Saturday, 25th October 2025
Visual Features Across Modalities: SVG and ASCII Art Reveal Cross-Modal Understanding (via) New model interpretability research from Anthropic, this time focused on SVG and ASCII art generation.
We found that the same feature that activates over the eyes in an ASCII face also activates for eyes across diverse text-based modalities, including SVG code and prose in various languages. This is not limited to eyes – we found a number of cross-modal features that recognize specific concepts: from small components like mouths and ears within ASCII or SVG faces, to full visual depictions like dogs and cats. [...]
These features depend on the surrounding context within the visual depiction. For instance, an SVG circle element activates “eye” features only when positioned within a larger structure that activates “face” features.
And really, I can't not link to this one given the bonus they tagged on at the end!
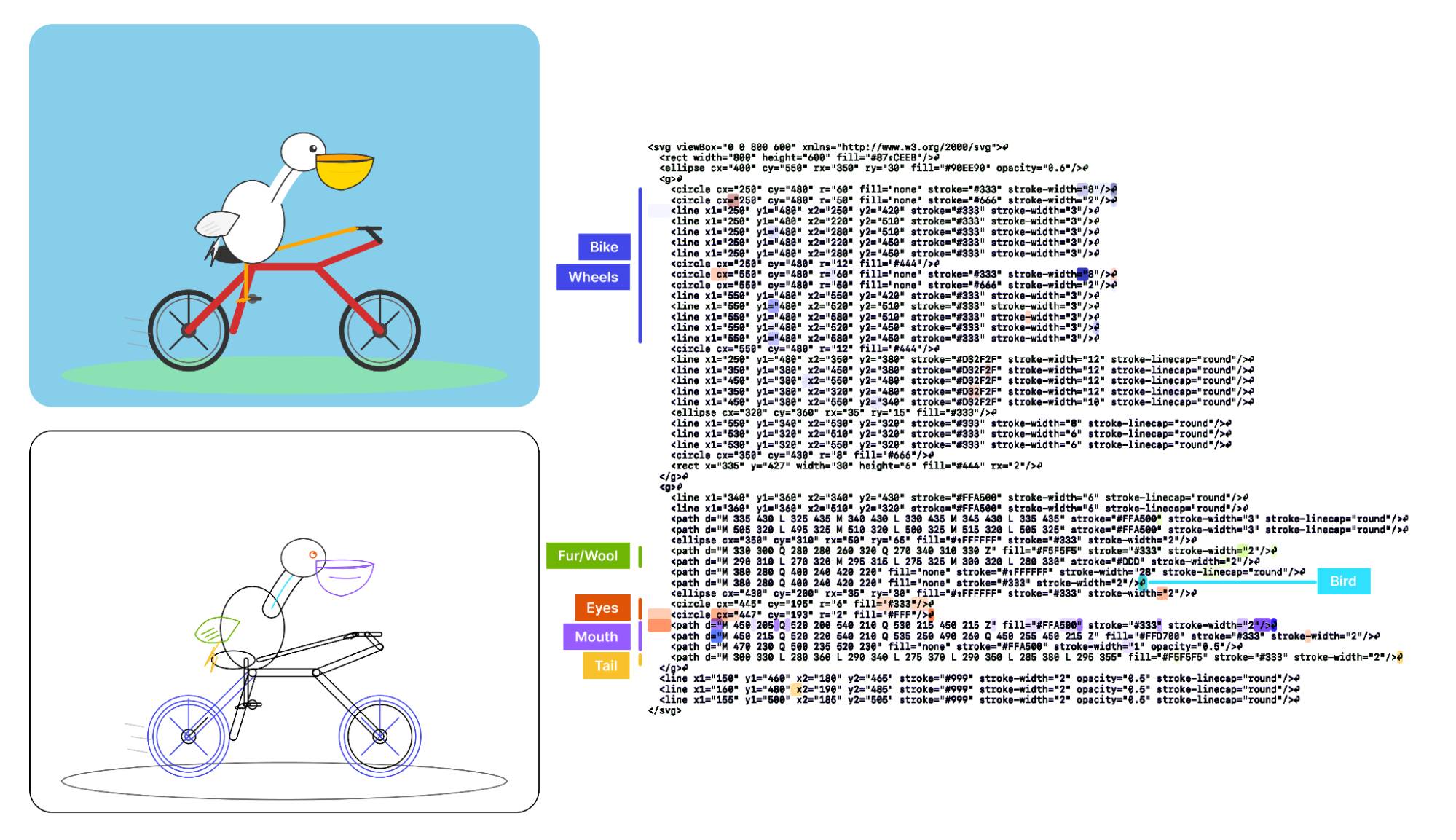
As a bonus, we also inspected features for an SVG of a pelican riding a bicycle, first popularized by Simon Willison as a way to test a model's artistic capabilities. We find features representing concepts including "bike", "wheels", "feet", "tail", "eyes", and "mouth" activating over the corresponding parts of the SVG code.
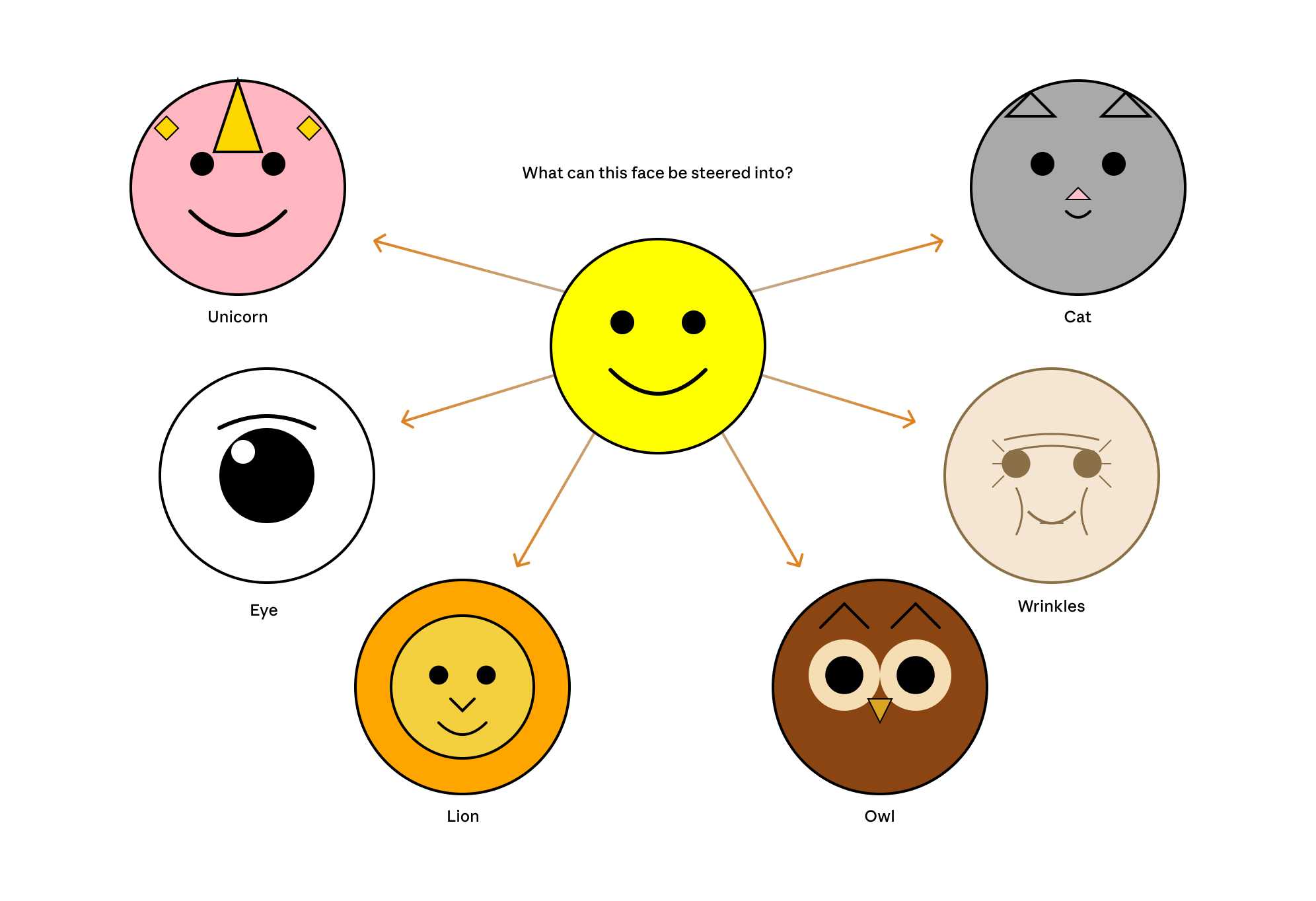
Now that they can identify model features associated with visual concepts in SVG images, can they us those for steering?
It turns out they can! Starting with a smiley SVG (provided as XML with no indication as to what it was drawing) and then applying a negative score to the "smile" feature produced a frown instead, and worked against ASCII art as well.
They could also boost features like unicorn, cat, owl, or lion and get new SVG smileys clearly attempting to depict those creatures.
I'd love to see how this behaves if you jack up the feature for the Golden Gate Bridge.
If you have an
AGENTS.mdfile, you can source it in yourCLAUDE.mdusing@AGENTS.mdto maintain a single source of truth.
— Claude Docs, with the official answer to standardizing on AGENTS.md
Someone on Hacker News asked for tips on setting up a codebase to be more productive with AI coding tools. Here's my reply:
- Good automated tests which the coding agent can run. I love pytest for this - one of my projects has 1500 tests and Claude Code is really good at selectively executing just tests relevant to the change it is making, and then running the whole suite at the end.
- Give them the ability to interactively test the code they are writing too. Notes on how to start a development server (for web projects) are useful, then you can have them use Playwright or curl to try things out.
- I'm having great results from maintaining a GitHub issues collection for projects and pasting URLs to issues directly into Claude Code.
- I actually don't think documentation is too important: LLMs can read the code a lot faster than you to figure out how to use it. I have comprehensive documentation across all of my projects but I don't think it's that helpful for the coding agents, though they are good at helping me spot if it needs updating.
- Linters, type checkers, auto-formatters - give coding agents helpful tools to run and they'll use them.
For the most part anything that makes a codebase easier for humans to maintain turns out to help agents as well.
Update: Thought of another one: detailed error messages! If a manual or automated test fails the more information you can return back to the model the better, and stuffing extra data in the error message or assertion is a very inexpensive way to do that.