Datasette 1.0a2: Upserts and finely grained permissions
15th December 2022
I’ve released the third alpha of Datasette 1.0. The 1.0a2 release introduces upsert support to the new JSON API and makes some major improvements to the Datasette permissions system.
Here are the annotated releases (see previous).
You can install and try out the alpha using:
pip install datasette==1.0a2
Upserts for the JSON API
New
/db/table/-/upsertAPI, documented here. Upsert is an update-or-insert: existing rows will have specified keys updated, but if no row matches the incoming primary key a brand new row will be inserted instead. (#1878)
I wrote about the new JSON Write API when I released the first alpha a couple of weeks ago.
The API can be used to create and drop tables, and to insert, update and delete rows in those tables.
The new /db/table/-/upsert API adds upsert support to Datasette.
An upsert is a update-or-insert. Consider the following:
POST /books/authors/-/upsert
Authorization: Bearer $TOKEN
Content-Type: application/json
{
"rows": [
{
"id": 1,
"name": "Ursula K. Le Guin",
"born": "1929-10-21"
},
{
"id": 2,
"name": "Terry Pratchett",
"born": "1948-04-28"
},
{
"id": 3,
"name": "Neil Gaiman",
"born": "1960-11-10"
}
]
}This table has a primary key of id. The above API call will create three records if the table is empty. But if the table already has records matching any of those primary keys, their name and born columns will be updated to match the incoming data.
Upserts can be a really convenient way of synchronizing data with an external data source. I had a couple of enquiries about them when I published the first alpha, so I decided to make them a key feature for this release.
Ignore and replace for the create table API
- The
/db/-/createAPI for creating a table now accepts"ignore": trueand"replace": trueoptions when called with the"rows"property that creates a new table based on an example set of rows. This means the API can be called multiple times with different rows, setting rules for what should happen if a primary key collides with an existing row. (#1927)/db/-/createAPI now requires actor to haveinsert-rowpermission in order to use the"row"or"rows"properties. (#1937)
This feature is a little less obvious, but I think it’s going to be really useful.
The /db/-/create API can be used to create a new table. You can feed it an explicit list of columns, but you can also give it one or more rows and have it infer the correct schema based on those examples.
Datasette inherits this feature from sqlite-utils—I’ve been finding this an incredibly productive way to work with SQLite databases for a few years now.
The real magic of this feature is that you can pipe data into Datasette without even needing to first check that the appropriate table has been created. It’s a really fast way of getting from data to a populated database and a working API.
Prior to 1.0a2 you could call /db/-/create with "rows" more than once and it would probably work... unless you attempted to insert rows with primary keys that were already in use—in which case you would get an error. This limited the utility of the feature.
Now you can pass "ignore": true or "replace": true to the API call, to tell Datasette what to do if it encounters a primary key that already exists in the table.
Heres an example using the author data from above:
POST /books/-/create
Authorization: Bearer $TOKEN
Content-Type: application/json
{
"table": "authors",
"pk": "id",
"replace": true,
"rows": [
{
"id": 1,
"name": "Ursula K. Le Guin",
"born": "1929-10-21"
},
{
"id": 2,
"name": "Terry Pratchett",
"born": "1948-04-28"
},
{
"id": 3,
"name": "Neil Gaiman",
"born": "1960-11-10"
}
]
}This will create the authors table if it does not exist and ensure that those three rows exist in it, in their exact state. If a row already exists it will be replaced.
Note that this is subtly different from an upsert. An upsert will only update the columns that were provided in the incoming data, leaving any other columns unchanged. A replace will replace the entire row.
Finely grained permissions
This is the most significant area of improvement in this release.
- New register_permissions(datasette) plugin hook. Plugins can now register named permissions, which will then be listed in various interfaces that show available permissions. (#1940)
Prior to this, permissions were just strings—things like "view-instance" or "view-table" or "insert-row".
Plugins can introduce their own permissions—many do already, like datasette-edit-schema which adds a "edit-schema" permission.
In order to start building UIs for managing permissions, I needed Datasette to know what they were!
The register_permissions() hook lets them do exactly that, and Datasette core uses it to register its own default set of permissions too.
Permissions are registered using the following named tuple:
Permission = collections.namedtuple( "Permission", ( "name", "abbr", "description", "takes_database", "takes_resource", "default" ) )
The abbr is an abbreviation—e.g. insert-row can be abbreviated to ir. This is useful for creating things like signed API tokens where space is at a premium.
takes_database and takes_resource are booleans that indicate whether the permission can optionally be applied to a specific database (e.g. execute-sql) or to a “resource”, which is the name I’m now using for something that could be a SQL table, a SQL view or a canned query.
The insert-row permission for example can be granted to the whole of Datasette, or to all tables in a specific database, or to specific tables.
Finally, the default value is a boolean that indicates whether the permission should be default-allow (view-instance for example) or default-deny (create-table and suchlike).
This next feature explains why I needed those permission names to be known to Datasette:
- The
/-/create-tokenpage can now be used to create API tokens which are restricted to just a subset of actions, including against specific databases or resources. See API Tokens for details. (#1947)
Datasette now has finely grained permissions for API tokens!
This is the feature I always want when I’m working with other APIs: the ability to create a token that can only perform a restricted subset of actions.
When I’m working with the GitHub API for example I frequently find myself wanting to create a “personal access token” that only has the ability to read issues from a specific repository. It’s infuriating how many APIs leave this ability out.
The /-/create-token interface (which you can try out on latest.datasette.io by first signing in as root and then visiting this page) lets you create an API token that can act on your behalf... and then optionally specify a subset of actions that the token is allowed to perform.
Thanks to the new permissions registration system, the UI on that page knows which permissions can be applied to which entities within Datasette itself.
Here’s a partial screenshot of the UI:
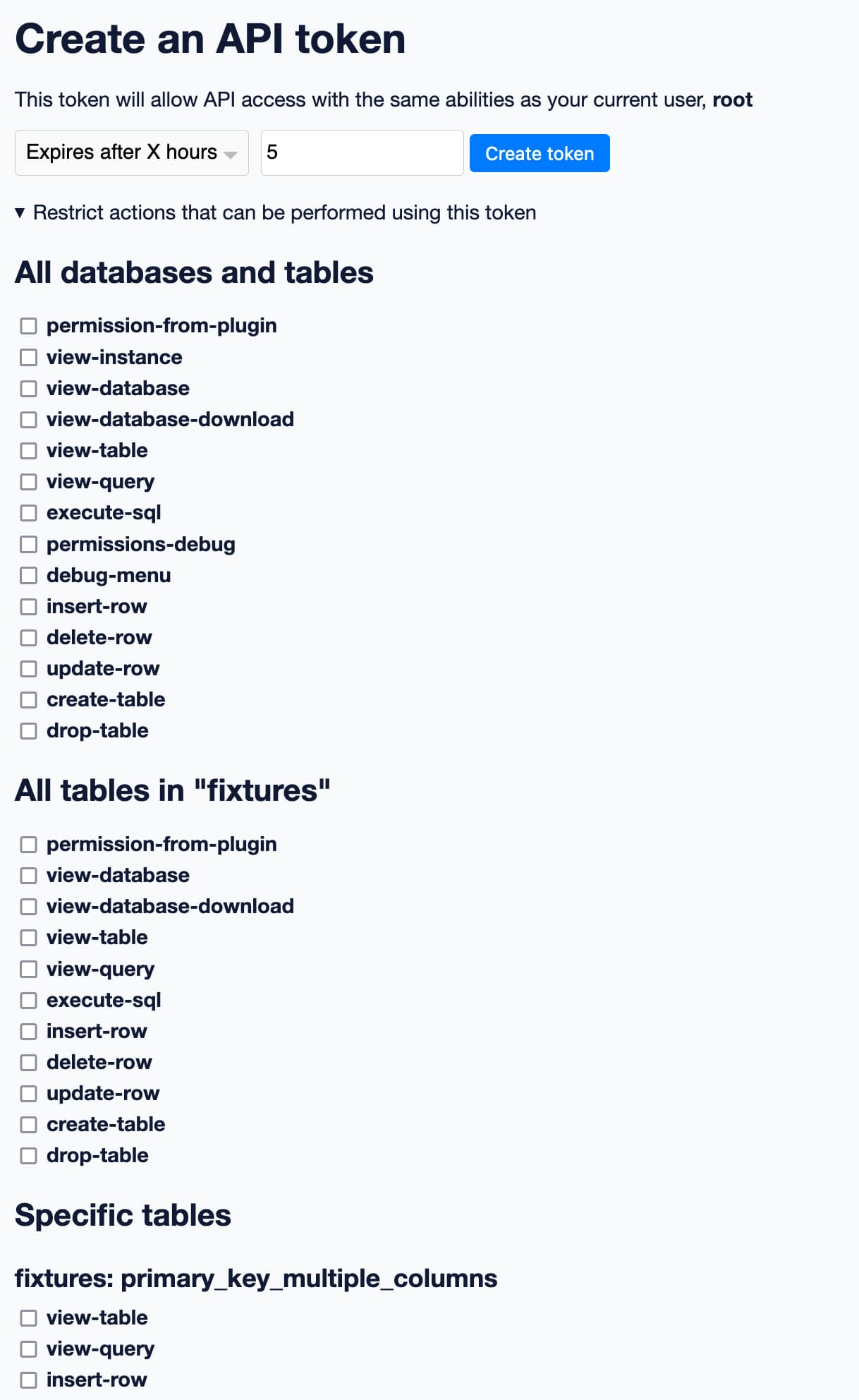
Select a subset of permissions, hit “Create token” and the result will be an access token you can copy and paste into another application, or use to call Datasette with curl.
Here’s an example token I created that grants view-instance permission against all of Datasette, and view-database and execute-sql permission against the ephemeral database, which in that demo is hidden from anonymous Datasette users.
dstok_eyJhIjoicm9vdCIsInQiOjE2NzEwODUzMDIsIl9yIjp7ImEiOlsidmkiXSwiZCI6eyJlcGhlbWVyYWwiOlsidmQiLCJlcyJdfX19.1uw0xyx8UND_Y_vTVg5kEF6m3GU
Here’s a screenshot of the screen I saw when I created it:

I’ve expanded the “token details” section to show the JSON that is bundled inside the signed token. The "_r" block records the specific permissions granted by the token:
-
"a": ["vi"]indicates that theview-instancepermission is granted against all of Datasette. -
"d": {"ephemeral": ["vd", "es"]}indicates that theview-databaseandexecute-sqlpermissions are granted against theephemeraldatabase.
The token also contains the ID of the user who created it ("a": "root") and the time that the token was created ("t": 1671085302). If the token was set to expire that expiry duration would be baked in here as well.
You can see the effect this has on the command-line using curl like so:
curl 'https://latest.datasette.io/ephemeral.json?sql=select+3+*+5&_shape=array'
This will return a forbidden error. But if you add the signed token:
curl 'https://latest.datasette.io/ephemeral.json?sql=select+3+*+5&_shape=array' -H 'Authorization: Bearer dstok_eyJhIjoicm9vdCIsInQiOjE2NzEwODUzMDIsIl9yIjp7ImEiOlsidmkiXSwiZCI6eyJlcGhlbWVyYWwiOlsidmQiLCJlcyJdfX19.1uw0xyx8UND_Y_vTVg5kEF6m3GU'
You’ll get back a JSON response:
[{"3 * 5": 15}]The datasette create-token CLI tool
- Likewise, the
datasette create-tokenCLI command can now create tokens with a subset of permissions. (#1855)- New datasette.create_token() API method for programmatically creating signed API tokens. (#1951)
The other way you can create Datasette tokens is on the command-line, using the datasette create-token command.
That’s been upgraded to support finely grained permissions too.
Here’s how you’d create a token for the same set of permissions as my ephemeral example above:
datasette create-token root \
--all view-instance \
--database ephemeral view-database \
--database ephemeral execute-sql \
--secret MY_DATASETTE_SECRET
In order to sign the token you need to pass in the --secret used by the server—although it will pick that up from the DATASETTE_SECRET environment variable if it’s available.
This has the interesting side-effect that you can use that command to create valid tokens for other Datasette instances, provided you know the secret they’re using. I think this ability will be really useful for people like myself who run lots of different Datasette instances on stateless hosting platforms such as Vercel and Google Cloud Run.
Configuring permissions in metadata.json/yaml
- Arbitrary permissions can now be configured at the instance, database and resource (table, SQL view or canned query) level in Datasette’s Metadata JSON and YAML files. The new
"permissions"key can be used to specify which actors should have which permissions. See Other permissions in metadata for details. (#1636)
Datasette has long had the ability to set permissions for viewing databases and tables using blocks of configuration in the increasingly poorly named metadata.json/yaml files.
As I’ve built new plugins that introduce new permissions, I’ve found myself wishing for an easier way to say “user X is allowed to perform action Y” for arbitrary other permissions.
The new "permissions" key in metadata.json/yaml files allows you to do that.
Here’s how to specify that the user with "id": "simon" is allowed to use the API to create tables and insert data into the docs database:
databases:
docs:
permissions:
create-table:
id: simon
insert-row:
id: simonHere’s a demo you can run on your own machine. Save the above to permissions.yaml and run the following in one terminal window:
datasette docs.db --create --secret sekrit -m permissions.yaml
This will create the docs.db database if it doesn’t already exist, and start Datasette with the permissions.yaml metadata file.
It sets --secret to a known value (you should always use a random secure secret in production) so we can easily use it with create-token in the next step:
Then in another terminal window run:
export TOKEN=$(
datasette create-token simon \
--secret sekrit
)
curl -XPOST http://localhost:8001/docs/-/create \
-H "Authorization: Bearer $TOKEN" \
-d '{
"table": "demo",
"row": {"id": 1, "name": "Simon"},
"pk": "id"
}'
The first line creates a token that can act on behalf of the simon actor. The second curl line then uses that token to create a table using the /-/create endpoint.
Run this, then visit http://localhost:8001/docs/demo to see the newly created table.
What’s next?
With the 1.0a2 release I’m reasonably confident that Datasette 1.0 is new-feature-complete. There’s still a lot of work to do before the final release, but the remaining work is far more intimidating: I need to make clean backwards-incompatible breakages to a whole host of existing features in order to ship a 1.0 that I can keep stable for as long as possible.
First up: I’m going to redesign Datasette’s default API output.
The current default JSON output for a simple table looks like this:
{
"database": "fixtures",
"table": "facet_cities",
"is_view": false,
"human_description_en": "sorted by name",
"rows": [
[
3,
"Detroit"
],
[
2,
"Los Angeles"
],
[
4,
"Memnonia"
],
[
1,
"San Francisco"
]
],
"truncated": false,
"filtered_table_rows_count": 4,
"expanded_columns": [],
"expandable_columns": [],
"columns": [
"id",
"name"
],
"primary_keys": [
"id"
],
"units": {},
"query": {
"sql": "select id, name from facet_cities order by name limit 101",
"params": {}
},
"facet_results": {},
"suggested_facets": [],
"next": null,
"next_url": null,
"private": false,
"allow_execute_sql": true,
"query_ms": 6.718471999647591,
"source": "tests/fixtures.py",
"source_url": "https://github.com/simonw/datasette/blob/main/tests/fixtures.py",
"license": "Apache License 2.0",
"license_url": "https://github.com/simonw/datasette/blob/main/LICENSE"
}In addition to being really verbose, you’ll note that the rows themselves are represented like this:
[
[
3,
"Detroit"
],
[
2,
"Los Angeles"
],
[
4,
"Memnonia"
],
[
1,
"San Francisco"
]
]I originally designed it this way because I thought saving on repeating the column names for every row would be more efficient.
In practice, every single time I’ve used Datasette’s API I’ve found myself using the ?_shape=array parameter, which outputs this format instead:
[
{
"id": 3,
"name": "Detroit"
},
{
"id": 2,
"name": "Los Angeles"
},
{
"id": 4,
"name": "Memnonia"
},
{
"id": 1,
"name": "San Francisco"
}
]It’s just so much more convenient to work with!
So the new default format will look like this:
{
"rows": [
{
"id": 3,
"name": "Detroit"
},
{
"id": 2,
"name": "Los Angeles"
},
{
"id": 4,
"name": "Memnonia"
},
{
"id": 1,
"name": "San Francisco"
}
]
}The rows key is there so I can add extra keys to the output, based on additional ?_extra= request parameters. You’ll be able to get back everything you can get in the current full-fat table API, but you’ll have to ask for it.
There are a ton of other changes I want to make to Datasette as a whole—things like renaming metadata.yaml to config.yaml to reflect that it’s gone way beyond its origins as a way of attaching metadata to a database.
The 1.0 milestone is a dumping ground for many of these ideas. It’s not a canonical reference though: I’d be very surprised if everything currently in that milestone makes it into the final 1.0 release.
As I get closer to 1.0 though I’ll be refining that milestone so it should get more accurate over time.
Once again: now is the time to be providing feedback on this stuff! The Datasette Discord is a particularly valuable way for me to get feedback on the work so far, and my plans for the future.
More recent articles
- The Axios supply chain attack used individually targeted social engineering - 3rd April 2026
- Highlights from my conversation about agentic engineering on Lenny's Podcast - 2nd April 2026
- Mr. Chatterbox is a (weak) Victorian-era ethically trained model you can run on your own computer - 30th March 2026