Weeknotes: Joining the board of the Python Software Foundation
30th July 2022
A few weeks ago I was elected to the board of directors for the Python Software Foundation.
I put myself up for election partly because I’ve found myself saying “I wish the PSF would help with ...” a few times over the years, and realized that joining the board could be a more useful way to actively participate, rather than shouting from the sidelines.
I was quite surprised to win. I wrote up a short manifesto—you can see that here—but the voting system lets voters select as many candidates as they like, so it’s possible I got in more on broad name recognition among the voters than based on what I wrote. I don’t think there’s a way to tell one way or the other.
I had my first board meeting on Wednesday, where I formally joined the board and got to vote on my first resolutions. This is my first time as a board member for a non-profit and I have learned a bunch already, with a lot more to go!
Board terms last three years. I expect it will take me at least a few months to get fully up to speed on how everything works.
As a board member, my primary responsibilities are to show up to the meetings, vote on resolutions, act as an ambassador for the PSF to the Python community and beyond and help both set the direction for the PSF and ensure that the PSF meets its goals and holds true to its values.
I’m embarassed to admit that I wrote my election manifesto without a deep understanding of how the PSF operates and how much is possible for it to get done. Here’s the section I wrote about my goals should I be elected:
I believe there are problems facing the Python community that require dedicated resources beyond volunteer labour. I’d like the PSF to invest funding in the following areas in particular:
- Improve Python onboarding. In coaching new developers I’ve found that the initial steps to getting started with a Python development environment can be a difficult hurdle to cross. I’d like to help direct PSF resources to tackling this problem, with a goal of making the experience of starting to learn Python as smooth as possible, no matter what platform the learner is using.
- Make Python a great platform for distributing software. In building my own application, Datasette, in Python I’ve seen how difficult it can be to package up a Python application so that it can be installed by end-users, who aren’t ready to install Python and learn pip in order to try out a new piece of software. I’ve researched solutions for this for my own software using Homebrew, Docker, an Electron app and WASM/Pyodide. I’d like the PSF to invest in initiatives and documentation to make this as easy as possible, so that one of the reasons to build with Python is that distributing an application to end-users is already a solved problem.
I still think these are good ideas, and I hope to make progress on them during my term as a director—but I’m not going to start arguing for new initiatives until I’ve learned the ropes and fully understood the PSF’s abilities, current challenges and existing goals.
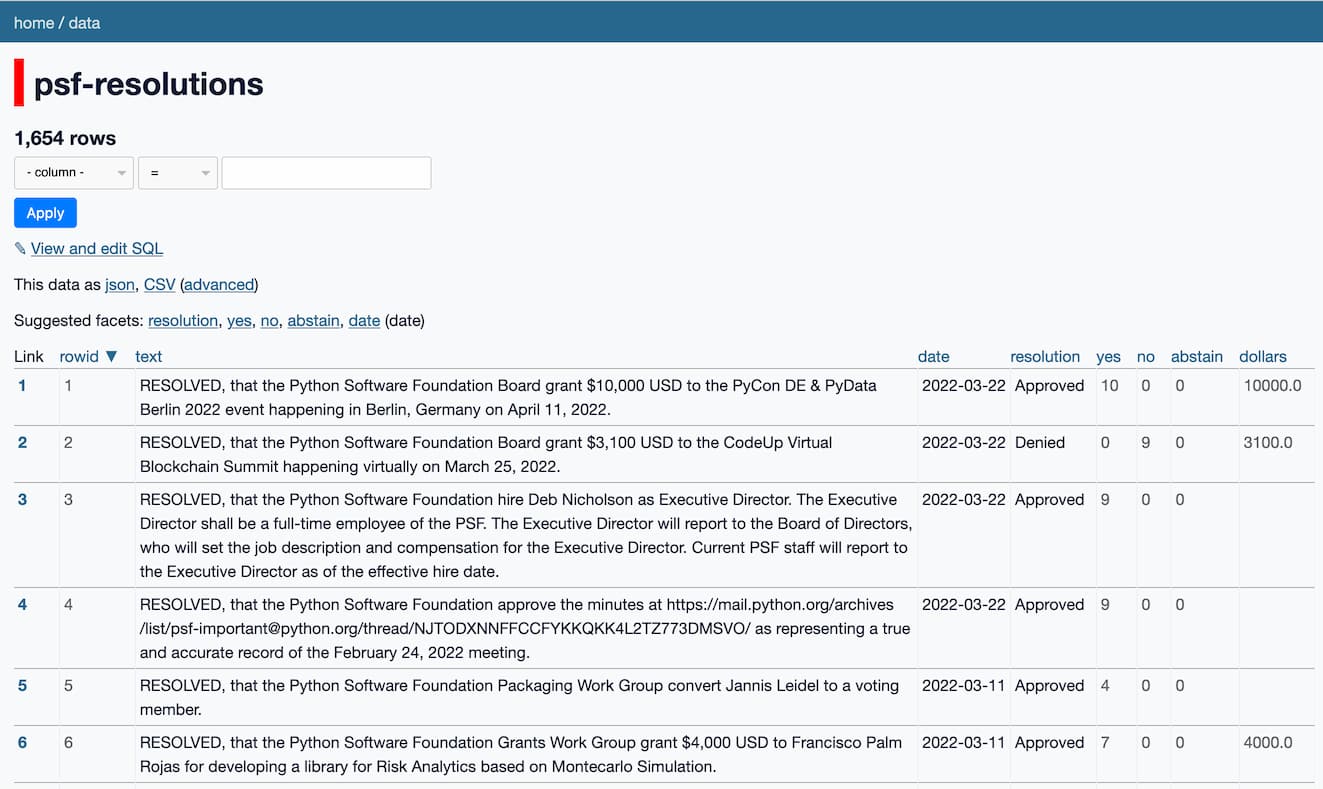
In figuring out how the board works, one of the most useful pages I stumbled across was this list of resolutions voted on by the board, dating back to 2001. There are over 1,600 of them! Browsing through them gave me a much better idea of the kind of things the board has the authority to do.
Scraping data into Datasette Lite
Because everything looks like a nail when you have a good hammer, I explored the board resolutions by loading them into Datasette. I tried a new trick this time: I scraped data from that page into a CSV file, then loaded up that CSV file in Datasette Lite via a GitHub Gist.
My scraper isn’t perfect—it misses about 150 resolutions because they don’t exactly fit the format it expects, but it was good enough for a proof of concept. I wrote that in a Jupyter Notebook which you can see here.
Here’s the CSV in a Gist. The great thing about Gists is that GitHub serve those files with the access-control-allow-origin: * HTTP header, which means you can load them cross-domain.
Here’s what you get if you paste the URL to that CSV into Datasette Lite (using this new feature I added last month):
And here’s a SQL query that shows the sum total dollar amount from every resolution that mentions “Nigeria”:
with filtered as (
select * from
[psf-resolutions]
where
"dollars" is not null
and "text" like '%' || :search || '%'
)
select
'Total: $' || printf('%,d', sum(dollars)) as text,
null as date
from filtered
union all
select
text, date
from filtered;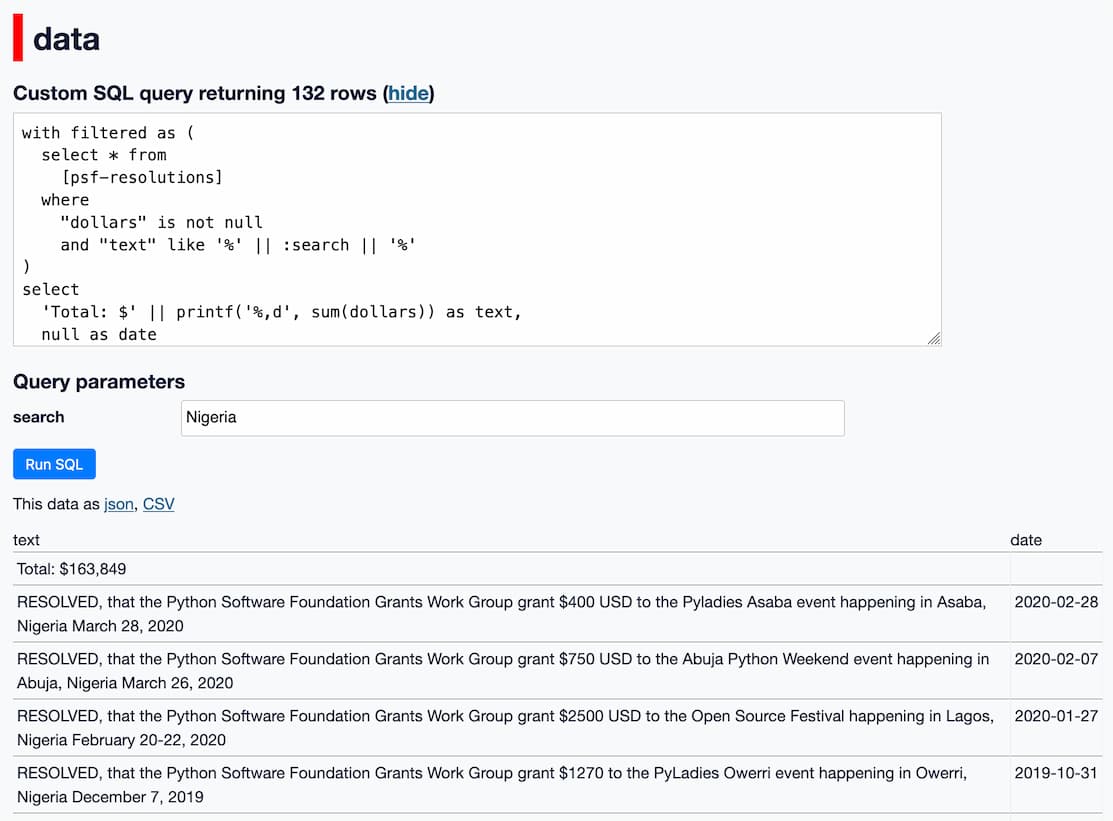
I’m using a new-to-me trick here: I use a CTE to filter down to just the rows I am interested in, then I create a first row that sums the dollar amounts as the text column and leaves the date column null, then unions that against the rows from the query.
Important note: These numbers aren’t actually particularly useful. Just because the PSF board voted on a resolution does not mean that the money made it to the grantee—there are apparently situations where the approved grant may not be properly claimed and transferred. Also, my scraper logic isn’t perfect. Plus the PSF spends a whole lot of money in ways that don’t show up in these resolutions.
So this is a fun hack, and a neat way to start getting a general idea of how the PSF works, but any numbers it produces should not be taken as the absolute truth.
As a general pattern though, I really like this workflow of generating CSV files, saving them to a Gist and then opening them directly in Datasette Lite. It provides a way to use Datasette to share and explore data without needing to involve any server-side systems (other than GitHub Gists) at all!
Big-endian bugs in sqlite-fts4
sqlite-fts4 is a small Python library I wrote that adds SQLite functions for calculating relevance scoring for full-text search using the FTS4 module that comes bundled with SQLite. I described that project in detail in Exploring search relevance algorithms with SQLite.
It’s a dependency of sqlite-utils so it has a pretty big install base, despite being relatively obscure.
This week I had a fascinating bug report from Sarah Julia Kriesch: Test test_underlying_decode_matchinfo fails on PPC64 and s390x on openSUSE.
The s390x is an IBM mainframe architecture and it uses a big-endian byte order, unlike all of the machines I use which are little-endian.
This is the first time I’ve encountered a big-endian v.s. little-endian bug in my entire career! I was excited to dig in.
Here’s the relevant code:
def decode_matchinfo(buf): # buf is a bytestring of unsigned integers, each 4 bytes long return struct.unpack("I" * (len(buf) // 4), buf)
SQLite FTS4 provides a matchinfo binary string which you need to decode in order to calculate the relevance score. This code uses the struct standard library module to unpack that binary string into a list of integers.
My initial attempt at fixing this turned out to be entirely incorrect.
I didn’t have a big-endian machine available for testing, and I assumed that the problem was caused by Python interpreting the bytes as the current architecture’s byte order. So I applied this fix:
return struct.unpack(">" + ("I" * (len(buf) // 4)), buf)
The > prefix there ensures that struct will always interpret the bytes as little-endian. I wrote up a TIL and shipped 1.0.2 with the fix.
Sarah promptly got back to me and reported some new failing tests.
It turns out my fix was entirely incorrect—in fact, I’d broken something that previously was working just fine.
The clue is in the SQLite documentation for matchinfo (which I really should have checked):
The
matchinfofunction returns a blob value. If it is used within a query that does not use the full-text index (a “query by rowid” or “linear scan”), then the blob is zero bytes in size. Otherwise, the blob consists of zero or more 32-bit unsigned integers in machine byte-order (emphasis mine).
Looking more closely at the original bug report, the test that failed was this one:
@pytest.mark.parametrize( "buf,expected", [ ( b"\x01\x00\x00\x00\x02\x00\x00\x00\x02\x00\x00\x00\x02\x00\x00\x00", (1, 2, 2, 2), ) ], ) def test_underlying_decode_matchinfo(buf, expected): assert expected == decode_matchinfo(buf)
That test hard-codes a little-endian binary string and checks the output of my decode_matchinfo function. This is obviously going to fail on a big-endian system.
So my original behaviour was actually correct: I was parsing the string using the byte order of the architecture, and SQLite was providing the string in the byte order of the architecture. The only bug was in my test.
I reverted my previous fix and fixed the test instead:
@pytest.mark.parametrize( "buf,expected", [ ( b"\x01\x00\x00\x00\x02\x00\x00\x00\x02\x00\x00\x00\x02\x00\x00\x00" if sys.byteorder == "little" else b"\x00\x00\x00\x01\x00\x00\x00\x02\x00\x00\x00\x02\x00\x00\x00\x02", (1, 2, 2, 2), ) ], ) def test_underlying_decode_matchinfo(buf, expected): assert expected == decode_matchinfo(buf)
sys.byteorder reports the byte order of the host system, so this test now passes on both little-endian and big-endian systems.
There was one remaining challenge: how to test this? I wasn’t going to make the same mistake of shipping a fix that hadn’t actually been exercised on the target architecture a second time.
After quite a bit of research (mainly throwing the terms docker and s390x into the GitHub code search engine and seeing what I could find) I figured out a fix. It turns out you can use Docker and QEMU to run an emulated s390x system—both on a Mac laptop and in GitHub Actions.
Short version:
docker run --rm --privileged multiarch/qemu-user-static:register --reset
docker run -it multiarch/ubuntu-core:s390x-focal /bin/bash
For the longer version, check my TIL: Emulating a big-endian s390x with QEMU.
Releases this week
-
sqlite-fts4: 1.0.3—(5 releases total)—2022-07-30
Custom Python functions for working with SQLite FTS4 -
shot-scraper: 0.14.2—(17 releases total)—2022-07-28
A comand-line utility for taking automated screenshots of websites -
datasette-sqlite-fts4: 0.3.1—2022-07-28
Datasette plugin that adds custom SQL functions for working with SQLite FTS4 -
datasette-publish-vercel: 0.14.1—(22 releases total)—2022-07-23
Datasette plugin for publishing data using Vercel - datasette-insert: 0.8—(8 releases total)—2022-07-22
TIL this week
More recent articles
- OpenAI’s accidental cyberattack against Hugging Face is science fiction that happened - 22nd July 2026
- A Fireside Chat with Cat and Thariq from the Claude Code team - 21st July 2026
- Kimi K3, and what we can still learn from the pelican benchmark - 16th July 2026