Monday, 2nd September 2024
Anatomy of a Textual User Interface. Will McGugan used Textual and my LLM Python library to build a delightful TUI for talking to a simulation of Mother, the AI from the Aliens movies:
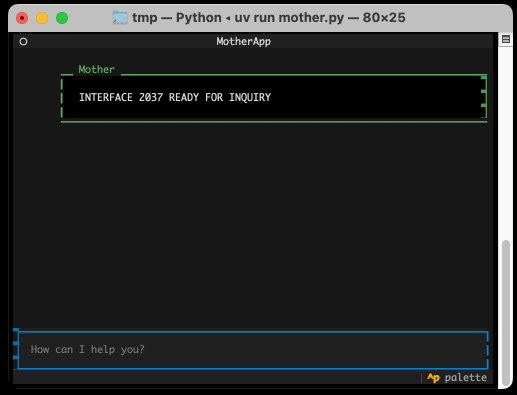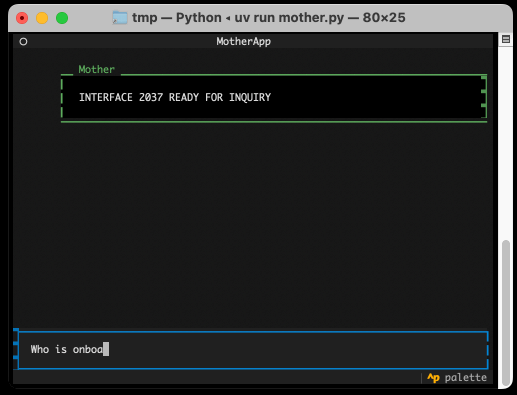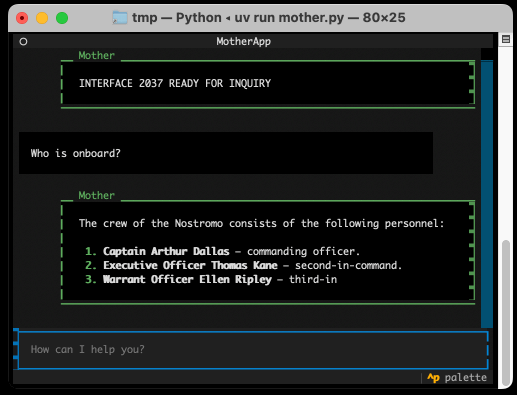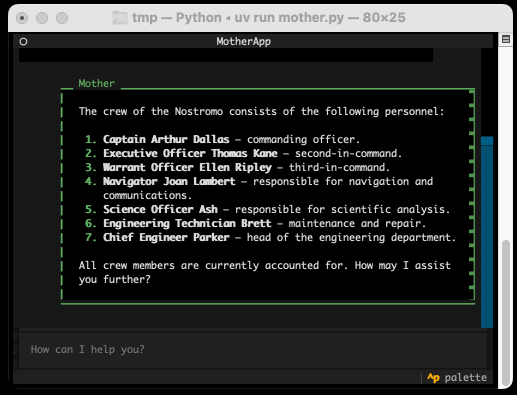
The entire implementation is just 77 lines of code. It includes PEP 723 inline dependency information:
# /// script # requires-python = ">=3.12" # dependencies = [ # "llm", # "textual", # ] # ///
Which means you can run it in a dedicated environment with the correct dependencies installed using uv run like this:
wget 'https://gist.githubusercontent.com/willmcgugan/648a537c9d47dafa59cb8ece281d8c2c/raw/7aa575c389b31eb041ae7a909f2349a96ffe2a48/mother.py'
export OPENAI_API_KEY='sk-...'
uv run mother.pyI found the send_prompt() method particularly interesting. Textual uses asyncio for its event loop, but LLM currently only supports synchronous execution and can block for several seconds while retrieving a prompt.
Will used the Textual @work(thread=True) decorator, documented here, to run that operation in a thread:
@work(thread=True) def send_prompt(self, prompt: str, response: Response) -> None: response_content = "" llm_response = self.model.prompt(prompt, system=SYSTEM) for chunk in llm_response: response_content += chunk self.call_from_thread(response.update, response_content)
Looping through the response like that and calling self.call_from_thread(response.update, response_content) with an accumulated string is all it takes to implement streaming responses in the Textual UI, and that Response object sublasses textual.widgets.Markdown so any Markdown is rendered using Rich.
In Leak, Facebook Partner Brags About Listening to Your Phone’s Microphone to Serve Ads for Stuff You Mention. (I've repurposed some of my comments on Lobsters into this commentary on this article. See also I still don’t think companies serve you ads based on spying through your microphone.)
Which is more likely?
- All of the conspiracy theories are real! The industry managed to keep the evidence from us for decades, but finally a marketing agency of a local newspaper chain has blown the lid off the whole thing, in a bunch of blog posts and PDFs and on a podcast.
- Everyone believed that their phone was listening to them even when it wasn’t. The marketing agency of a local newspaper chain were the first group to be caught taking advantage of that widespread paranoia and use it to try and dupe people into spending money with them, despite the tech not actually working like that.
My money continues to be on number 2.
Here’s their pitch deck. My “this is a scam” sense is vibrating like crazy reading it: CMG Pitch Deck on Voice-Data Advertising 'Active Listening'.
It does not read to me like the deck of a company that has actually shipped their own app that tracks audio and uses it for even the most basic version of ad targeting.
They give the game away on the last two slides:
Prep work:
- Create buyer personas by uploading past consumer data into the platform
- Identify top performing keywords relative to your products and services by analyzing keyword data and past ad campaigns
- Ensure tracking is set up via a tracking pixel placed on your site or landing page
Now that preparation is done:
- Active listening begins in your target geo and buyer behavior is detected across 470+ data sources […]
Our technology analyzes over 1.9 trillion behaviors daily and collects opt-in customer behavior data from hundreds of popular websites that offer top display, video platforms, social applications, and mobile marketplaces that allow laser-focused media buying.
Sources include: Google, LinkedIn, Facebook, Amazon and many more
That’s not describing anything ground-breaking or different. That’s how every targeting ad platform works: you upload a bunch of “past consumer data”, identify top keywords and setup a tracking pixel.
I think active listening is the term that the team came up with for “something that sounds fancy but really just means the way ad targeting platforms work already”. Then they got over-excited about the new metaphor and added that first couple of slides that talk about “voice data”, without really understanding how the tech works or what kind of a shitstorm that could kick off when people who DID understand technology started paying attention to their marketing.
TechDirt's story Cox Media Group Brags It Spies On Users With Device Microphones To Sell Targeted Ads, But It’s Not Clear They Actually Can included a quote with a clarification from Cox Media Group:
CMG businesses do not listen to any conversations or have access to anything beyond a third-party aggregated, anonymized and fully encrypted data set that can be used for ad placement. We regret any confusion and we are committed to ensuring our marketing is clear and transparent.
Why I don't buy the argument that it's OK for people to believe this
I've seen variants of this argument before: phones do creepy things to target ads, but it’s not exactly “listen through your microphone” - but there’s no harm in people believing that if it helps them understand that there’s creepy stuff going on generally.
I don’t buy that. Privacy is important. People who are sufficiently engaged need to be able to understand exactly what’s going on, so they can e.g. campaign for legislators to reign in the most egregious abuses.
I think it’s harmful letting people continue to believe things about privacy that are not true, when we should instead be helping them understand the things that are true.
This discussion thread is full of technically minded, engaged people who still believe an inaccurate version of what their devices are doing. Those are the people that need to have an accurate understanding, because those are the people that can help explain it to others and can hopefully drive meaningful change.
This is such a damaging conspiracy theory.
- It’s causing some people to stop trusting their most important piece of personal technology: their phone.
- We risk people ignoring REAL threats because they’ve already decided to tolerate made up ones.
- If people believe this and see society doing nothing about it, that’s horrible. That leads to a cynical “nothing can be fixed, I guess we will just let bad people get away with it” attitude. People need to believe that humanity can prevent this kind of abuse from happening.
The fact that nobody has successfully produced an experiment showing that this is happening is one of the main reasons I don’t believe it to be happening.
It’s like James Randi’s One Million Dollar Paranormal Challenge - the very fact that nobody has been able to demonstrate it is enough for me not to believe in it.
Why I Still Use Python Virtual Environments in Docker (via) Hynek Schlawack argues for using virtual environments even when running Python applications in a Docker container. This argument was most convincing to me:
I'm responsible for dozens of services, so I appreciate the consistency of knowing that everything I'm deploying is in
/app, and if it's a Python application, I know it's a virtual environment, and if I run/app/bin/python, I get the virtual environment's Python with my application ready to be imported and run.
Also:
It’s good to use the same tools and primitives in development and in production.
Also worth a look: Hynek's guide to Production-ready Docker Containers with uv, an actively maintained guide that aims to reflect ongoing changes made to uv itself.