GraphQL in Datasette with the new datasette-graphql plugin
7th August 2020
This week I’ve mostly been building datasette-graphql, a plugin that adds GraphQL query support to Datasette.
I’ve been mulling this over for a couple of years now. I wasn’t at all sure if it would be a good idea, but it’s hard to overstate how liberating Datasette’s plugin system has proven to be: plugins provide a mechanism for exploring big new ideas without any risk of taking the core project in a direction that I later regret.
Now that I’ve built it, I think I like it.
A GraphQL refresher
GraphQL is a query language for APIs, first promoted by Facebook in 2015.
(Surprisingly it has nothing to do with the Facebook Graph API, which predates it by several years and is more similar to traditional REST. A third of respondents to my recent poll were understandably confused by this.)
GraphQL is best illustrated by an example. The following query (a real example that works with datasette-graphql) does a whole bunch of work:
- Retrieves the first 10 repos that match a search for “datasette”, sorted by most stargazers first
- Shows the total count of search results, along with how to retrieve the next page
- For each repo, retrieves an explicit list of columns
owneris a foreign key to theuserstable—this query retrieves thenameandhtml_urlfor the user that owns each repo- A repo has issues (via an incoming foreign key relationship). The query retrieves the first three issues, a total count of all issues and for each of those three gets the
titleandcreated_at.
That’s a lot of stuff! Here’s the query:
{
repos(first:10, search: "datasette", sort_desc: stargazers_count) {
totalCount
pageInfo {
endCursor
hasNextPage
}
nodes {
full_name
description_
stargazers_count
created_at
owner {
name
html_url
}
issues_list(first: 3) {
totalCount
nodes {
title
created_at
}
}
}
}
}You can run this query against the live demo. I’m seeing it return results in 511ms. Considering how much it’s getting done that’s pretty good!
datasette-graphql
The datasette-graphql plugin adds a /graphql page to any Datasette instance. It exposes a GraphQL field for every table and view. Those fields can be used to select, filter, search and paginate through rows in the corresponding table.
The plugin detects foreign key relationships—both incoming and outgoing—and turns those into further nested fields on the rows.
It does this by using table introspection (powered by sqlite-utils) to dynamically define a schema using the Graphene Python GraphQL library.
Most of the work happens in the schema_for_datasette() function in datasette_graphql/utils.py. The code is a little fiddly because Graphene usually expects you to define your GraphQL schema using classes (similar to Django’s ORM), but in this case the schema needs to be generated dynamically based on introspecting the tables and columns.
It has a solid set of unit tests, including some test examples written in Markdown which double as further documentation (see test_graphql_examples()).
GraphiQL for interactively exploring APIs
GraphiQL is the best thing about GraphQL. It’s a JavaScript interface for trying out GraphQL queries which pulls in a copy of the API schema and uses it to implement really comprehensive autocomplete.
datasette-graphql includes GraphiQL (inspired by Starlette’s implementation). Here’s an animated gif showing quite how useful it is for exploring an API:
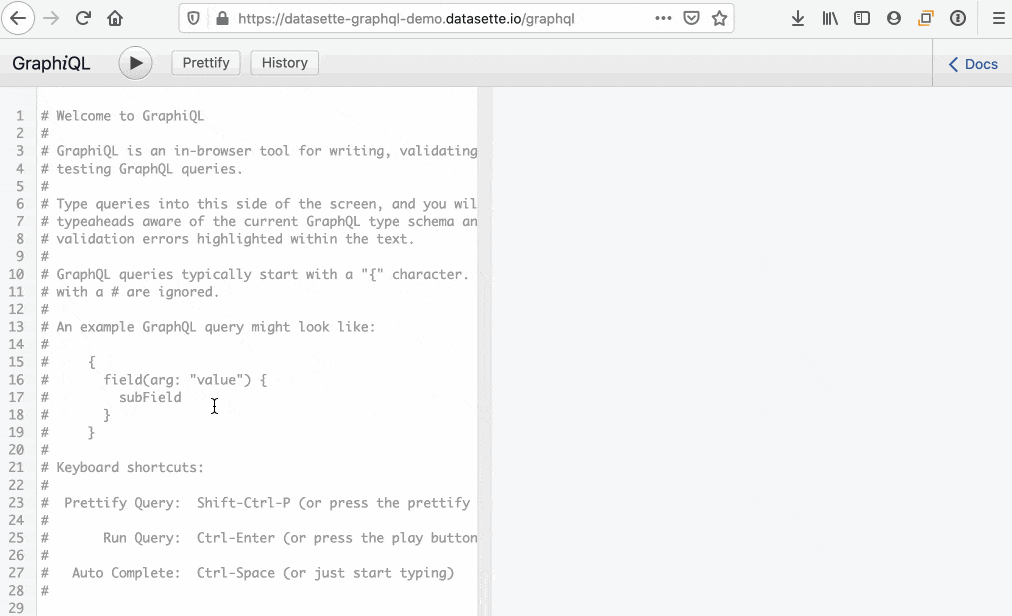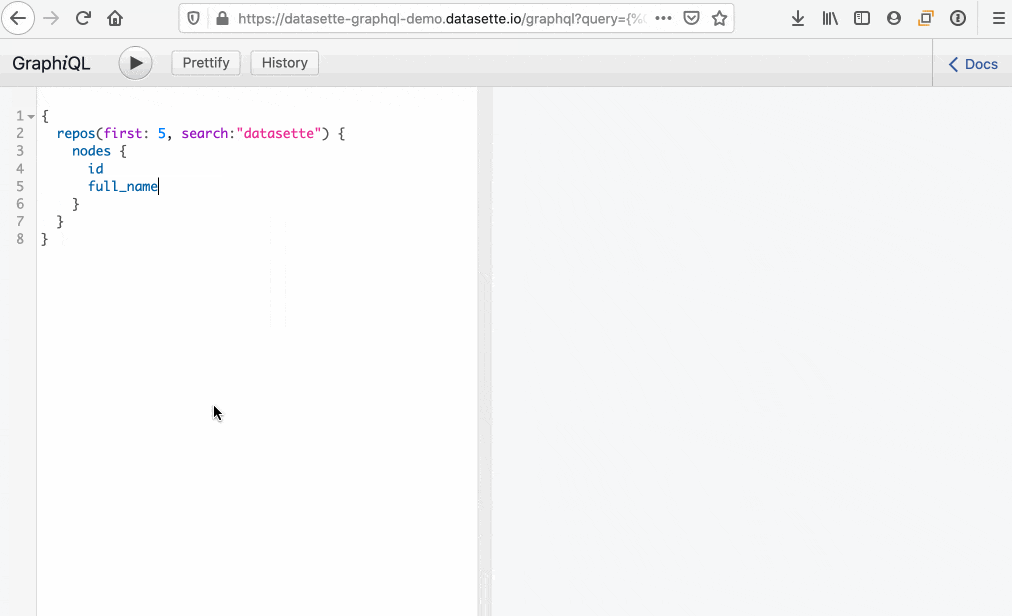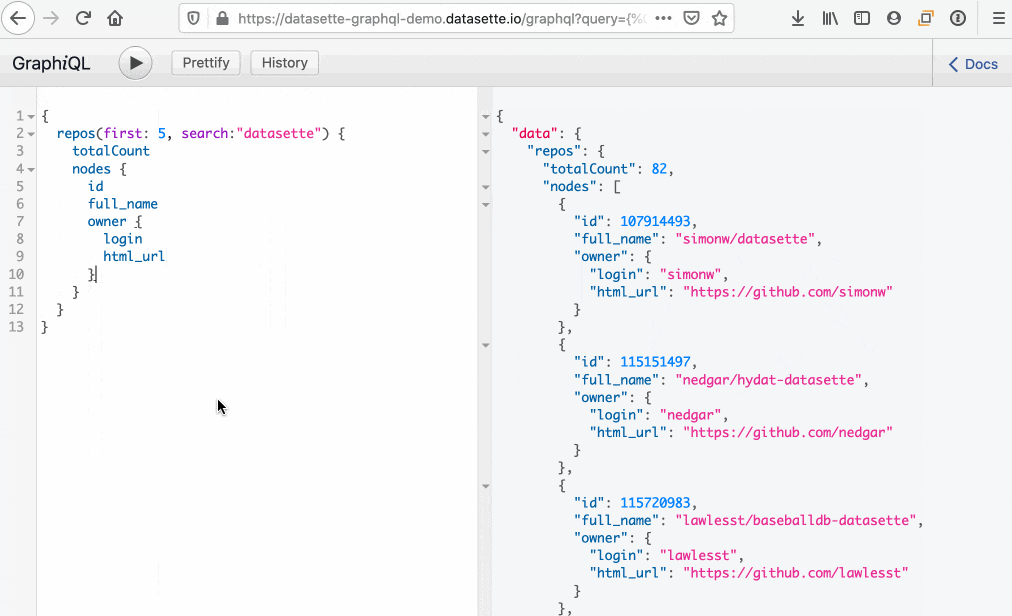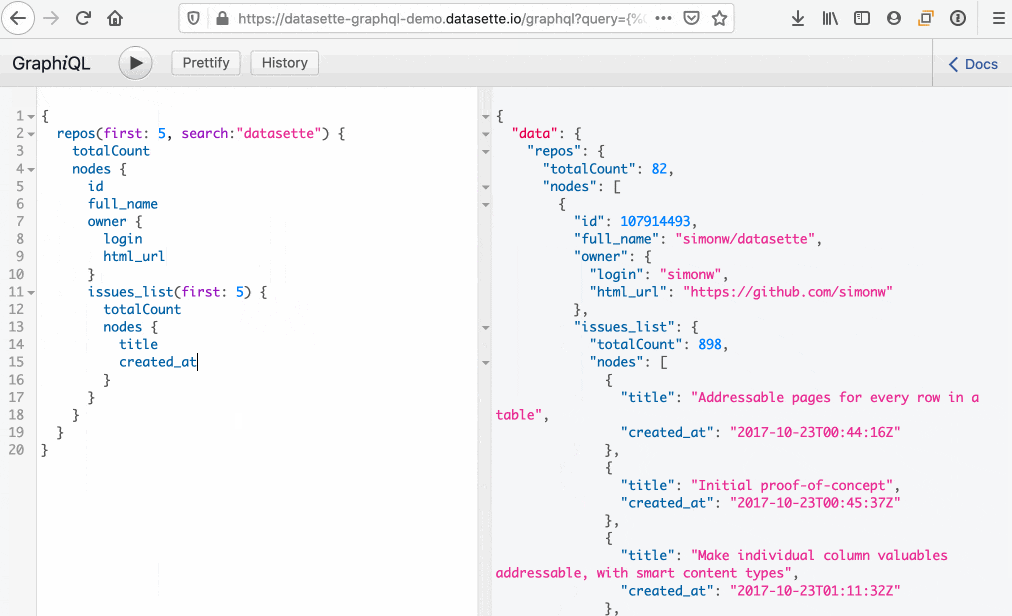
A couple of tips: On macOS option+space brings up the full completion list for the current context, and command+enter executes the current query (equivalent to clicking the play button).
Performance notes
The most convenient thing about GraphQL from a client-side development point of view is also the most nerve-wracking from the server-side: a single GraphQL query can end up executing a LOT of SQL.
The example above executes at least 32 separate SQL queries:
- 1 select against repos (plus 1 count query)
- 10 against issues (plus 10 counts)
- 10 against users (for the
ownerfield)
There are some optimization tricks I’m not using yet (in particular the DataLoader pattern) but it’s still cause for concern.
Interestingly, SQLite may be the best possible database backend for GraphQL due to the characteristics explained in the essay Many Small Queries Are Efficient In SQLite.
Since SQLite is an in-process database, it doesn’t have to deal with network overhead for each SQL query that it executes. A SQL query is essentially a C function call. So the flurry of queries that’s characteristic for GraphQL really plays to SQLite’s unique strengths.
Datasette has always featured arbitrary SQL execution as a core feature, which it protects using query time limits. I have an open issue to further extend the concept of Datasette’s time limits to the overall execution of a GraphQL query.
More demos
Enabling a GraphQL instance for a Datasette is as simple as pip install datasette-graphql, so I’ve deployed the new plugin in a few other places:
- covid-19.datasettes.com/graphql for exploring Covid-19 data
- register-of-members-interests.datasettes.com/graphql for exploring UK Register of Members Interests MP data
- til.simonwillison.net/graphql for exploring my TILs
Future improvements
I have a bunch of open issues for the plugin describing what I want to do with it next. The most notable planned improvement is adding support for Datasette’s canned queries.
Andy Ingram shared the following interesting note on Twitter:
The GraphQL creators are (I think) unanimous in their skepticism of tools that bring GraphQL directly to your database or ORM, because they just provide carte blanche access to your entire data model, without actually giving API design proper consideration.
My plugin does exactly that. Datasette is a tool for publishing raw data, so exposing everything is very much in line with the philosophy of the project. But it’s still smart to put some design thought into your APIs.
Canned queries are pre-baked SQL queries, optionally with parameters that can be populated by the user.
These could map directly to GraphQL fields. Users could even use plugin configuration to turn off the automatic table fields and just expose their canned queries.
In this way, canned queries can allow users to explicitly design the fields they expose via GraphQL. I expect this to become an extremely productive way of prototyping new GraphQL APIs, even if the final API is built on a backend other than Datasette.
Also this week
A couple of years ago I wrote a piece about Exploring the UK Register of Members Interests with SQL and Datasette. I finally got around to automating this using GitHub Actions, so register-of-members-interests.datasettes.com now updates with the latest data every 24 hours.
I renamed datasette-publish-now to datasette-publish-vercel, reflecting Vercel’s name change from Zeit Now. Here’s how I did that.
datasette-insert, which provides a JSON API for inserting data, defaulted to working unauthenticated. MongoDB and Elasticsearch have taught us that insecure-by-default inevitably leads to insecure deployments. I fixed that: the plugin now requires authentication, and if you don’t want to set that up and know what you are doing you can install the deliberately named datasette-insert-unsafe plugin to allow unauthenticated access.
Releases this week
- datasette-graphql 0.7—2020-08-06
- datasette-graphql 0.6—2020-08-06
- sqlite-utils 2.14.1—2020-08-06
- datasette-graphql 0.5—2020-08-06
- datasette-graphql 0.4—2020-08-06
- datasette-graphql 0.3—2020-08-06
- datasette-graphql 0.2—2020-08-06
- datasette-graphql 0.1a—2020-08-02
- sqlite-utils 2.14—2020-08-01
- datasette-insert-unsafe 0.1—2020-07-31
- datasette-insert 0.6—2020-07-31
- datasette-publish-vercel 0.7—2020-07-31
TIL this week
More recent articles
- OpenAI’s accidental cyberattack against Hugging Face is science fiction that happened - 22nd July 2026
- A Fireside Chat with Cat and Thariq from the Claude Code team - 21st July 2026
- Kimi K3, and what we can still learn from the pelican benchmark - 16th July 2026