Weeknotes: COVID-19 numbers in Datasette
11th March 2020
COVID-19, the disease caused by the novel coronavirus, gets more terrifying every day. Johns Hopkins Center for Systems Science and Engineering (CSSE) have been collating data about the spread of the disease and publishing it as CSV files on GitHub.
This morning I used the pattern described in Deploying a data API using GitHub Actions and Cloud Run to set up a scheduled task that grabs their data once an hour and publishes it to https://covid-19.datasettes.com/ as a table in Datasette.
If you’re not yet concerned about COVID-19 you clearly haven’t been paying atttention to what’s been happening in Italy. Here’s a query which shows a graph of the number of confirmed cases in Italy over the past few weeks (using datasette-vega):
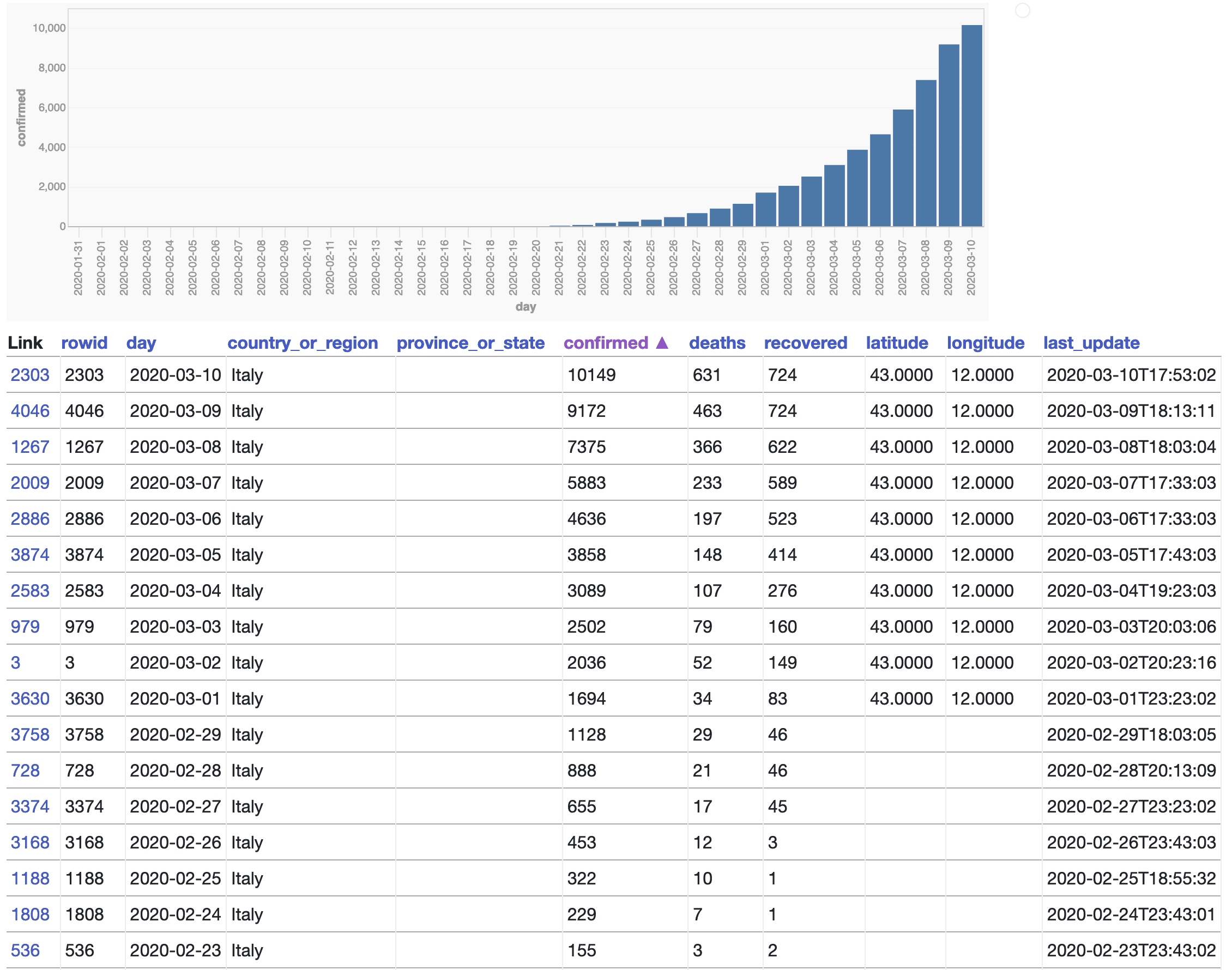
155 cases 17 days ago to 10,149 cases today is really frightening. And the USA still doesn’t have robust testing in place, so the numbers here are likely to really shock people once they start to become more apparent.
If you’re going to use the data in covid-19.datasettes.com for anything please be responsible with it and read the warnings in the README file in detail: it’s important to fully understand the sources of the data and how it is being processed before you use it to make any assertions about the spread of COVID-19.
My favourite resource to understand Coronavirus and what we should be doing about it is flattenthecurve.com, compiled by Julie McMurry, an assistant professor at Oregon State University College of Public Health. I strongly recommend checking it out.
Other projects
I’ve worked on a bunch of other projects this week, some of which were inspired by my time at NICAR.
- fec-to-sqlite is a script for saving FEC campaign finance filings to a SQLite database. Since those filings are pulled in via HTTP and can get pretty big, it uses a neat trick to generate a progress bar with the tqdm library—it initiates a progress bar with the Content-Length of the incoming file, then as it iterates over the lines coming in over HTTP it uses the length of each line to update that bar.
- datasette-search-all is a new plugin that enables search across multiple FTS-enabled SQLite tables at once. I wrote more about that in this blog post on Monday.
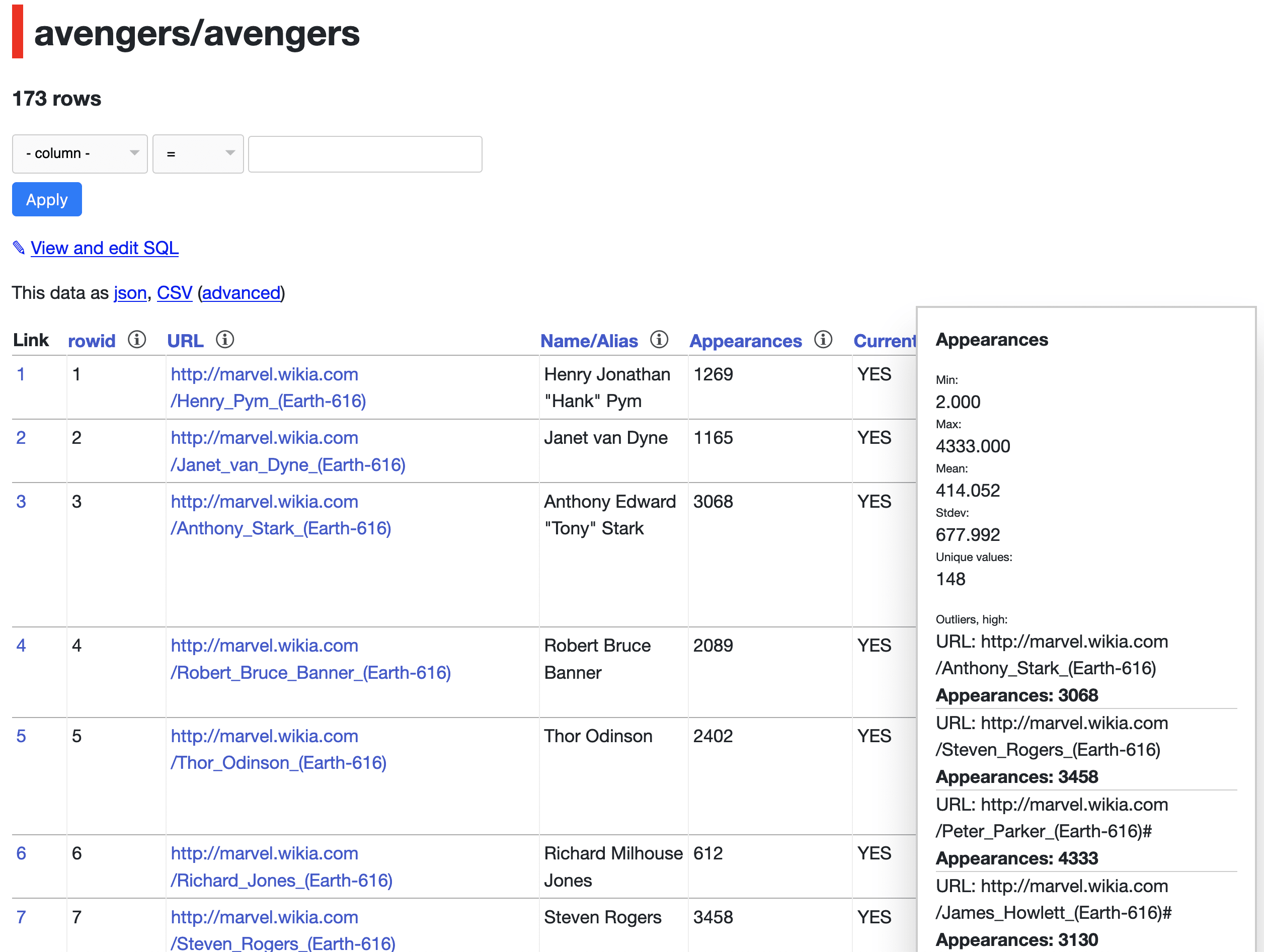
- datasette-column-inspect is an extremely experimental plugin that tries out a “column inspector” tool for Datasette tables—click on a column heading and the plugin shows you interesting facts about that column, such as the min/mean/max/stdev, any outlying values, the most common values and the least common values. Screenshot below. This prototype came about as part of a JSK team project for the Designing Machine Learning course at Stanford—we were thinking about ways in which machine learning could help journalists find stories in large datasets. The prototype doesn’t have any machine learning in it—just some simple statistics to identify outliers—but it’s meant to illustrate how a tool that exposes machine learning insights against tabular data might work.
- github-to-sqlite grew a new sub-command:
github-to-sqlite commits github.db simonw/datasette—which imports information about commits to a repository (just the author and commit message, not the body of the commit itself). I’m running a private version of this against all of my projects, which is really useful for seeing what I worked on over the past week when writing my weeknotes.
Here are two screenshots of datasette-column-inspect in action. You can try out a live demo of the plugin over here.
More recent articles
- Kimi K3, and what we can still learn from the pelican benchmark - 16th July 2026
- The new GPT-5.6 family: Luna, Terra, Sol - 9th July 2026
- sqlite-utils 4.0, now with database schema migrations - 7th July 2026