ChatGPT in “4o” mode is not running the new features yet
15th May 2024
Monday’s OpenAI announcement of their new GPT-4o model included some intriguing new features:
- Creepily good improvements to the ability to both understand and produce voice (Sam Altman simply tweeted “her”), and to be interrupted mid-sentence
- New image output capabilities that appear to leave existing models like DALL-E 3 in the dust—take a look at the examples, they seem to have solved consistent character representation AND reliable text output!
They also made the new 4o model available to paying ChatGPT Plus users, on the web and in their apps.
But, crucially, those big new features were not part of that release.
Update 10th December 2024: ChatGPT Advanced Voice Mode has now been available in the mobile apps (and desktop app) for a few months, but advanced image output mode still isn’t available yet.
Here’s the relevant section from the announcement post:
We recognize that GPT-4o’s audio modalities present a variety of novel risks. Today we are publicly releasing text and image inputs and text outputs. Over the upcoming weeks and months, we’ll be working on the technical infrastructure, usability via post-training, and safety necessary to release the other modalities.
This is catching out a lot of people. The ChatGPT iPhone app already has image output, and it already has a voice mode. These worked with the previous GPT-4 mode and they still work with the new GPT-4o mode... but they are not using the new model’s capabilities.
Lots of people are discovering the voice mode for the first time—it’s the headphone icon in the bottom right of the interface.
They try it and it’s impressive (it was impressive before) but it’s nothing like as good as the voice mode in Monday’s demos.
Honestly, it’s not at all surprising that people are confused. They’re seeing the “4o” option and, understandably, are assuming that this is the set of features that were announced earlier this week.
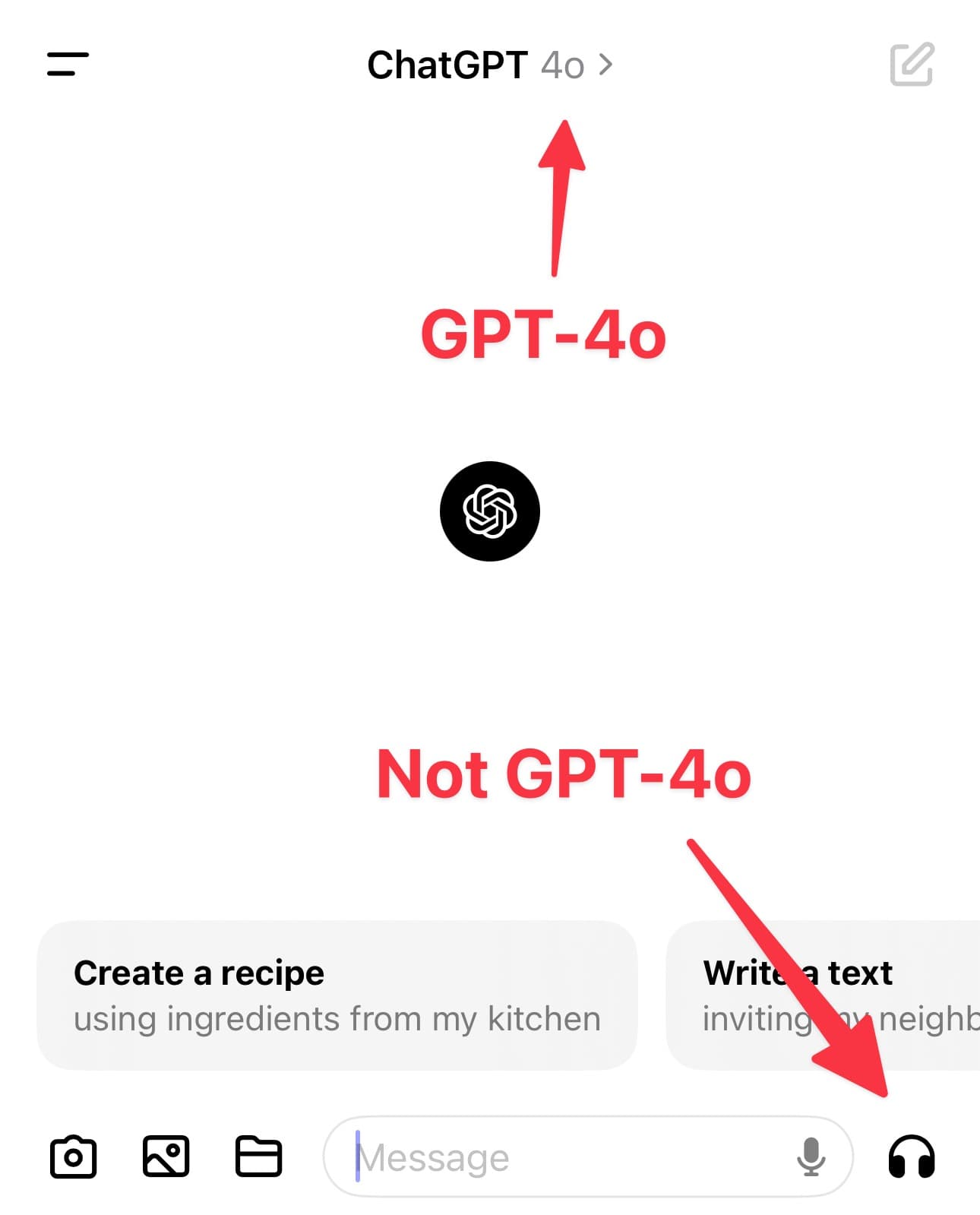
Most people don’t distinguish models from features
Think about what you need to know in order to understand what’s going on here:
GPT-4o is a brand new multi-modal Large Language Model. It can handle text, image and audio input and produce text, image and audio output.
But... the version of GPT-4o that has been made available so far—both via the API and via the OpenAI apps—is only able to handle text and image input and produce text output. The other features are not yet available outside of OpenAI (and a select group of partners).
And yet in the apps it can still handle audio input and output and generate images. That’s because the app version of the model is wrapped with additional tools.
The audio input is handled by a separate model called Whisper, which converts speech to text. That text is then fed into the LLM, which generates a text response.
The response is passed to OpenAI’s boringly-named tts-1 (or maybe tts-1-hd) model (described here), which converts that text to speech.
While nowhere near as good as the audio in Monday’s demo, tts-1 is still a really impressive model. I’ve been using it via my ospeak CLI tool since it was released back in November.
As for images? Those are generated using DALL-E 3, through a process where ChatGPT directly prompts that model. I wrote about how that works back in October.
So what’s going on with ChatGPT’s GPT-4o mode is completely obvious, provided you already understand:
- GPT-4 v.s. GPT-4o
- Whisper
tts-1- DALL-E 3
- Why OpenAI would demonstrate these features and then release a version of the model that doesn’t include them
I’m reminded of the kerfluffle back in March when the Google Gemini image creator was found to generate images of Black Nazis. I saw a whole bunch of people refer to that in conversations about the Google Gemini Pro 1.5 LLM, released at the same time, despite the quality of that model being entirely unrelated to Google’s policy decisions about how one of the interfaces to that model should make use of the image creator tool.
What can we learn from this?
If you’re fully immersed in this world, it’s easy to lose track of how incredibly complicated these systems have become. The amount you have to know in order to even understand what that “4o” mode in the ChatGPT app does is very easy to underestimate.
Fundamentally these are challenges in user experience design. You can’t just write documentation about them, because no-one reads documentation.
A good starting here is to acknowledge the problem. LLM systems are extremely difficult to understand and use. We need to design the tools we build on top of them accordingly.
Update: a UI workaround
On May 16th around 1PM PT OpenAI released a new iPhone app update which adds the following warning message the first time you try to access that headphones icon:
New Voice Mode coming soon
We plan to launch a new Voice Mode with new GPT-4o capabilities in an alpha within ChatGPT Plus in the coming weeks. We’ll let you know when you have access.
More recent articles
- Meta's new model is Muse Spark, and meta.ai chat has some interesting tools - 8th April 2026
- Anthropic's Project Glasswing - restricting Claude Mythos to security researchers - sounds necessary to me - 7th April 2026
- The Axios supply chain attack used individually targeted social engineering - 3rd April 2026