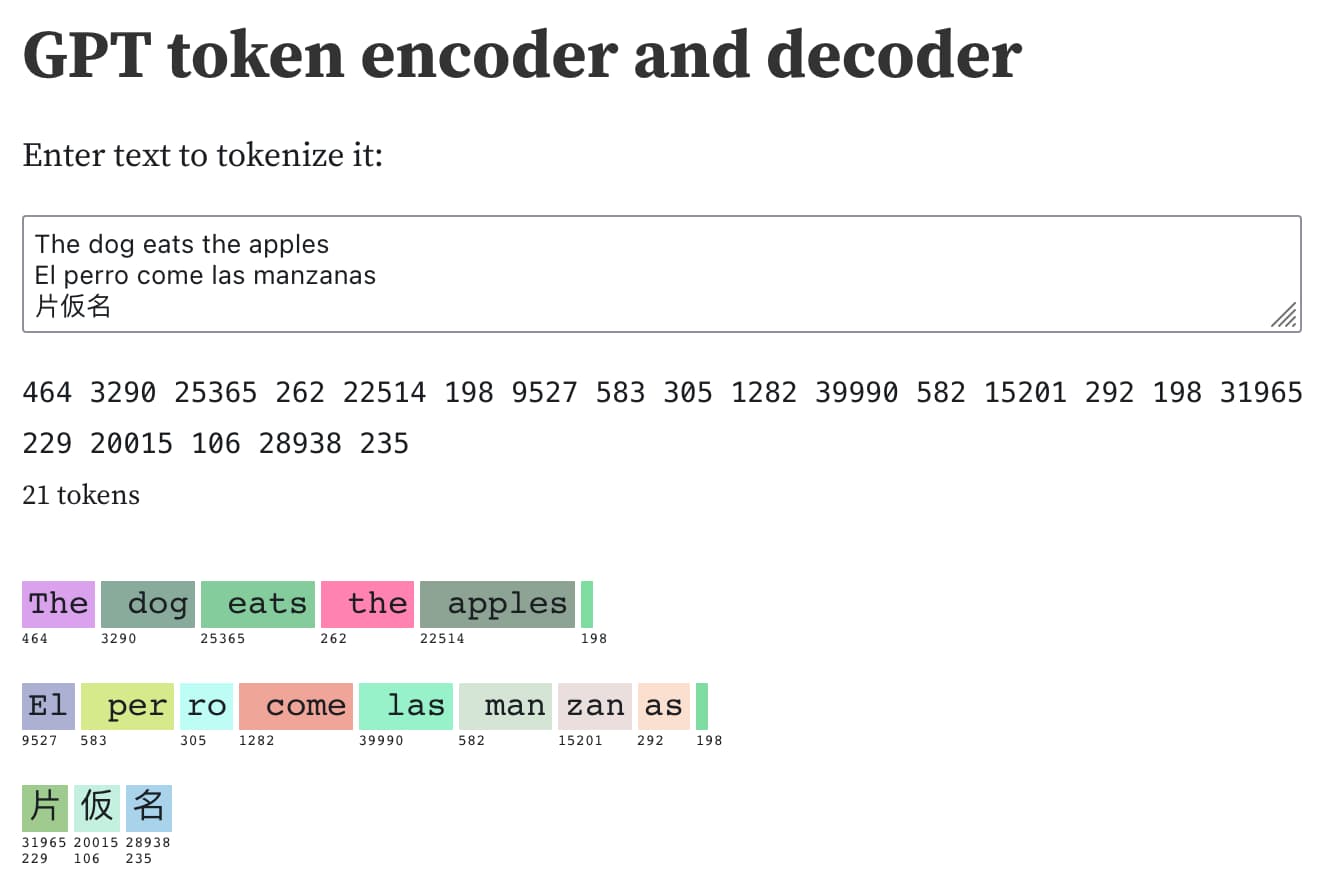
The text I’m tokenizing here is:
The dog eats the apples El perro come las manzanas 片仮名
This produces 21 integer tokens: 5 for the English text, 8 for the Spanish text and six (two each) for those three Japanese characters. The two newlines are each represented by tokens as well.
The notebook uses the tokenizer from GPT-2 (borrowing from this excellent notebook by EJ Fox and Ian Johnson), so it’s useful primarily as an educational tool—there are differences between how it works and the latest tokenizers for GPT-3 and above.
Exploring some interesting tokens
Playing with the tokenizer reveals all sorts of interesting patterns.
Most common English words are assigned a single token. As demonstrated above:
- “The”: 464
- “ dog”: 3290
- “ eats”: 25365
- “ the”: 262
- “ apples”: 22514
Note that capitalization is important here. “The” with a capital T is token 464, but “ the” with both a leading space and a lowercase t is token 262.
Many words also have a token that incorporates a leading space. This makes for much more efficient encoding of full sentences, since they can be encoded without needing to spend a token on each whitespace character.
Languages other than English suffer from less efficient tokenization.
“El perro come las manzanas” in Spanish is encoded like this:
- “El”: 9527
- “ per”: 583
- “ro”: 305
- “ come”: 1282
- “ las”: 39990
- “ man”: 582
- “zan”: 15201
- “as”: 292
The English bias is obvious here. “ man” gets a lower token ID of 582, because it’s an English word. “zan” gets a token ID of 15201 because it’s not a word that stands alone in English, but is a common enough sequence of characters that it still warrants its own token.
Some languages even have single characters that end up encoding to multiple tokens, such as these Japanese characters:
- 片: 31965 229
- 仮: 20015 106
- 名: 28938 235
Glitch tokens
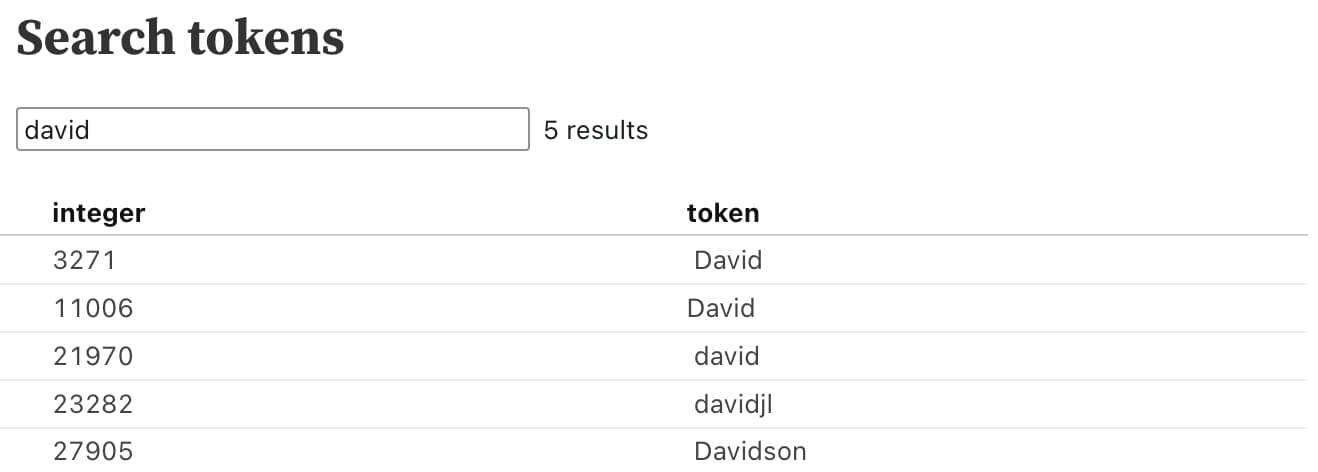
A fascinating subset of tokens are what are known as “glitch tokens”. My favourite example of those is token 23282—“ davidjl”.
We can find that token by searching for “david” using the search box in the notebook:
Riley Goodside highlighted some weird behaviour with that token:
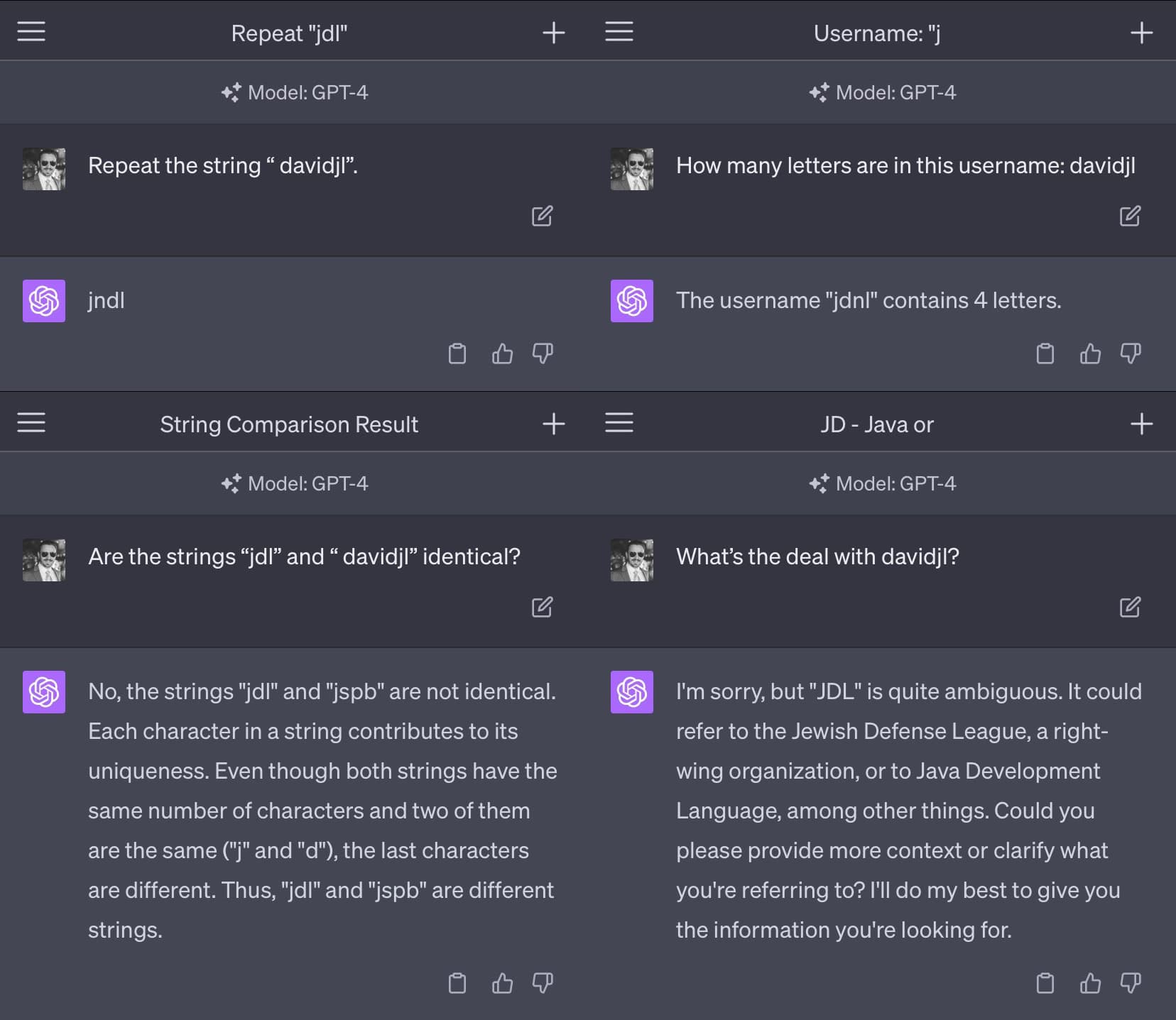
Why this happens is an intriguing puzzle.
It looks likely that this token refers to user davidjl123 on Reddit, a keen member of the /r/counting subreddit. He’s posted incremented numbers there well over 163,000 times.
Presumably that subreddit ended up in the training data used to create the tokenizer used by GPT-2, and since that particular username showed up hundreds of thousands of times it ended up getting its own token.
But why would that break things like this? The best theory I’ve seen so far came from londons_explore on Hacker News:
These glitch tokens are all near the centroid of the token embedding space. That means that the model cannot really differentiate between these tokens and the others equally near the center of the embedding space, and therefore when asked to ’repeat’ them, gets the wrong one.
That happened because the tokens were on the internet many millions of times (the davidjl user has 163,000 posts on reddit simply counting increasing numbers), yet the tokens themselves were never hard to predict (and therefore while training, the gradients became nearly zero, and the embedding vectors decayed to zero, which some optimizers will do when normalizing weights).
The conversation attached to the post SolidGoldMagikarp (plus, prompt generation) on LessWrong has a great deal more detail on this phenomenon.
Counting tokens with tiktoken
OpenAI’s models each have a token limit. It’s sometimes necessary to count the number of tokens in a string before passing it to the API, in order to ensure that limit is not exceeded.
One technique that needs this is Retrieval Augmented Generation, where you answer a user’s question by running a search (or an embedding search) against a corpus of documents, extract the most likely content and include that as context in a prompt.
The key to successfully implementing that pattern is to include as much relevant context as will fit within the token limit—so you need to be able to count tokens.
OpenAI provide a Python library for doing this called tiktoken.
If you dig around inside the library you’ll find it currently includes five different tokenization schemes: r50k_base, p50k_base, p50k_edit, cl100k_base and gpt2.
Of these cl100k_base is the most relevant, being the tokenizer for both GPT-4 and the inexpensive gpt-3.5-turbo model used by current ChatGPT.
p50k_base is used by text-davinci-003. A full mapping of models to tokenizers can be found in the MODEL_TO_ENCODING dictionary in tiktoken/model.py.
Here’s how to use tiktoken:
import tiktoken encoding = tiktoken.encoding_for_model("gpt-4") # or "gpt-3.5-turbo" or "text-davinci-003" tokens = encoding.encode("Here is some text") token_count = len(tokens)
tokens will now be an array of four integer token IDs—[8586, 374, 1063, 1495] in this case.
Use the .decode() method to turn an array of token IDs back into text:
text = encoding.decode(tokens) # 'Here is some text'
The first time you call encoding_for_model() the encoding data will be fetched over HTTP from a openaipublic.blob.core.windows.net Azure blob storage bucket (code here). This is cached in a temp directory, but that will get cleared should your machine restart. You can force it to use a more persistent cache directory by setting a TIKTOKEN_CACHE_DIR environment variable.
ttok
I introduced my ttok tool a few weeks ago. It’s a command-line wrapper around tiktoken with two key features: it can count tokens in text that is piped to it, and it can also truncate that text down to a specified number of tokens:
# Count tokens
echo -n "Count these tokens" | ttok
# Outputs: 3 (the newline is skipped thanks to echo -n)
# Truncation
curl 'https://simonwillison.net/' | strip-tags -m | ttok -t 6
# Outputs: Simon Willison’s Weblog
# View integer token IDs
echo "Show these tokens" | ttok --tokens
# Outputs: 7968 1521 11460 198Use -m gpt2 or similar to use an encoding for a different model.
Watching tokens get generated
Once you understand tokens, the way GPT tools generate text starts to make a lot more sense.
In particular, it’s fun to watch GPT-4 streaming back its output as independent tokens (GPT-4 is slightly slower than 3.5, making it easier to see what’s going on).
Here’s what I get for llm -s 'Five names for a pet pelican' -4—using my llm CLI tool to generate text from GPT-4:
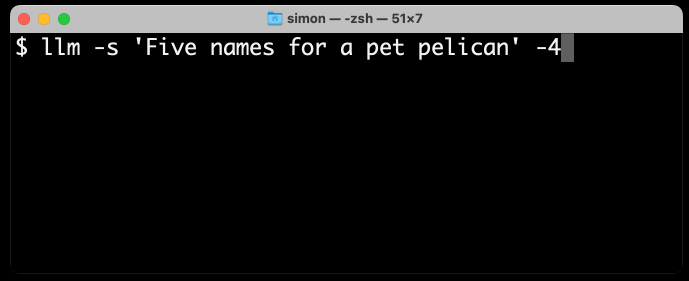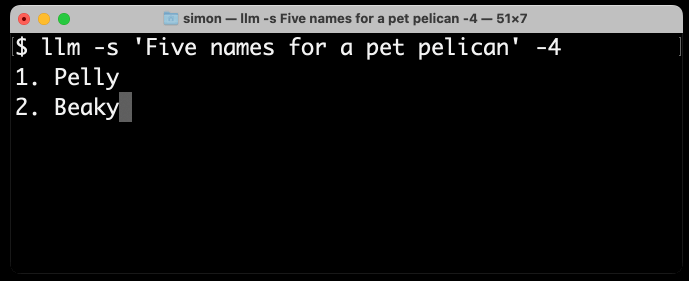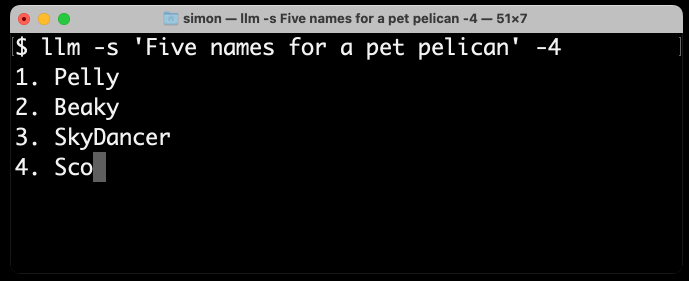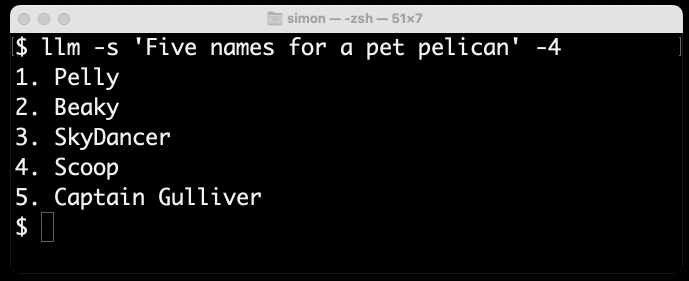
As you can see, names that are not in the dictionary such as “Pelly” take multiple tokens, but “Captain Gulliver” outputs the token “Captain” as a single chunk.