17th March 2025 - Link Blog
OpenTimes (via) Spectacular new open geospatial project by Dan Snow:
OpenTimes is a database of pre-computed, point-to-point travel times between United States Census geographies. It lets you download bulk travel time data for free and with no limits.
Here's what I get for travel times by car from El Granada, California:
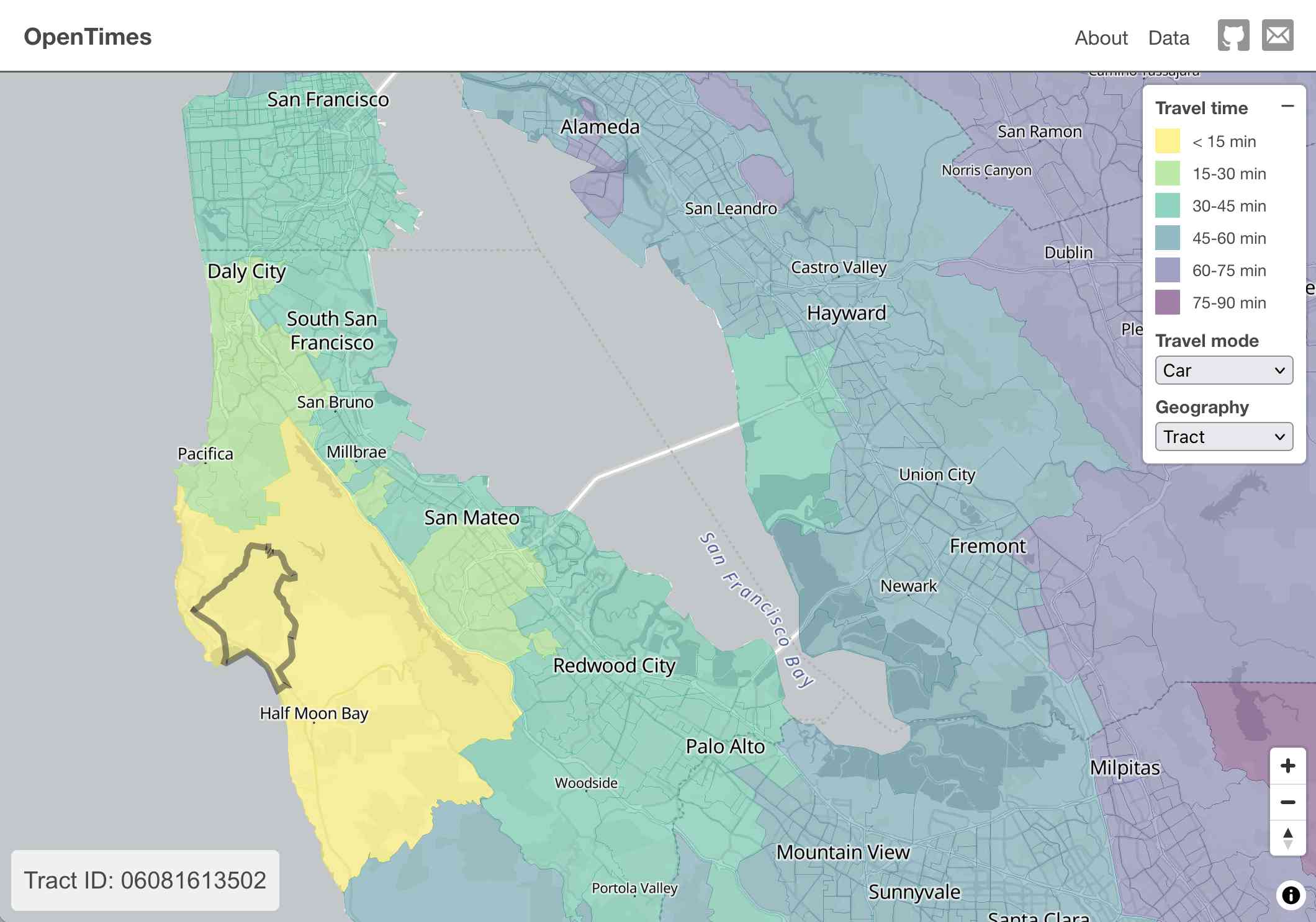
The technical details are fascinating:
- The entire OpenTimes backend is just static Parquet files on Cloudflare's R2. There's no RDBMS or running service, just files and a CDN. The whole thing costs about $10/month to host and costs nothing to serve. In my opinion, this is a great way to serve infrequently updated, large public datasets at low cost (as long as you partition the files correctly).
Sure enough, R2 pricing charges "based on the total volume of data stored" - $0.015 / GB-month for standard storage, then $0.36 / million requests for "Class B" operations which include reads. They charge nothing for outbound bandwidth.
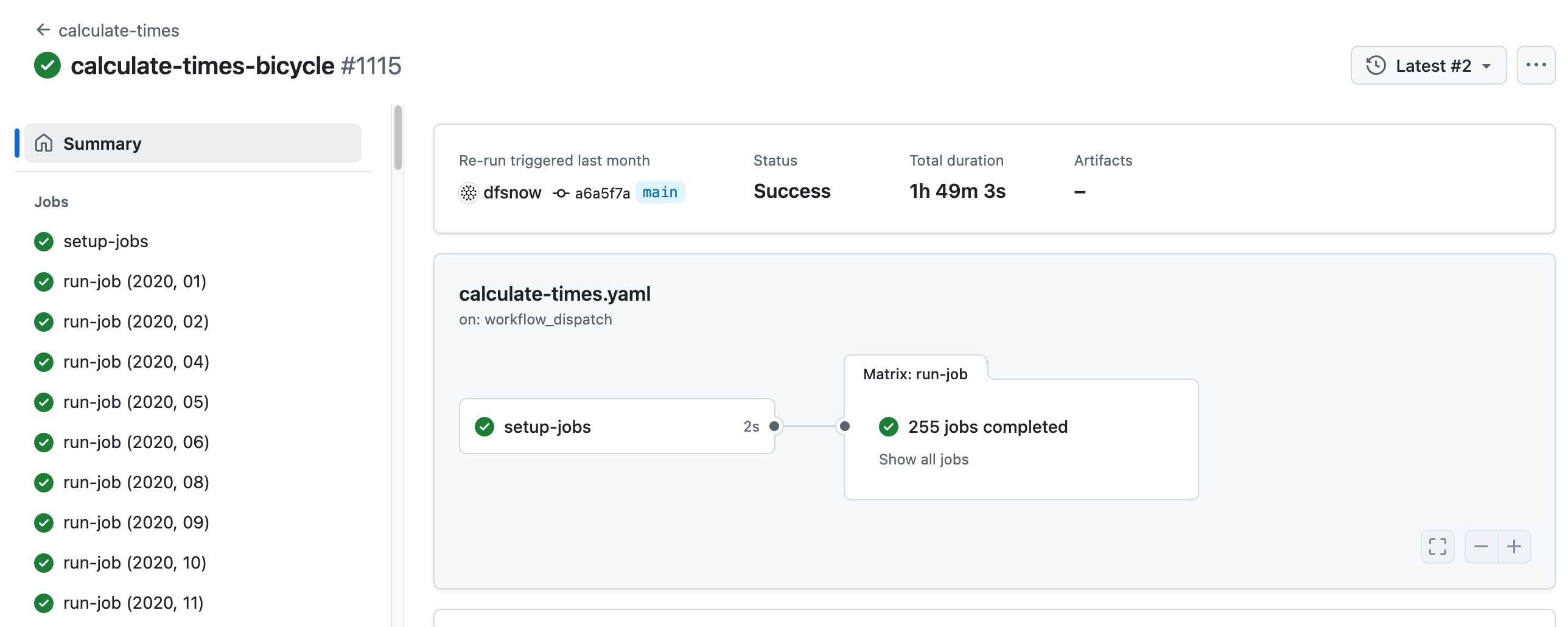
- All travel times were calculated by pre-building the inputs (OSM, OSRM networks) and then distributing the compute over hundreds of GitHub Actions jobs. This worked shockingly well for this specific workload (and was also completely free).
Here's a GitHub Actions run of the calculate-times.yaml workflow which uses a matrix to run 255 jobs!
Relevant YAML:
matrix:
year: ${{ fromJSON(needs.setup-jobs.outputs.years) }}
state: ${{ fromJSON(needs.setup-jobs.outputs.states) }}
Where those JSON files were created by the previous step, which reads in the year and state values from this params.yaml file.
- The query layer uses a single DuckDB database file with views that point to static Parquet files via HTTP. This lets you query a table with hundreds of billions of records after downloading just the ~5MB pointer file.
This is a really creative use of DuckDB's feature that lets you run queries against large data from a laptop using HTTP range queries to avoid downloading the whole thing.
The README shows how to use that from R and Python - I got this working in the duckdb client (brew install duckdb):
INSTALL httpfs;
LOAD httpfs;
ATTACH 'https://data.opentimes.org/databases/0.0.1.duckdb' AS opentimes;
SELECT origin_id, destination_id, duration_sec
FROM opentimes.public.times
WHERE version = '0.0.1'
AND mode = 'car'
AND year = '2024'
AND geography = 'tract'
AND state = '17'
AND origin_id LIKE '17031%' limit 10;
In answer to a question about adding public transit times Dan said:
In the next year or so maybe. The biggest obstacles to adding public transit are:
- Collecting all the necessary scheduling data (e.g. GTFS feeds) for every transit system in the county. Not insurmountable since there are services that do this currently.
- Finding a routing engine that can compute nation-scale travel time matrices quickly. Currently, the two fastest open-source engines I've tried (OSRM and Valhalla) don't support public transit for matrix calculations and the engines that do support public transit (R5, OpenTripPlanner, etc.) are too slow.
GTFS is a popular CSV-based format for sharing transit schedules - here's an official list of available feed directories.
This whole project feels to me like a great example of the baked data architectural pattern in action.
Recent articles
- The Axios supply chain attack used individually targeted social engineering - 3rd April 2026
- Highlights from my conversation about agentic engineering on Lenny's Podcast - 2nd April 2026
- Mr. Chatterbox is a (weak) Victorian-era ethically trained model you can run on your own computer - 30th March 2026