Sunday, 29th December 2024
Google search hallucinates Encanto 2. Jason Schreier on Bluesky:
I was excited to tell my kids that there's a sequel to Encanto, only to scroll down and learn that Google's AI just completely made this up
I just replicated the same result by searching Google for encanto 2. Here's what the "AI overview" at the top of the page looked like:
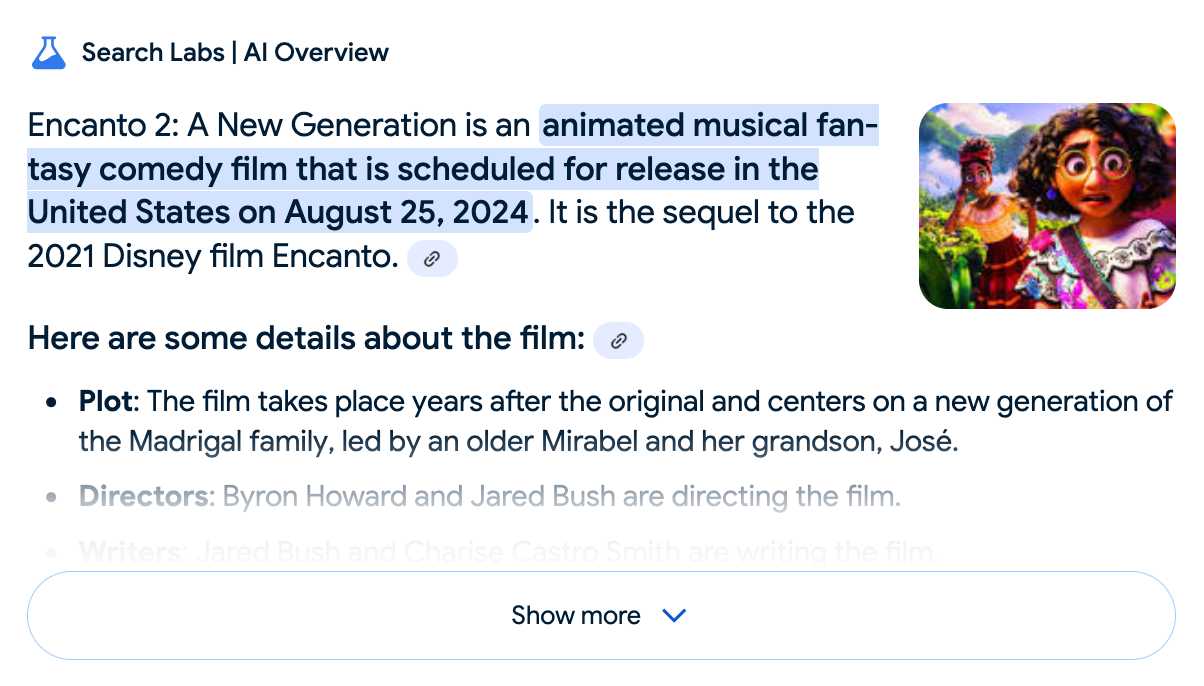
Only when I clicked the "Show more" link did it become clear what had happened:

The link in that first snippet was to the Encanto 2: A New Generation page on Idea Wiki:
This is a fanon wiki, and just like fan-fiction wikis, this one has a variety of fan created ideas on here! These include potential sequels and new series that have yet to exist.
Other cited links included this article about Instagram fan art and Encanto's Sequel Chances Addressed by Disney Director, a very thin article built around a short quote from Encanto's director at D23 Brazil.
And that August 2024 release date (which the AI summary weirdly lists as "scheduled for release" despite that date being five months in the past)? It's from the Idea Wiki imaginary info box for the film.
This is a particularly clear example of how badly wrong AI summarization can go. LLMs are gullible: they believe what you tell them, and the web is full of misleading information - some of which is completely innocent.
Update: I've had some pushback over my use of the term "hallucination" here, on the basis that the LLM itself is doing what it's meant to: summarizing the RAG content that has been provided to it by the host system.
That's fair: this is not a classic LLM hallucination, where the LLM produces incorrect data purely from knowledge partially encoded in its weights.
I classify this as a bug in Google's larger LLM-powered AI overview system. That system should be able to take the existence of invalid data sources into account - given how common searches for non-existent movie sequels (or TV seasons) are, I would hope that AI overviews could classify such searches and take extra steps to avoid serving misleading answers.
So think this is a "hallucination" bug in the AI overview system itself: it's making statements about the world that are not true.
How we think about Threads’ iOS performance (via) This article by Dave LaMacchia and Jason Patterson provides an incredibly deep insight into what effective performance engineering looks like for an app with 100s of millions of users.
I always like hearing about custom performance metrics with their own acronyms. Here we are introduced to %FIRE - the portion of people who experience a frustrating image-render experience (based on how long an image takes to load after the user scrolls it into the viewport), TTNC (time-to-network content) measuring time from app launch to fresh content visible in the feed and cPSR (creation-publish success rate) for how often a user manages to post content that they started to create.
This article introduced me to the concept of a boundary test, described like this:
A boundary test is one where we measure extreme ends of a boundary to learn what the effect is. In our case, we introduced a slight bit of latency when a small percentage of our users would navigate to a user profile, to the conversion view for a post, or to their activity feed.
This latency would allow us to extrapolate what the effect would be if we similarly improved how we delivered content to those views.
[...]
We learned that iOS users don’t tolerate a lot of latency. The more we added, the less often they would launch the app and the less time they would stay in it. With the smallest latency injection, the impact was small or negligible for some views, but the largest injections had negative effects across the board. People would read fewer posts, post less often themselves, and in general interact less with the app. Remember, we weren’t injecting latency into the core feed, either; just into the profile, permalink, and activity.
There's a whole lot more in there, including details of their custom internal performance logger (SLATE, the “Systemic LATEncy” logger) and several case studies of surprising performance improvements made with the assistance of their metrics and tools, plus some closing notes on how Swift concurrency is being adopted throughout Meta.
What's holding back research isn't a lack of verbose, low-signal, high-noise papers. Using LLMs to automatically generate 100x more of those will not accelerate science, it will slow it down.
— François Chollet, 12th May 2024