Thursday, 12th December 2024
googleapis/python-genai. Google released this brand new Python library for accessing their generative AI models yesterday, offering an alternative to their existing generative-ai-python library.
The API design looks very solid to me, and it includes both sync and async implementations. Here's an async streaming response:
async for response in client.aio.models.generate_content_stream(
model='gemini-2.0-flash-exp',
contents='Tell me a story in 300 words.'
):
print(response.text)
It also includes Pydantic-based output schema support and some nice syntactic sugar for defining tools using Python functions.
“Rules” that terminal programs follow. Julia Evans wrote down the unwritten rules of terminal programs. Lots of details in here I hadn’t fully understood before, like REPL programs that exit only if you hit Ctrl+D on an empty line.
What does a board of directors do? Extremely useful guide to what life as a board member looks like for both for-profit and non-profit boards by Anil Dash, who has served on both.
Boards can range from a loosely connected group that assembled on occasion to indifferently rubber-stamp what an executive tells them, or they can be deeply and intrusively involved in an organization in a way that undermines leadership. Generally, they’re somewhere in between, acting as a resource that amplifies the capabilities and execution of the core team, and that mostly only helps out or steps in when asked to.
The section about the daily/monthly/quarterly/yearly responsibilities of board membership really helps explain the responsibilities of such a position in detail.
Don't miss the follow-up Q&A post.

Clio: A system for privacy-preserving insights into real-world AI use. New research from Anthropic, describing a system they built called Clio - for Claude insights and observations - which attempts to provide insights into how Claude is being used by end-users while also preserving user privacy.
There's a lot to digest here. The summary is accompanied by a full paper and a 47 minute YouTube interview with team members Deep Ganguli, Esin Durmus, Miles McCain and Alex Tamkin.
The key idea behind Clio is to take user conversations and use Claude to summarize, cluster and then analyze those clusters - aiming to ensure that any private or personally identifiable details are filtered out long before the resulting clusters reach human eyes.
This diagram from the paper helps explain how that works:
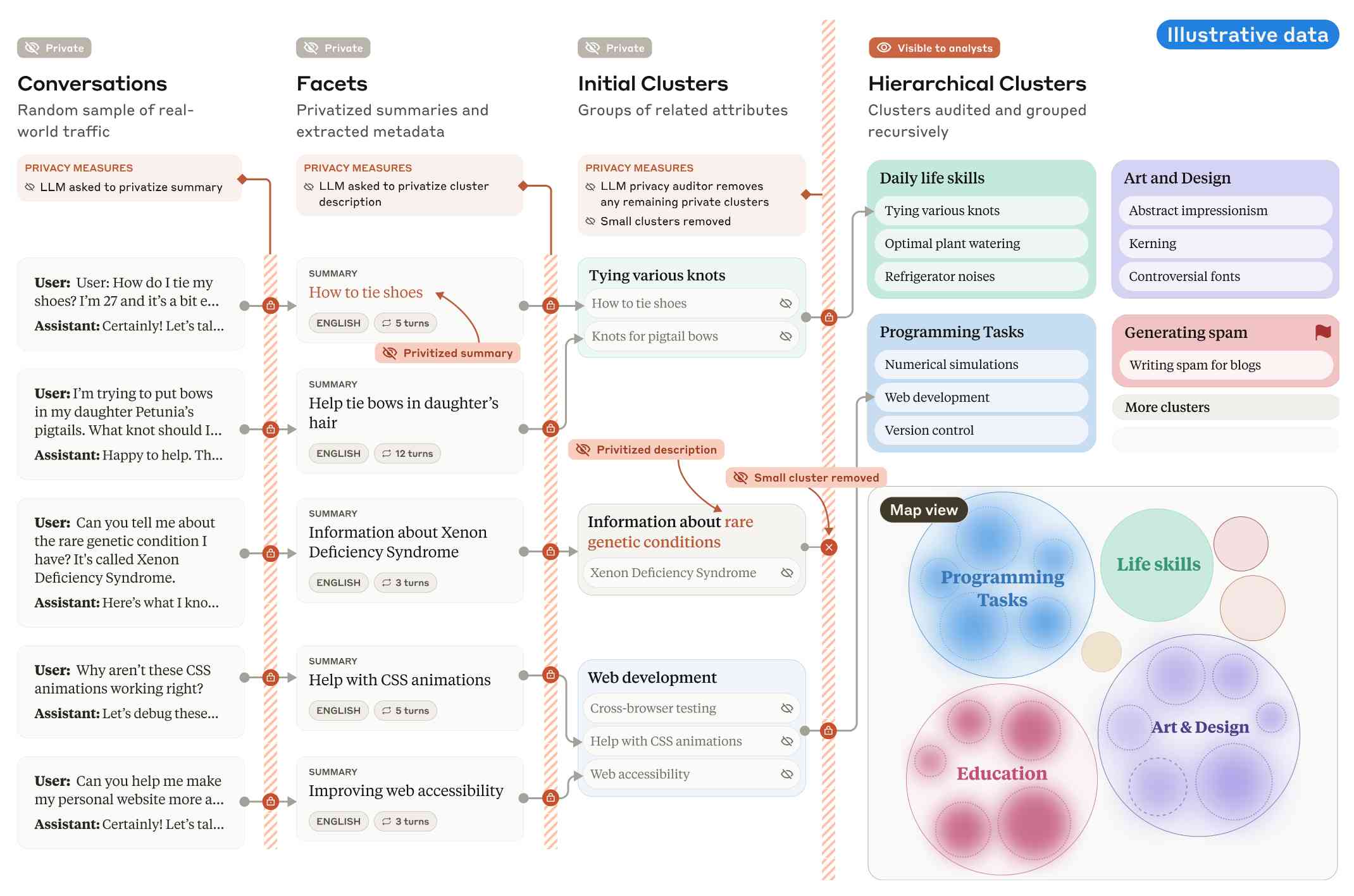
Claude generates a conversation summary, than extracts "facets" from that summary that aim to privatize the data to simple characteristics like language and topics.
The facets are used to create initial clusters (via embeddings), and those clusters further filtered to remove any that are too small or may contain private information. The goal is to have no cluster which represents less than 1,000 underlying individual users.
In the video at 16:39:
And then we can use that to understand, for example, if Claude is as useful giving web development advice for people in English or in Spanish. Or we can understand what programming languages are people generally asking for help with. We can do all of this in a really privacy preserving way because we are so far removed from the underlying conversations that we're very confident that we can use this in a way that respects the sort of spirit of privacy that our users expect from us.
Then later at 29:50 there's this interesting hint as to how Anthropic hire human annotators to improve Claude's performance in specific areas:
But one of the things we can do is we can look at clusters with high, for example, refusal rates, or trust and safety flag rates. And then we can look at those and say huh, this is clearly an over-refusal, this is clearly fine. And we can use that to sort of close the loop and say, okay, well here are examples where we wanna add to our, you know, human training data so that Claude is less refusally in the future on those topics.
And importantly, we're not using the actual conversations to make Claude less refusally. Instead what we're doing is we are looking at the topics and then hiring people to generate data in those domains and generating synthetic data in those domains.
So we're able to sort of use our users activity with Claude to improve their experience while also respecting their privacy.
According to Clio the top clusters of usage for Claude right now are as follows:
- Web & Mobile App Development (10.4%)
- Content Creation & Communication (9.2%)
- Academic Research & Writing (7.2%)
- Education & Career Development (7.1%)
- Advanced AI/ML Applications (6.0%)
- Business Strategy & Operations (5.7%)
- Language Translation (4.5%)
- DevOps & Cloud Infrastructure (3.9%)
- Digital Marketing & SEO (3.7%)
- Data Analysis & Visualization (3.5%)
There also are some interesting insights about variations in usage across different languages. For example, Chinese language users had "Write crime, thriller, and mystery fiction with complex plots and characters" at 4.4x the base rate for other languages.