5 posts tagged “will-mcgugan”
2025
Announcing Toad—a universal UI for agentic coding in the terminal. Will McGugan is building his own take on a terminal coding assistant, in the style of Claude Code and Gemini CLI, using his Textual Python library as the display layer.
Will makes some confident claims about this being a better approach than the Node UI libraries used in those other tools:
Both Anthropic and Google’s apps flicker due to the way they perform visual updates. These apps update the terminal by removing the previous lines and writing new output (even if only a single line needs to change). This is a surprisingly expensive operation in terminals, and has a high likelihood you will see a partial frame—which will be perceived as flicker. [...]
Toad doesn’t suffer from these issues. There is no flicker, as it can update partial regions of the output as small as a single character. You can also scroll back up and interact with anything that was previously written, including copying un-garbled output — even if it is cropped.
Using Node.js for terminal apps means that users with npx can run them easily without worrying too much about installation - Will points out that uvx has closed the developer experience there for tools written in Python.
Toad will be open source eventually, but is currently in a private preview that's open to companies who sponsor Will's work for $5,000:
[...] you can gain access to Toad by sponsoring me on GitHub sponsors. I anticipate Toad being used by various commercial organizations where $5K a month wouldn't be a big ask. So consider this a buy-in to influence the project for communal benefit at this early stage.
With a bit of luck, this sabbatical needn't eat in to my retirement fund too much. If it goes well, it may even become my full-time gig.
I really hope this works! It would be great to see this kind of model proven as a new way to financially support experimental open source projects of this nature.
I wrote about Textual's streaming markdown implementation the other day, and this post goes into a whole lot more detail about optimizations Will has discovered for making that work better.
The key optimization is to only re-render the last displayed block of the Markdown document, which might be a paragraph or a heading or a table or list, avoiding having to re-render the entire thing any time a token is added to it... with one important catch:
It turns out that the very last block can change its type when you add new content. Consider a table where the first tokens add the headers to the table. The parser considers that text to be a simple paragraph block up until the entire row has arrived, and then all-of-a-sudden the paragraph becomes a table.
Textual v4.0.0: The Streaming Release. Will McGugan may no longer be running a commercial company around Textual, but that hasn't stopped his progress on the open source project.
He recently released v4 of his Python framework for building TUI command-line apps, and the signature feature is streaming Markdown support - super relevant in our current age of LLMs, most of which default to outputting a stream of Markdown via their APIs.
I took an example from one of his tests, spliced in my async LLM Python library and got some help from o3 to turn it into a streaming script for talking to models, which can be run like this:
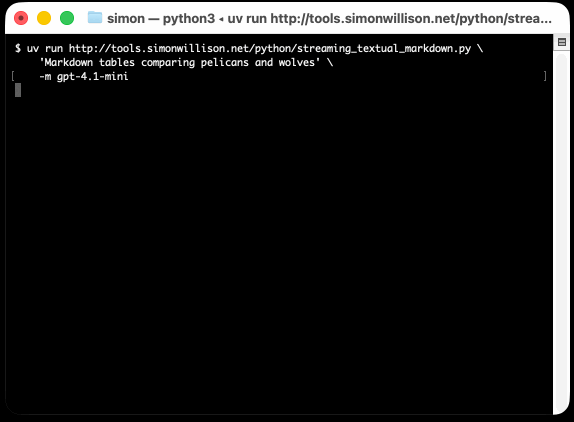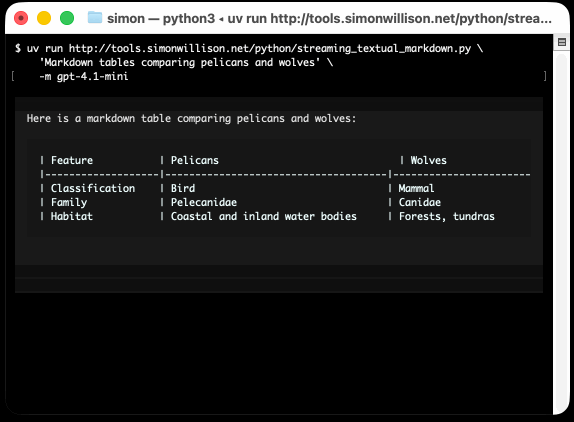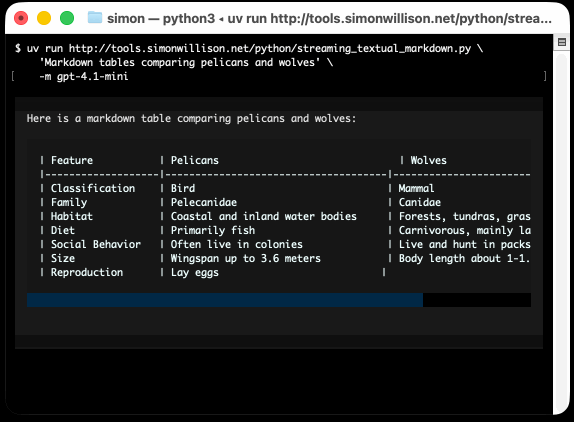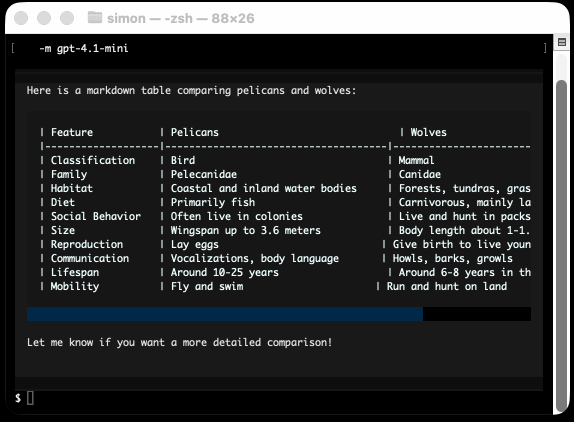
uv run http://tools.simonwillison.net/python/streaming_textual_markdown.py \
'Markdown headers and tables comparing pelicans and wolves' \
-m gpt-4.1-mini
2024
Anatomy of a Textual User Interface. Will McGugan used Textual and my LLM Python library to build a delightful TUI for talking to a simulation of Mother, the AI from the Aliens movies:
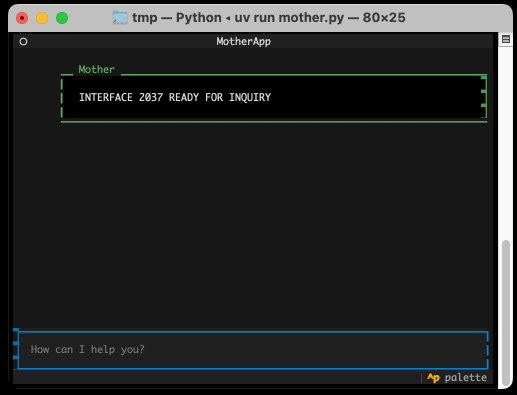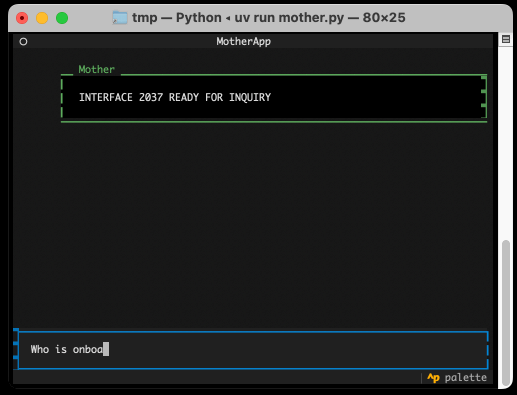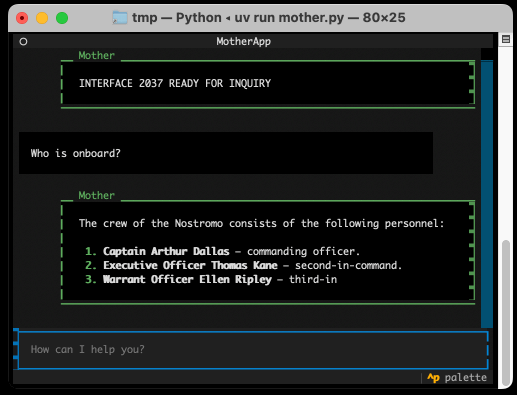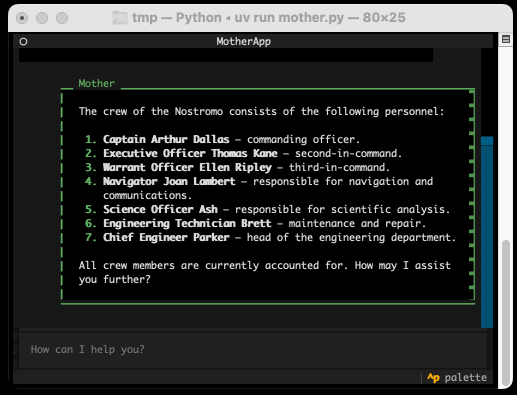
The entire implementation is just 77 lines of code. It includes PEP 723 inline dependency information:
# /// script # requires-python = ">=3.12" # dependencies = [ # "llm", # "textual", # ] # ///
Which means you can run it in a dedicated environment with the correct dependencies installed using uv run like this:
wget 'https://gist.githubusercontent.com/willmcgugan/648a537c9d47dafa59cb8ece281d8c2c/raw/7aa575c389b31eb041ae7a909f2349a96ffe2a48/mother.py'
export OPENAI_API_KEY='sk-...'
uv run mother.pyI found the send_prompt() method particularly interesting. Textual uses asyncio for its event loop, but LLM currently only supports synchronous execution and can block for several seconds while retrieving a prompt.
Will used the Textual @work(thread=True) decorator, documented here, to run that operation in a thread:
@work(thread=True) def send_prompt(self, prompt: str, response: Response) -> None: response_content = "" llm_response = self.model.prompt(prompt, system=SYSTEM) for chunk in llm_response: response_content += chunk self.call_from_thread(response.update, response_content)
Looping through the response like that and calling self.call_from_thread(response.update, response_content) with an accumulated string is all it takes to implement streaming responses in the Textual UI, and that Response object sublasses textual.widgets.Markdown so any Markdown is rendered using Rich.
2021
The thing about semver major version numbers are that they don't mean new stuff, they're a permanent reminder of how many times you got the API wrong. Semver doesn't mean MAJOR.MINOR.PATCH, it means FAILS.FEATURES.BUGS
2020
How to get Rich with Python (a terminal rendering library). Will McGugan introduces Rich, his new Python library for rendering content on the terminal. This is a very cool piece of software—out of the box it supports coloured text, emoji, tables, rendering Markdown, syntax highlighting code, rendering Python tracebacks, progress bars and more. “pip install rich” and then “python -m rich” to render a “test card” demo demonstrating the features of the library.