Large Language Models can run tools in your terminal with LLM 0.26
27th May 2025
LLM 0.26 is out with the biggest new feature since I started the project: support for tools. You can now use the LLM CLI tool—and Python library—to grant LLMs from OpenAI, Anthropic, Gemini and local models from Ollama with access to any tool that you can represent as a Python function.
LLM also now has tool plugins, so you can install a plugin that adds new capabilities to whatever model you are currently using.
There’s a lot to cover here, but here are the highlights:
-
LLM can run tools now! You can install tools from plugins and load them by name with
--tool/-T name_of_tool. - You can also pass in Python function code on the command-line with the
--functionsoption. - The Python API supports tools too:
llm.get_model("gpt-4.1").chain("show me the locals", tools=[locals]).text() - Tools work in both async and sync contexts.
Here’s what’s covered in this post:
- Trying it out
- More interesting tools from plugins
- Ad-hoc command-line tools with --functions
- Tools in the LLM Python API
- Why did this take me so long?
- Is this agents then?
- What’s next for tools in LLM?
Trying it out
First, install the latest LLM. It may not be on Homebrew yet so I suggest using pip or pipx or uv:
uv tool install llmIf you have it already, upgrade it.
uv tool upgrade llmTools work with other vendors, but let’s stick with OpenAI for the moment. Give LLM an OpenAI API key
llm keys set openai
# Paste key hereNow let’s run our first tool:
llm --tool llm_version "What version?" --tdHere’s what I get:
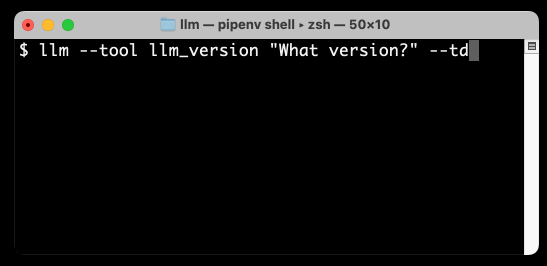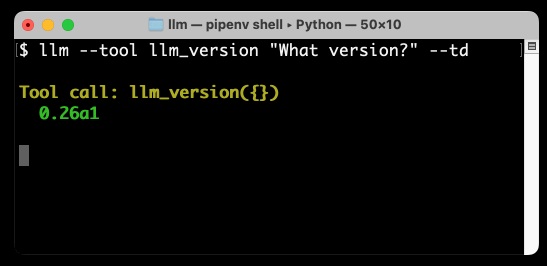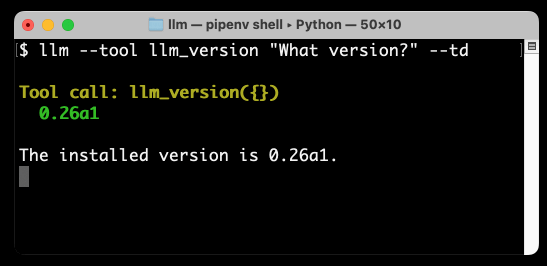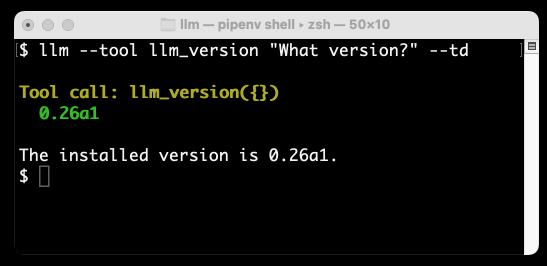
llm_version is a very simple demo tool that ships with LLM. Running --tool llm_version exposes that tool to the model—you can specify that multiple times to enable multiple tools, and it has a shorter version of -T to save on typing.
The --td option stands for --tools-debug—it causes LLM to output information about tool calls and their responses so you can peek behind the scenes.
This is using the default LLM model, which is usually gpt-4o-mini. I switched it to gpt-4.1-mini (better but fractionally more expensive) by running:
llm models default gpt-4.1-miniYou can try other models using the -m option. Here’s how to run a similar demo of the llm_time built-in tool using o4-mini:
llm --tool llm_time "What time is it?" --td -m o4-miniOutputs:
Tool call: llm_time({}){ "utc_time": "2025-05-27 19:15:55 UTC", "utc_time_iso": "2025-05-27T19:15:55.288632+00:00", "local_timezone": "PDT", "local_time": "2025-05-27 12:15:55", "timezone_offset": "UTC-7:00", "is_dst": true }The current time is 12:15 PM PDT (UTC−7:00) on May 27, 2025, which corresponds to 7:15 PM UTC.
Models from (tool supporting) plugins work too. Anthropic’s Claude Sonnet 4:
llm install llm-anthropic -U
llm keys set anthropic
# Paste Anthropic key here
llm --tool llm_version "What version?" --td -m claude-4-sonnetOr Google’s Gemini 2.5 Flash:
llm install llm-gemini -U
llm keys set gemini
# Paste Gemini key here
llm --tool llm_version "What version?" --td -m gemini-2.5-flash-preview-05-20You can even run simple tools with Qwen3:4b, a tiny (2.6GB) model that I run using Ollama:
ollama pull qwen3:4b
llm install 'llm-ollama>=0.11a0'
llm --tool llm_version "What version?" --td -m qwen3:4bQwen 3 calls the tool, thinks about it a bit and then prints out a response:
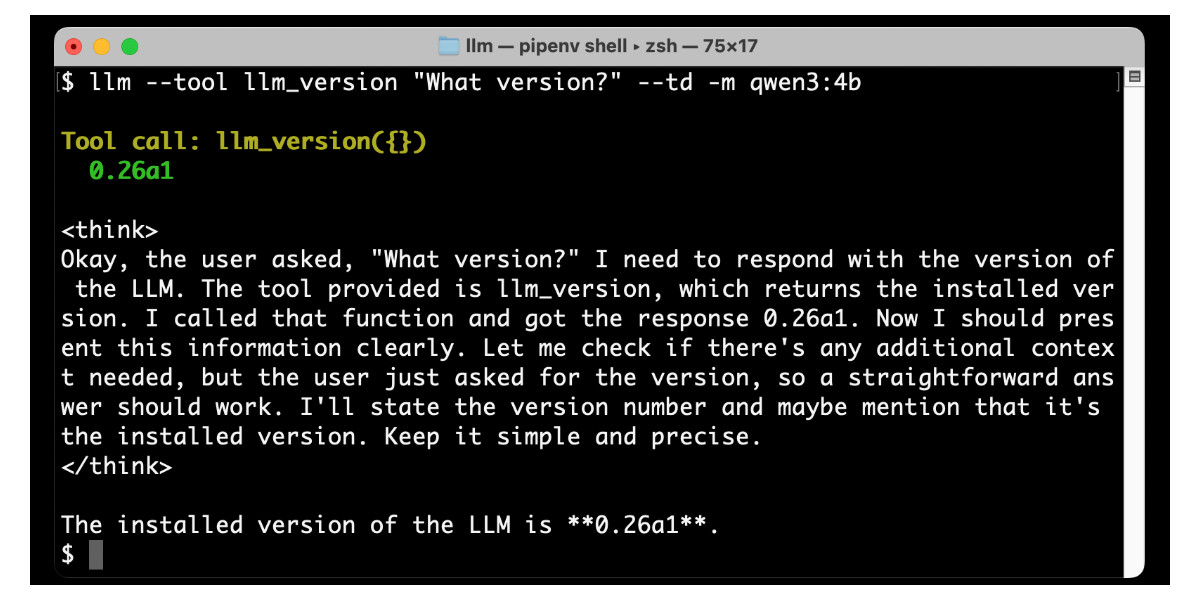
More interesting tools from plugins
This demo has been pretty weak so far. Let’s do something a whole lot more interesting.
LLMs are notoriously bad at mathematics. This is deeply surprising to many people: supposedly the most sophisticated computer systems we’ve ever built can’t multiply two large numbers together?
We can fix that with tools.
The llm-tools-simpleeval plugin exposes the simpleeval “Simple Safe Sandboxed Extensible Expression Evaluator for Python” library by Daniel Fairhead. This provides a robust-enough sandbox for executing simple Python expressions.
Here’s how to run a calculation:
llm install llm-tools-simpleeval
llm -T simpleeval Trying that out:
llm -T simple_eval 'Calculate 1234 * 4346 / 32414 and square root it' --tdI got back this—it tried sqrt() first, then when that didn’t work switched to ** 0.5 instead:
Tool call: simple_eval({'expression': '1234 * 4346 / 32414'})
165.45208860368976
Tool call: simple_eval({'expression': 'sqrt(1234 * 4346 / 32414)'})
Error: Function 'sqrt' not defined, for expression 'sqrt(1234 * 4346 / 32414)'.
Tool call: simple_eval({'expression': '(1234 * 4346 / 32414) ** 0.5'})
12.862818066181678
The result of (1234 * 4346 / 32414) is approximately
165.45, and the square root of this value is approximately 12.86.
I’ve released four tool plugins so far:
- llm-tools-simpleeval—as shown above, simple expression support for things like mathematics.
- llm-tools-quickjs—provides access to a sandboxed QuickJS JavaScript interpreter, allowing LLMs to run JavaScript code. The environment persists between calls so the model can set variables and build functions and reuse them later on.
- llm-tools-sqlite—read-only SQL query access to a local SQLite database.
- llm-tools-datasette—run SQL queries against a remote Datasette instance!
Let’s try that Datasette one now:
llm install llm-tools-datasette
llm -T 'Datasette("https://datasette.io/content")' --td "What has the most stars?"The syntax here is slightly different: the Datasette plugin is what I’m calling a “toolbox”—a plugin that has multiple tools inside it and can be configured with a constructor.
Specifying --tool as Datasette("https://datasette.io/content") provides the plugin with the URL to the Datasette instance it should use—in this case the content database that powers the Datasette website.
Here’s the output, with the schema section truncated for brevity:
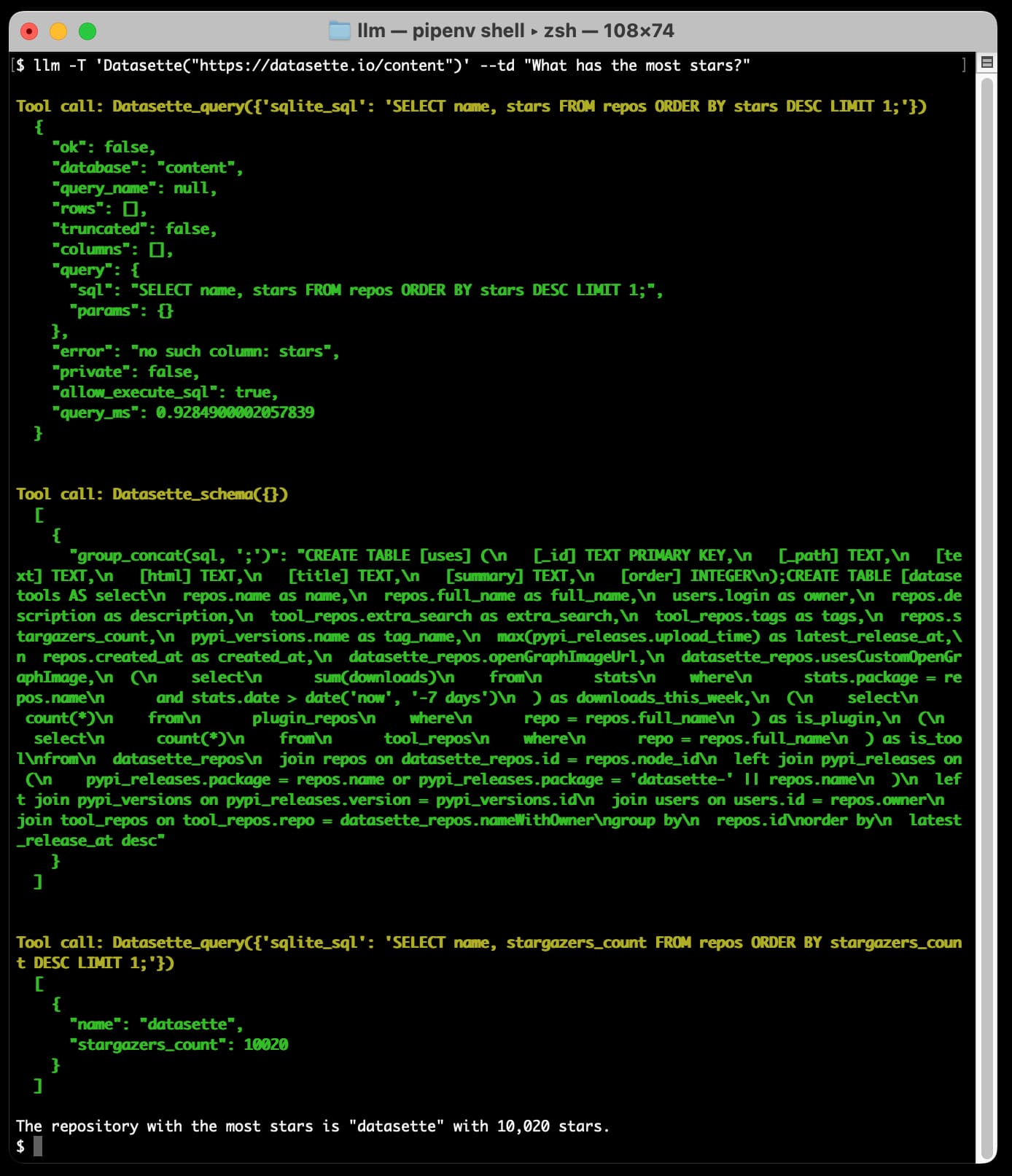
This question triggered three calls. The model started by guessing the query! It tried SELECT name, stars FROM repos ORDER BY stars DESC LIMIT 1, which failed because the stars column doesn’t exist.
The tool call returned an error, so the model had another go—this time calling the Datasette_schema() tool to get the schema of the database.
Based on that schema it assembled and then executed the correct query, and output its interpretation of the result:
The repository with the most stars is “datasette” with 10,020 stars.
Getting to this point was a real Penny Arcade Minecraft moment for me. The possibilities here are limitless. If you can write a Python function for it, you can trigger it from an LLM.
Ad-hoc command-line tools with --functions
I’m looking forward to people building more plugins, but there’s also much less structured and more ad-hoc way to use tools with the LLM CLI tool: the --functions option.
This was inspired by a similar feature I added to sqlite-utils a while ago.
You can pass a block of literal Python code directly to the CLI tool using the --functions option, and any functions defined there will be made available to the model as tools.
Here’s an example that adds the ability to search my blog:
llm --functions '
import httpx
def search_blog(q):
"Search Simon Willison blog"
return httpx.get("https://simonwillison.net/search/", params={"q": q}).content
' --td 'Three features of sqlite-utils' -s 'use Simon search'This is such a hack of an implementation! I’m literally just hitting my search page and dumping the HTML straight back into tho model.
It totally works though—it helps that the GPT-4.1 series all handle a million tokens now, so crufty HTML is no longer a problem for them.
(I had to add “use Simon search” as the system prompt because without it the model would try to answer the question itself, rather than using the search tool I provided. System prompts for tools are clearly a big topic, Anthropic’s own web search tool has 6,471 tokens of instructions!)
Here’s the output I got just now:
Three features of sqlite-utils are:
- It is a combined CLI tool and Python library for manipulating SQLite databases.
- It can automatically add columns to a database table if you attempt to insert data that doesn’t quite fit (using the alter=True option).
- It supports plugins, allowing the extension of its functionality through third-party or custom plugins.
A better search tool would have more detailed instructions and would return relevant snippets of the results, not just the headline and first paragraph for each result. This is pretty great for just four lines of Python though!
Tools in the LLM Python API
LLM is both a CLI tool and a Python library at the same time (similar to my other project sqlite-utils). The LLM Python library grew tool support in LLM 0.26 as well.
Here’s a simple example solving one of the previously hardest problems in LLMs: counting the number of Rs in “strawberry”:
import llm def count_char_in_text(char: str, text: str) -> int: "How many times does char appear in text?" return text.count(char) model = llm.get_model("gpt-4.1-mini") chain_response = model.chain( "Rs in strawberry?", tools=[count_char_in_text], after_call=print ) for chunk in chain_response: print(chunk, end="", flush=True)
The after_call=print argument is a way to peek at the tool calls, the Python equivalent of the --td option from earlier.
The model.chain() method is new: it’s similar to model.prompt() but knows how to spot returned tool call requests, execute them and then prompt the model again with the results. A model.chain() could potentially execute dozens of responses on the way to giving you a final answer.
You can iterate over the chain_response to output those tokens as they are returned by the model, even across multiple responses.
I got back this:
Tool(name='count_char_in_text', description='How many times does char appear in text?', input_schema={'properties': {'char': {'type': 'string'}, 'text': {'type': 'string'}}, 'required': ['char', 'text'], 'type': 'object'}, implementation=<function count_char_in_text at 0x109dd4f40>, plugin=None) ToolCall(name='count_char_in_text', arguments={'char': 'r', 'text': 'strawberry'}, tool_call_id='call_DGXcM8b2B26KsbdMyC1uhGUu') ToolResult(name='count_char_in_text', output='3', tool_call_id='call_DGXcM8b2B26KsbdMyC1uhGUu', instance=None, exception=None)There are 3 letter “r”s in the word “strawberry”.
LLM’s Python library also supports asyncio, and tools can be async def functions as described here. If a model requests multiple async tools at once the library will run them concurrently with asyncio.gather().
The Toolbox form of tools is supported too: you can pass tools=[Datasette("https://datasette.io/content")] to that chain() method to achieve the same effect as the --tool 'Datasette(...) option from earlier.
Why did this take me so long?
I’ve been tracking llm-tool-use for a while. I first saw the trick described in the ReAcT paper, first published in October 2022 (a month before the initial release of ChatGPT). I built a simple implementation of that in a few dozen lines of Python. It was clearly a very neat pattern!
Over the past few years it has become very apparent that tool use is the single most effective way to extend the abilities of language models. It’s such a simple trick: you tell the model that there are tools it can use, and have it output special syntax (JSON or XML or tool_name(arguments), it doesn’t matter which) requesting a tool action, then stop.
Your code parses that output, runs the requested tools and then starts a new prompt to the model with the results.
This works with almost every model now. Most of them are specifically trained for tool usage, and there are leaderboards like the Berkeley Function-Calling Leaderboard dedicated to tracking which models do the best job of it.
All of the big model vendors—OpenAI, Anthropic, Google, Mistral, Meta—have a version of this baked into their API, either called tool usage or function calling. It’s all the same underlying pattern.
The models you can run locally are getting good at this too. Ollama added tool support last year, and it’s baked into the llama.cpp server as well.
It’s been clear for a while that LLM absolutely needed to grow support for tools. I released LLM schema support back in February as a stepping stone towards this. I’m glad to finally have it over the line.
As always with LLM, the challenge was designing an abstraction layer that could work across as many different models as possible. A year ago I didn’t feel that model tool support was mature enough to figure this out. Today there’s a very definite consensus among vendors about how this should work, which finally gave me the confidence to implement it.
I also presented a workshop at PyCon US two weeks ago about Building software on top of Large Language Models, which was exactly the incentive I needed to finally get this working in an alpha! Here’s the tools section from that tutorial.
Is this agents then?
Sigh.
I still don’t like using the term “agents”. I worry that developers will think tools in a loop, regular people will think virtual AI assistants voiced by Scarlett Johansson and academics will grumble about thermostats. But in the LLM world we appear to be converging on “tools in a loop”, and that’s absolutely what this.
So yes, if you want to build “agents” then LLM 0.26 is a great way to do that.
What’s next for tools in LLM?
I already have a LLM tools v2 milestone with 13 issues in it, mainly around improvements to how tool execution logs are displayed but with quite a few minor issues I decided shouldn’t block this release. There’s a bunch more stuff in the tools label.
I’m most excited about the potential for plugins.
Writing tool plugins is really fun. I have an llm-plugin-tools cookiecutter template that I’ve been using for my own, and I plan to put together a tutorial around that soon.
There’s more work to be done adding tool support to more model plugins. I added details of this to the advanced plugins documentation. This commit adding tool support for Gemini is a useful illustratino of what’s involved.
And yes, Model Context Protocol support is clearly on the agenda as well. MCP is emerging as the standard way for models to access tools at a frankly bewildering speed. Two weeks ago it wasn’t directly supported by the APIs of any of the major vendors. In just the past eight days it’s been added by OpenAI, Anthropic and Mistral! It’s feeling like a lot less of a moving target today.
I want LLM to be able to act as an MCP client, so that any of the MCP servers people are writing can be easily accessed as additional sources of tools for LLM.
If you’re interested in talking more about what comes next for LLM, come and chat to us in our Discord.
More recent articles
- Mr. Chatterbox is a (weak) Victorian-era ethically trained model you can run on your own computer - 30th March 2026
- Vibe coding SwiftUI apps is a lot of fun - 27th March 2026
- Experimenting with Starlette 1.0 with Claude skills - 22nd March 2026