Datasette 0.63: The annotated release notes
27th October 2022
I released Datasette 0.63 today. These are the annotated release notes.
Features
- Now tested against Python 3.11. Docker containers used by
datasette publishanddatasette packageboth now use that version of Python. (#1853)
Python 3.11 came out a few days ago, and one of the highlights of that release was a significant amount of work invested in performance.
I ran a very basic load test comparing Datasette running on Python 3.10 and 3.11... and got 533.89 requests/second up from 413.56 requests/second—a 29% improvement!
Datasette works on (and is tested against) Python 3.7 and higher, but it has a couple of mechanisms that can bake a new Docker container for you. This performance increase was significant enough that I took the time to upgrade those containers to Python 3.11, using the 3.11.0-slim-bullseye base image.
--load-extensionoption now supports entrypoints. Thanks, Alex Garcia. (#1789)
Alex continues to do amazing work documenting the process for building SQLite extensions. It turns out a single extension can offer multiple variants—a trick he uses in some of his own. He contributed this fix to Datasette, and I ported the same feature to sqlite-utils as well.
- Facet size can now be set per-table with the new
facet_sizetable metadata option. (#1804)
Suggested by Charles Nepote on the Datasette Discord. Neat for if you’re dealing with larger databases.
- The truncate_cells_html setting now also affects long URLs in columns. (#1805)
Also suggested by Charles. This helps keep cells with giant linked URLs in them readable.
- The non-JavaScript SQL editor textarea now increases height to fit the SQL query. (#1786)
I implemented this partly because I still care how well Datasette works if the JavaScript doesn’t load, but mainly for Datasette Lite, which still doesn’t have a solution for loading JavaScript widgets like the CodeMirror editor used in regular Datasette.
Here’s a demo in Datasette Lite.
- Facets are now displayed with better line-breaks in long values. Thanks, Daniel Rech. (#1794)
This uses the word-break: break-all; CSS property.
- The
settings.jsonfile used in Configuration directory mode is now validated on startup. (#1816)
I added this in response to a bug report caused by someone misunderstanding the settings and adding an invalid one that got silently ignored. Now Datasette will raise an error if you try to use a setting doesn’t exist, which is a much better user experience.
- SQL queries can now include leading SQL comments, using
/* ... */or-- ...syntax. Thanks, Charles Nepote. (#1860)
Charles pointed out that it’s useful to be able to include a descriptive comment at the start of a SQL query, but Datasette was refusing queries that started with a comment.
Fixing this took some regular expression wizardry. Here’s the final expression plus a visualization:
^\s*((?:\-\-.*?\n\s*)|(?:\/\*((?!\*\/)[\s\S])*\*\/)\s*)*\s*select\b
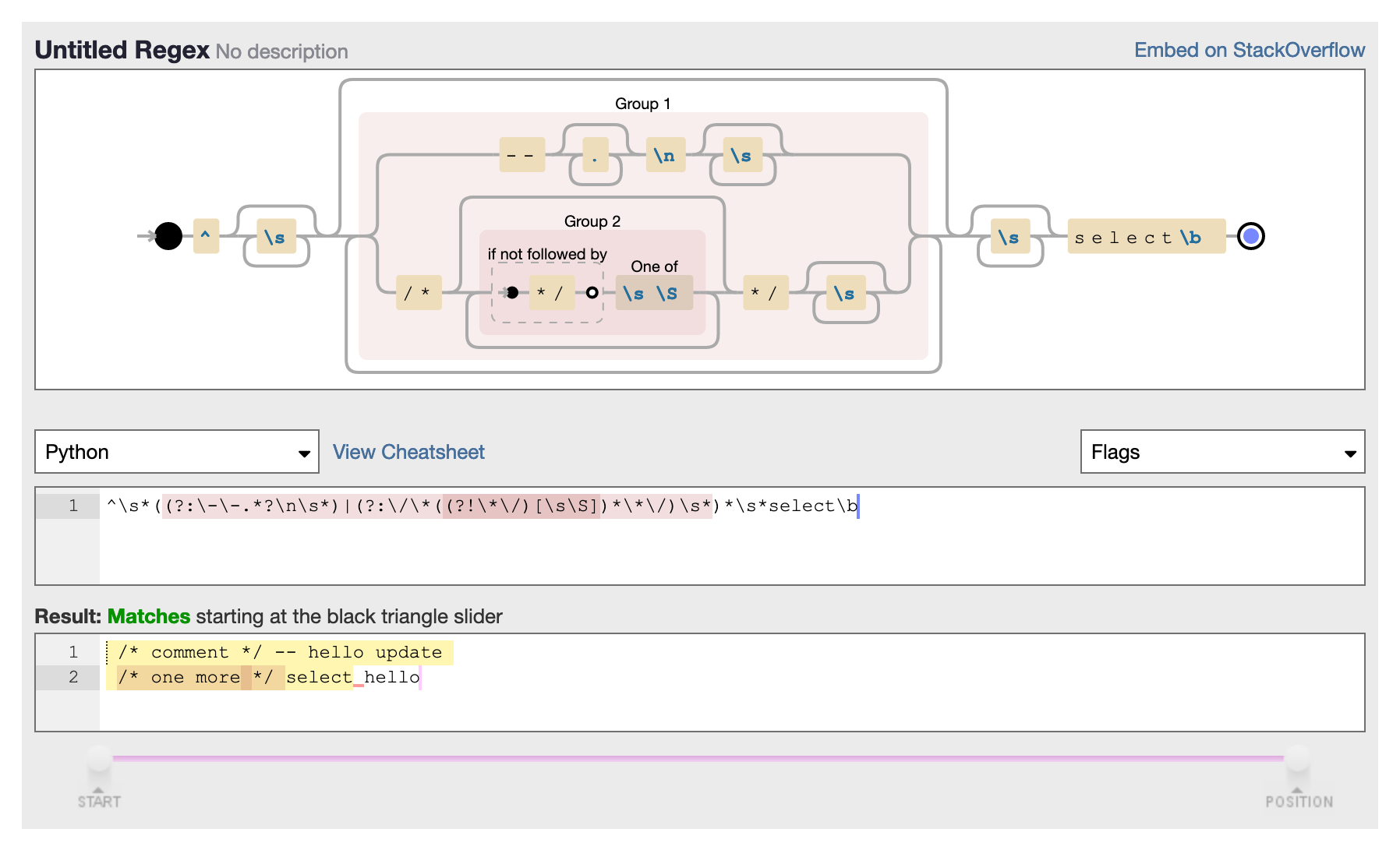
The trickiest part was that I wanted to match comments like this one:
/* This is a comment
that spans multiple lines */
But... I didn’t want to get confused by */ appearing inside a string literal. I wanted to match /* and then any sequence of characters that was NOT the end comment marker (including newlines)—and then */.
That’s what this does:
\/\*((?!\*\/)[\s\S])*\*\/)
\/\* and \*\/ are the esacped sequences for the literal /* and */.
((?!\*\/)[\s\S]) means “match any sequence of characters that is NOT the end comment marker, multiple times”. \s\S means both whitespace AND non-whitespace characters—it’s a trick for working around the fact that . doesn’t match newline characters.
- SQL query is now re-displayed when terminated with a time limit error. (#1819)
Previously the error message wouldn’t include the SQL you entered, so you would have to hit “back” to recover your query.
- The inspect data mechanism is now used to speed up server startup—thanks, Forest Gregg. (#1834)
datasette inspect is a pretty obscure Datasette feature. Run it against a SQLite file and it dumps out JSON representing some key statistics—most importantly the number of rows in each table.
If the database is immutable you can then start Datasette with a refererence to that JSON file (using the --inspect-data path option) and Datasette will use that data to save itself from having to count rows when displaying information about the database—a potentially expensive operation.
Most people will never use this feature directly, but various datasette publish commands (including datasette publish cloudrun) use it as part of the process of building a Docker image, so it’s actually quite impactful.
Forest Gregg spotted a way this could further increase server startup time, by skipping the step where Datasette calculates a hash of the database file since that’s also included in the inspect-data file.
- In Configuration directory mode databases with filenames ending in
.sqliteor.sqlite3are now automatically added to the Datasette instance. (#1646)
If you start Datasette by pointing it at a directory, datasette path/to/dir, it will now load any *.sqlite or *.sqlite3 files in that directory in addition to any *.db files.
- Breadcrumb navigation display now respects the current user’s permissions. (#1831)
This improvement came out of work I’ve been doing on Datasette Cloud, see previous weeknotes.
Plugin hooks and internals
- The prepare_jinja2_environment(env, datasette) plugin hook now accepts an optional
datasetteargument. Hook implementations can also now return anasyncfunction which will be awaited automatically. (#1809)
When I built the datasette-edit-templates plugin I found myself wanting to access the datasette object inside a prepare_jinja2_environment() plugin hook implementation.
Since datasette wasn’t passed to that hook, I solved it with this horrific piece of stack inspection:
@hookimpl def prepare_jinja2_environment(env): # TODO: This should ideally take datasette, but that's not an argument yet datasette = inspect.currentframe().f_back.f_back.f_back.f_back.f_locals["self"]
Making datasette available as a parameter there is much nicer!
Database(is_mutable=)now defaults toTrue. (#1808)
I hit a bug in datasette-upload-dbs because I’d added extra databases to the Datasette interface in immutable mode by mistake. This API change makes that mistake a lot harder to make.
- The datasette.check_visibility() method now accepts an optional
permissions=list, allowing it to take multiple permissions into account at once when deciding if something should be shown as public or private. This has been used to correctly display padlock icons in more places in the Datasette interface. (#1829)
Another improvement inspired by Datasette Cloud: I noticed that padlock icons weren’t appearing correctly throughout the Datasette interface, where they are meant to indicate that a database, table, view or query is private.
That was because there are actually multiple permission checks involved in deciding if something is private: a user may have access granted at the instance, database or table level.
The code that granted permission was checking all of those, but the code that then checked to see if an anonymous user would be able to see it wasn’t. I fixed that, while maintaining compatibility for older uses of the check_visibility() method.
- Datasette no longer enforces upper bounds on its dependencies. (#1800)
Henry Schreiner convinced me. See also Semantic Versioning Will Not Save You by Hynek Schlawack.
I’m still worrying about this though.
On the one hand, Datasette can be used as a library as part of a larger application (see this recent Django TIL for an example). As such, pinning requirements is rude: it makes it harder for downstream users to upgrade their dependencies.
But most of the time Datasette is installed as a standalone application—pipx install datasette or brew install datasette for example. In those cases, I’d like to be able to guarantee that the user will get known-to-work versions of every dependency.
I’m still thinking through my options here. I may even break out the core part of Datasette that works as a library into a separate package, so datasette has pinned dependencies but library users can install an unpinned version using a separate package name.
Documentation
This section stands without explanation I think. I like using the release notes to highlight this kind of thing, including articles that might not be hosted in the core Datasette documentation itself.
- New tutorial: Cleaning data with sqlite-utils and Datasette.
- Screenshots in the documentation are now maintained using shot-scraper, as described in Automating screenshots for the Datasette documentation using shot-scraper. (#1844)
- More detailed command descriptions on the CLI reference page. (#1787)
- New documentation on Running Datasette using OpenRC—thanks, Adam Simpson. (#1825).