3 posts tagged “minimax”
2026
SWE-bench February 2026 leaderboard update (via) SWE-bench is one of the benchmarks that the labs love to list in their model releases. The official leaderboard is infrequently updated but they just did a full run of it against the current generation of models, which is notable because it's always good to see benchmark results like this that weren't self-reported by the labs.
The fresh results are for their "Bash Only" benchmark, which runs their mini-swe-bench agent (~9,000 lines of Python, here are the prompts they use) against the SWE-bench dataset of coding problems - 2,294 real-world examples pulled from 12 open source repos: django/django (850), sympy/sympy (386), scikit-learn/scikit-learn (229), sphinx-doc/sphinx (187), matplotlib/matplotlib (184), pytest-dev/pytest (119), pydata/xarray (110), astropy/astropy (95), pylint-dev/pylint (57), psf/requests (44), mwaskom/seaborn (22), pallets/flask (11).
Correction: The Bash only benchmark runs against SWE-bench Verified, not original SWE-bench. Verified is a manually curated subset of 500 samples described here, funded by OpenAI. Here's SWE-bench Verified on Hugging Face - since it's just 2.1MB of Parquet it's easy to browse using Datasette Lite, which cuts those numbers down to django/django (231), sympy/sympy (75), sphinx-doc/sphinx (44), matplotlib/matplotlib (34), scikit-learn/scikit-learn (32), astropy/astropy (22), pydata/xarray (22), pytest-dev/pytest (19), pylint-dev/pylint (10), psf/requests (8), mwaskom/seaborn (2), pallets/flask (1).
Here's how the top ten models performed:
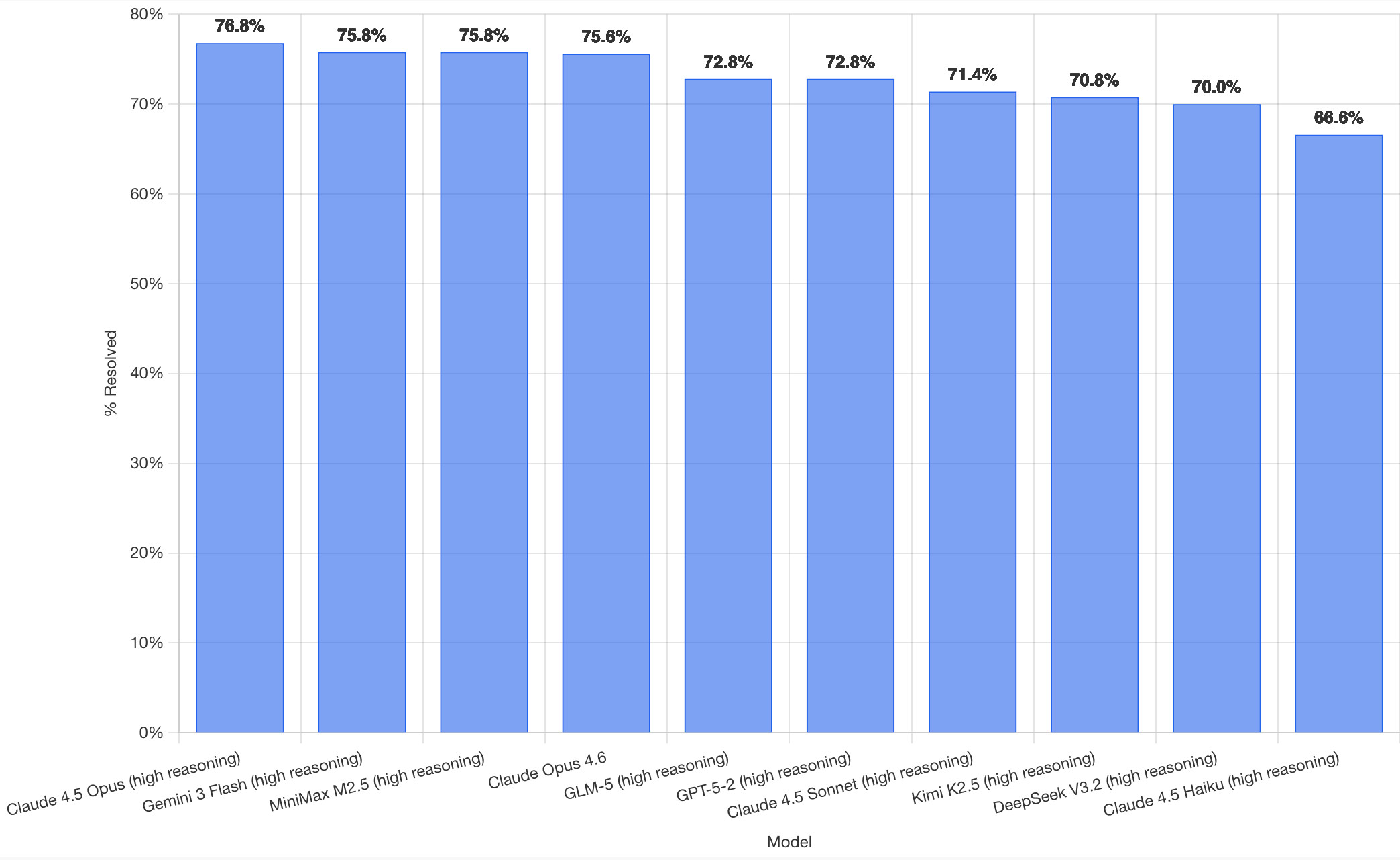
It's interesting to see Claude Opus 4.5 beat Opus 4.6, though only by about a percentage point. 4.5 Opus is top, then Gemini 3 Flash, then MiniMax M2.5 - a 229B model released last week by Chinese lab MiniMax. GLM-5, Kimi K2.5 and DeepSeek V3.2 are three more Chinese models that make the top ten as well.
OpenAI's GPT-5.2 is their highest performing model at position 6, but it's worth noting that their best coding model, GPT-5.3-Codex, is not represented - maybe because it's not yet available in the OpenAI API.
This benchmark uses the same system prompt for every model, which is important for a fair comparison but does mean that the quality of the different harnesses or optimized prompts is not being measured here.
The chart above is a screenshot from the SWE-bench website, but their charts don't include the actual percentage values visible on the bars. I successfully used Claude for Chrome to add these - transcript here. My prompt sequence included:
Use claude in chrome to open https://www.swebench.com/
Click on "Compare results" and then select "Select top 10"
See those bar charts? I want them to display the percentage on each bar so I can take a better screenshot, modify the page like that
I'm impressed at how well this worked - Claude injected custom JavaScript into the page to draw additional labels on top of the existing chart.
![Screenshot of a Claude AI conversation showing browser automation. A thinking step reads "Pivoted strategy to avoid recursion issues with chart labeling >" followed by the message "Good, the chart is back. Now let me carefully add the labels using an inline plugin on the chart instance to avoid the recursion issue." A collapsed "Browser_evaluate" section shows a browser_evaluate tool call with JavaScript code using Chart.js canvas context to draw percentage labels on bars: meta.data.forEach((bar, index) => { const value = dataset.data[index]; if (value !== undefined && value !== null) { ctx.save(); ctx.textAlign = 'center'; ctx.textBaseline = 'bottom'; ctx.fillStyle = '#333'; ctx.font = 'bold 12px sans-serif'; ctx.fillText(value.toFixed(1) + '%', bar.x, bar.y - 5); A pending step reads "Let me take a screenshot to see if it worked." followed by a completed "Done" step, and the message "Let me take a screenshot to check the result."](https://static.simonwillison.net/static/2026/claude-chrome-draw-on-chart.jpg)
Update: If you look at the transcript Claude claims to have switched to Playwright, which is confusing because I didn't think I had that configured.
2025
Interleaved thinking is essential for LLM agents: it means alternating between explicit reasoning and tool use, while carrying that reasoning forward between steps.This process significantly enhances planning, self‑correction, and reliability in long workflows. [...]
From community feedback, we've often observed failures to preserve prior-round thinking state across multi-turn interactions with M2. The root cause is that the widely-used OpenAI Chat Completion API does not support passing reasoning content back in subsequent requests. Although the Anthropic API natively supports this capability, the community has provided less support for models beyond Claude, and many applications still omit passing back the previous turns' thinking in their Anthropic API implementations. This situation has resulted in poor support for Interleaved Thinking for new models. To fully unlock M2's capabilities, preserving the reasoning process across multi-turn interactions is essential.
— MiniMax, Interleaved Thinking Unlocks Reliable MiniMax-M2 Agentic Capability
MiniMax M2 & Agent: Ingenious in Simplicity. MiniMax M2 was released on Monday 27th October by MiniMax, a Chinese AI lab founded in December 2021.
It's a very promising model. Their self-reported benchmark scores show it as comparable to Claude Sonnet 4, and Artificial Analysis are ranking it as the best currently available open weight model according to their intelligence score:
MiniMax’s M2 achieves a new all-time-high Intelligence Index score for an open weights model and offers impressive efficiency with only 10B active parameters (200B total). [...]
The model’s strengths include tool use and instruction following (as shown by Tau2 Bench and IFBench). As such, while M2 likely excels at agentic use cases it may underperform other open weights leaders such as DeepSeek V3.2 and Qwen3 235B at some generalist tasks. This is in line with a number of recent open weights model releases from Chinese AI labs which focus on agentic capabilities, likely pointing to a heavy post-training emphasis on RL.
The size is particularly significant: the model weights are 230GB on Hugging Face, significantly smaller than other high performing open weight models. That's small enough to run on a 256GB Mac Studio, and the MLX community have that working already.
MiniMax offer their own API, and recommend using their Anthropic-compatible endpoint and the official Anthropic SDKs to access it. MiniMax Head of Engineering Skyler Miao provided some background on that:
M2 is a agentic thinking model, it do interleaved thinking like sonnet 4.5, which means every response will contain its thought content. Its very important for M2 to keep the chain of thought. So we must make sure the history thought passed back to the model. Anthropic API support it for sure, as sonnet needs it as well. OpenAI only support it in their new Response API, no support for in ChatCompletion.
MiniMax are offering the new model via their API for free until November 7th, after which the cost will be $0.30/million input tokens and $1.20/million output tokens - similar in price to Gemini 2.5 Flash and GPT-5 Mini, see price comparison here on my llm-prices.com site.
I released a new plugin for LLM called llm-minimax providing support for M2 via the MiniMax API:
llm install llm-minimax
llm keys set minimax
# Paste key here
llm -m m2 -o max_tokens 10000 "Generate an SVG of a pelican riding a bicycle"
Here's the result:

51 input, 4,017 output. At $0.30/m input and $1.20/m output that pelican would cost 0.4836 cents - less than half a cent.
This is the first plugin I've written for an Anthropic-API-compatible model. I released llm-anthropic 0.21 first adding the ability to customize the base_url parameter when using that model class. This meant the new plugin was less than 30 lines of Python.