OpenAI’s new open weight (Apache 2) models are really good
5th August 2025
The long promised OpenAI open weight models are here, and they are very impressive. They’re available under proper open source licenses—Apache 2.0—and come in two sizes, 120B and 20B.
OpenAI’s own benchmarks are eyebrow-raising—emphasis mine:
The gpt-oss-120b model achieves near-parity with OpenAI o4-mini on core reasoning benchmarks, while running efficiently on a single 80 GB GPU. The gpt-oss-20b model delivers similar results to OpenAI o3‑mini on common benchmarks and can run on edge devices with just 16 GB of memory, making it ideal for on-device use cases, local inference, or rapid iteration without costly infrastructure.
o4-mini and o3-mini are really good proprietary models—I was not expecting the open weights releases to be anywhere near that class, especially given their small sizes. That gpt-oss-20b model should run quite comfortably on a Mac laptop with 32GB of RAM.
Both models are mixture-of-experts:
gpt-oss-120b activates 5.1B parameters per token, while gpt-oss-20b activates 3.6B. The models have 117b and 21b total parameters respectively.
Something that surprised me even more about the benchmarks was the scores for general knowledge based challenges. I can just about believe they managed to train a strong reasoning model that fits in 20B parameters, but these models score highly on benchmarks like “GPQA Diamond (without tools) PhD-level science questions” too:
- o3 — 83.3%
- o4-mini — 81.4%
- gpt-oss-120b — 80.1%
- o3-mini — 77%
- gpt-oss-20b — 71.5%
A lot of these benchmarks are edging towards saturated.
- Running gpt-oss-20b on my Mac with LM Studio
- Pelican on reasoning=low
- Pelican on reasoning=medium
- Pelican on reasoning=high
- Space invaders with gpt-oss-20b
- Trying gpt-oss-120b via API providers
- llama.cpp is coming very shortly
- gpt-oss:20b in Ollama
- Training details from the model card
- OpenAI Harmony, a new format for prompt templates
- The open question for me: how good is tool calling?
- Competing with the Chinese open models
Running gpt-oss-20b on my Mac with LM Studio
There are already a bunch of different ways to run these models—OpenAI partnered with numerous organizations in advance of the release.
I decided to start with LM Studio.
I had to update to the most recent version of the app, then install the new model from their openai/gpt-oss-20b page.
First impressions: this is a really good model, and it somehow runs using just 11.72GB of my system RAM.
The model supports three reasoning efforts: low, medium and high. LM Studio makes those available via a dropdown.
Let’s try “Generate an SVG of a pelican riding a bicycle”:
Pelican on reasoning=low
I started with low. It thought for 0.07 seconds and then output this (at 39 tokens a second):
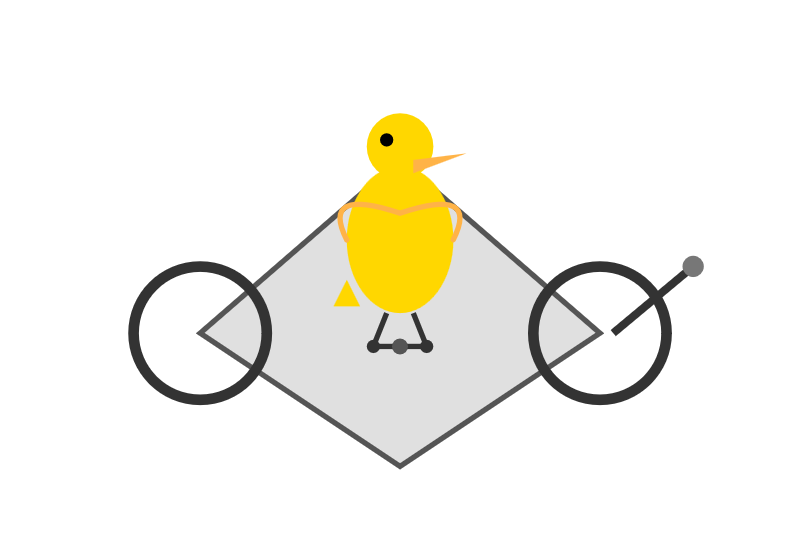
Except... it output invalid SVG. One of the path elements looked like this:
<!-- Frame -->
<path d="
M150,250 <!-- rear wheel center -->
L300,120 <!-- top tube to front -->
L450,250 <!-- chain stays back to front -->
L300,350 <!-- seat stays down -->
Z"
fill="#e0e0e0" stroke="#555" stroke-width="4"/>
But you can’t put comments inside attributes like that. I fixed this to get the above image.
Pelican on reasoning=medium
I tried again on medium. This time it thought for 4.44 seconds and gave me this, at 55 tokens/second:

Pelican on reasoning=high
And then on high. My first attempt here failed because it hit the default LM Studio 4096 context limit—so I reloaded the model and set the new limit to the maximum possible.
It jumped up to using 17.35GB RAM (I imagine it might use a lot more with a longer prompt) and after thinking for 5 minutes and 50 seconds (!) gave me this:
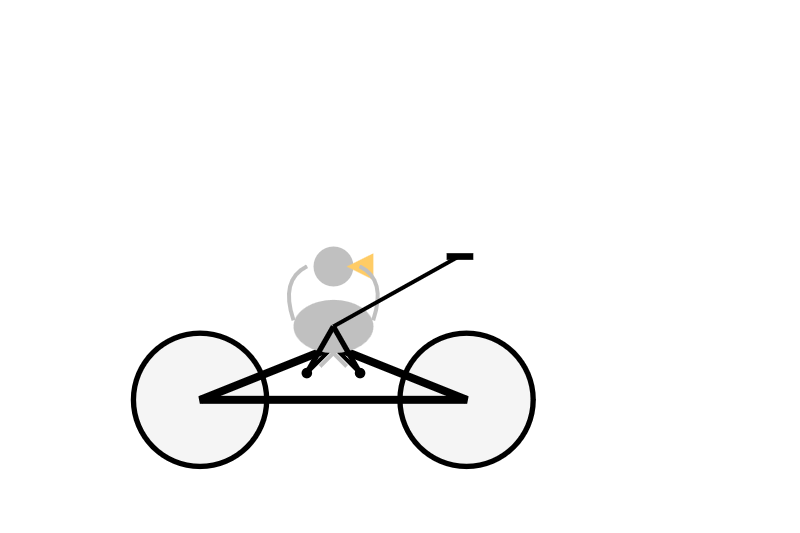
It thought really hard to get there. Here’s a snippet of that transcript:
But maybe we want seat below body bottom? Actually seat should be between body and pedals, not above body bottom. Wait, typical bicycle: seat post goes from bottom bracket upward to the seat. The seat sits on top of the seat tube (vertical). So the seat is above bottom bracket. In our representation, the seat is at y=250-255. Body center at 245, body bottom at 265. So body bottom is below seat. That means the pelican’s body is below the seat? Actually no: body bottom extends to 265; seat top is at 250; so seat sits above body bottom by about 15 units. That seems plausible because seat should be slightly above body, but body bottom is at 265 > seat top 255. [...]
I’ve seen this from other local reasoning models too: they can really overthink this kind of problem! I don’t know if there’s any pelican SVG that’s worth waiting nearly six minutes for.
Space invaders with gpt-oss-20b
Given how long high took I switched back to medium for my next experiment:
Write an HTML and JavaScript page implementing space invaders
It thought for 10.78 seconds and produced this:
You can play that here.
It’s not the best I’ve seen—I was more impressed by GLM 4.5 Air—but it’s very competent for a model that only uses 12GB of my RAM (GLM 4.5 Air used 47GB).
Trying gpt-oss-120b via API providers
I don’t quite have the resources on my laptop to run the larger model. Thankfully it’s already being hosted by a number of different API providers.
OpenRouter already lists three—Fireworks, Groq and Cerebras. (Update: now also Parasail and Baseten.)
Cerebras is fast, so I decided to try them first.
I installed the llm-cerebras plugin and ran the refresh command to ensure it had their latest models:
llm install -U llm-cerebras jsonschema
llm cerebras refresh(Installing jsonschema worked around a warning message.)
Output:
Refreshed 10 Cerebras models:
- cerebras-deepseek-r1-distill-llama-70b
- cerebras-gpt-oss-120b
- cerebras-llama-3.3-70b
- cerebras-llama-4-maverick-17b-128e-instruct
- cerebras-llama-4-scout-17b-16e-instruct
- cerebras-llama3.1-8b
- cerebras-qwen-3-235b-a22b-instruct-2507
- cerebras-qwen-3-235b-a22b-thinking-2507
- cerebras-qwen-3-32b
- cerebras-qwen-3-coder-480b
Now:
llm -m cerebras-gpt-oss-120b \
'Generate an SVG of a pelican riding a bicycle'Cerebras runs the new model at between 2 and 4 thousands tokens per second!
To my surprise this one had the same comments-in-attributes bug that we saw with oss-20b earlier. I fixed those and got this pelican:
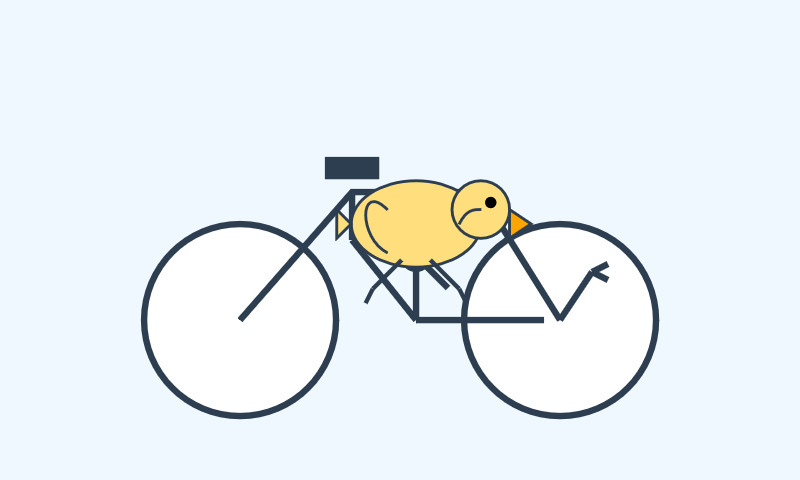
That bug appears intermittently—I’ve not seen it on some of my other runs of the same prompt.
The llm-openrouter plugin also provides access to the models, balanced across the underlying providers. You can use that like so:
llm install llm-openrouter
llm keys set openrouter
# Paste API key here
llm -m openrouter/openai/gpt-oss-120b "Say hi"llama.cpp is coming very shortly
The llama.cpp pull request for gpt-oss was landed less than an hour ago. It’s worth browsing through the coded—a lot of work went into supporting this new model, spanning 48 commits to 83 different files. Hopefully this will land in the llama.cpp Homebrew package within the next day or so, which should provide a convenient way to run the model via llama-server and friends.
gpt-oss:20b in Ollama
Ollama also have gpt-oss, requiring an update to their app.
I fetched that 14GB model like this:
ollama pull gpt-oss:20bNow I can use it with the new Ollama native app, or access it from LLM like this:
llm install llm-ollama
llm -m gpt-oss:20b 'Hi'This also appears to use around 13.26GB of system memory while running a prompt.
Ollama also launched Ollama Turbo today, offering the two OpenAI models as a paid hosted service:
Turbo is a new way to run open models using datacenter-grade hardware. Many new models are too large to fit on widely available GPUs, or run very slowly. Ollama Turbo provides a way to run these models fast while using Ollama’s App, CLI, and API.
Training details from the model card
Here are some interesting notes about how the models were trained from the model card (PDF):
Data: We train the models on a text-only dataset with trillions of tokens, with a focus on STEM, coding, and general knowledge. To improve the safety of the model, we filtered the data for harmful content in pre-training, especially around hazardous biosecurity knowledge, by reusing the CBRN pre-training filters from GPT-4o. Our model has a knowledge cutoff of June 2024.
Training: The gpt-oss models trained on NVIDIA H100 GPUs using the PyTorch framework with expert-optimized Triton kernels. The training run for gpt-oss-120b required 2.1 million H100-hours to complete, with gpt-oss-20b needing almost 10x fewer. [...]
Thunder Compute’s article NVIDIA H100 Pricing (August 2025): Cheapest On-Demand Cloud GPU Rates lists prices from around $2/hour to $11/hour, which would indicate a training cost of the 120b model between $4.2m and $23.1m and the 20b between $420,000 and $2.3m.
After pre-training, we post-train the models using similar CoT RL techniques as OpenAI o3. This procedure teaches the models how to reason and solve problems using CoT and teaches the model how to use tools. Because of the similar RL techniques, these models have a personality similar to models served in our first-party products like ChatGPT. Our training dataset consists of a wide range of problems from coding, math, science, and more.
The models have additional special training to help them use web browser and Python (Jupyter notebook) tools more effectively:
During post-training, we also teach the models to use different agentic tools:
- A browsing tool, that allows the model to call search and open functions to interact with the web. This aids factuality and allows the models to fetch info beyond their knowledge cutoff.
- A python tool, which allows the model to run code in a stateful Jupyter notebook environment.
- Arbitrary developer functions, where one can specify function schemas in a
Developermessage similar to the OpenAI API. The definition of function is done within our harmony format.
There’s a corresponding section about Python tool usage in the openai/gpt-oss repository README.
OpenAI Harmony, a new format for prompt templates
One of the gnarliest parts of implementing harnesses for LLMs is handling the prompt template format.
Modern prompts are complicated beasts. They need to model user v.s. assistant conversation turns, and tool calls, and reasoning traces and an increasing number of other complex patterns.
openai/harmony is a brand new open source project from OpenAI (again, Apache 2) which implements a new response format that was created for the gpt-oss models. It’s clearly inspired by their new-ish Responses API.
The format is described in the new OpenAI Harmony Response Format cookbook document. It introduces some concepts that I’ve not seen in open weight models before:
-
system,developer,user,assistantandtoolroles—many other models only use user and assistant, and sometimes system and tool. - Three different channels for output:
final,analysisandcommentary. Only thefinalchannel is default intended to be visible to users.analysisis for chain of thought andcommentaryis sometimes used for tools.
That channels concept has been present in ChatGPT for a few months, starting with the release of o3.
The details of the new tokens used by Harmony caught my eye:
| Token | Purpose | ID |
|---|---|---|
| <|start|> | Start of message header | 200006 |
| <|end|> | End of message | 200007 |
| <|message|> | Start of message content | 200008 |
| <|channel|> | Start of channel info | 200005 |
| <|constrain|> | Data type for tool call | 200003 |
| <|return|> | Stop after response | 200002 |
| <|call|> | Call a tool | 200012 |
Those token IDs are particularly important. They are part of a new token vocabulary called o200k_harmony, which landed in OpenAI’s tiktoken tokenizer library this morning.
In the past I’ve seen models get confused by special tokens—try pasting <|end|> into a model and see what happens.
Having these special instruction tokens formally map to dedicated token IDs should hopefully be a whole lot more robust!
The Harmony repo itself includes a Rust library and a Python library (wrapping that Rust library) for working with the new format in a much more ergonomic way.
I tried one of their demos using uv run to turn it into a shell one-liner:
uv run --python 3.12 --with openai-harmony python -c '
from openai_harmony import *
from openai_harmony import DeveloperContent
enc = load_harmony_encoding(HarmonyEncodingName.HARMONY_GPT_OSS)
convo = Conversation.from_messages([
Message.from_role_and_content(
Role.SYSTEM,
SystemContent.new(),
),
Message.from_role_and_content(
Role.DEVELOPER,
DeveloperContent.new().with_instructions("Talk like a pirate!")
),
Message.from_role_and_content(Role.USER, "Arrr, how be you?"),
])
tokens = enc.render_conversation_for_completion(convo, Role.ASSISTANT)
print(tokens)'Which outputs:
[200006, 17360, 200008, 3575, 553, 17554, 162016, 11, 261, 4410, 6439, 2359, 22203, 656, 7788, 17527, 558, 87447, 100594, 25, 220, 1323, 19, 12, 3218, 279, 30377, 289, 25, 14093, 279, 2, 13888, 18403, 25, 8450, 11, 49159, 11, 1721, 13, 21030, 2804, 413, 7360, 395, 1753, 3176, 13, 200007, 200006, 77944, 200008, 2, 68406, 279, 37992, 1299, 261, 96063, 0, 200007, 200006, 1428, 200008, 8977, 81, 11, 1495, 413, 481, 30, 200007, 200006, 173781]
Note those token IDs like 200006 corresponding to the special tokens listed above.
The open question for me: how good is tool calling?
There’s one aspect of these models that I haven’t explored in detail yet: tool calling. How these work is clearly a big part of the new Harmony format, but the packages I’m using myself (around my own LLM tool calling support) need various tweaks and fixes to start working with that new mechanism.
Tool calling currently represents my biggest disappointment with local models that I’ve run on my own machine. I’ve been able to get them to perform simple single calls, but the state of the art these days is wildly more ambitious than that.
Systems like Claude Code can make dozens if not hundreds of tool calls over the course of a single session, each one adding more context and information to a single conversation with an underlying model.
My experience to date has been that local models are unable to handle these lengthy conversations. I’m not sure if that’s inherent to the limitations of my own machine, or if it’s something that the right model architecture and training could overcome.
OpenAI make big claims about the tool calling capabilities of these new models. I’m looking forward to seeing how well they perform in practice.
Competing with the Chinese open models
I’ve been writing a lot about the flurry of excellent open weight models released by Chinese AI labs over the past few months—all of them very capable and most of them under Apache 2 or MIT licenses.
Just last week I said:
Something that has become undeniable this month is that the best available open weight models now come from the Chinese AI labs.
I continue to have a lot of love for Mistral, Gemma and Llama but my feeling is that Qwen, Moonshot and Z.ai have positively smoked them over the course of July. [...]
I can’t help but wonder if part of the reason for the delay in release of OpenAI’s open weights model comes from a desire to be notably better than this truly impressive lineup of Chinese models.
With the release of the gpt-oss models that statement no longer holds true. I’m waiting for the dust to settle and the independent benchmarks (that are more credible than my ridiculous pelicans) to roll out, but I think it’s likely that OpenAI now offer the best available open weights models.
Update: Independent evaluations are beginning to roll in. Here’s Artificial Analysis:
gpt-oss-120b is the most intelligent American open weights model, comes behind DeepSeek R1 and Qwen3 235B in intelligence but offers efficiency benefits [...]
While the larger gpt-oss-120b does not come in above DeepSeek R1 0528’s score of 59 or Qwen3 235B 2507s score of 64, it is notable that it is significantly smaller in both total and active parameters than both of those models.
More recent articles
- sqlite-utils 4.0, now with database schema migrations - 7th July 2026
- sqlite-utils 4.0rc2, mostly written by Claude Fable (for about $149.25) - 5th July 2026
- Have your agent record video demos of its work with shot-scraper video - 30th June 2026