Gemini 2.0 Flash: An outstanding multi-modal LLM with a sci-fi streaming mode
11th December 2024
Huge announcment from Google this morning: Introducing Gemini 2.0: our new AI model for the agentic era. There’s a ton of stuff in there (including updates on Project Astra and the new Project Mariner), but the most interesting pieces are the things we can start using today, built around the brand new Gemini 2.0 Flash model. The developer blog post has more of the technical details, and the Gemini 2.0 Cookbook is useful for understanding the API via Python code examples.
Gemini 2.0 Flash is a multi-modal LLM. Google claim it’s both more capable and twice as fast as Gemini 1.5 Pro, their previous best model.
The new Flash can handle the same full range of multi-modal inputs as the Gemini 1.5 series: images, video, audio and documents. Unlike the 1.5 series it can output in multiple modalities as well—images and audio in addition to text. The image and audio outputs aren’t yet generally available but should be coming early next year.
It also introduces streaming capabilities which are wildly impressive. More on that later in this post.
- Running a vision prompt using llm-gemini
- Impressive performance on spatial reasoning
- It can both write and execute code
- The streaming API is next level
- Things to look forward to
Let’s start by trying it out as a multi-modal input, text output model.
Running a vision prompt using llm-gemini
I released llm-gemini 0.7 adding support for the new model to my LLM command-line tool. You’ ll need a Gemini API key—then install LLM and run:
llm install -U llm-gemini
llm keys set gemini
# ... paste API key here
llm -m gemini-2.0-flash-exp describe \
-a https://static.simonwillison.net/static/2024/pelicans.jpgThat’s using my pelicans.jpg image as input, a low resolution photograph of a confusing mass of pelicans on a rocky outcrop. It’s a good starting point for exploring a model’s vision capabilities.

The full transcript is here. This is one of the best results I’ve seen:
Overall Scene:
The image depicts a large group of pelicans and other birds gathered closely together on a rocky outcrop. The birds are densely packed, with many overlapping and almost blending into one another. Behind them is a body of water with a dark shoreline or cliff visible in the distance. The scene appears to be taken on a relatively sunny day, with good lighting that illuminates the birds.
Birds:
- Pelicans: The most prominent birds are the brown pelicans, characterized by their large, gray-brown bodies, long beaks, and prominent throat pouches. Some pelicans have white on their heads, suggesting that some of them are older birds. They are in various poses, some standing upright, others preening or interacting. They are positioned at the middle and upper parts of the rocks.
- Smaller Birds: There are also many smaller, darker birds, possibly cormorants or gulls, scattered throughout the scene. They are often found closer to the ground. They all seem to have a similar appearance with dark plumage and short beaks. These are mixed in with and around the pelicans.
- Arrangement: The birds appear clustered together. They are on top of the rocks in a way that shows that they are using the rocky outcropping as a place to rest. It is a crowded scene.
Environment:
- Rocks: The birds are resting on a light-colored, rough rocky surface. It appears to be a natural outcropping, with various textured surfaces. The rocks form the base of the picture.
- Water: In the background, there is a dark body of water, possibly the sea or a large lake. The water is mostly smooth, adding a sense of calm to the scene.
- Background: There seems to be a rocky shore or cliff face in the far background. The background provides a contrast to the lighter colored rock surface and birds. The background is dark, almost solid colored.
Lighting and Color:
- Light: The lighting in the photo is natural, bright, and provides plenty of detail on the birds’ feathers. It appears to be coming from overhead, and there are minimal harsh shadows.
- Colors: The color palette is mostly earthy tones. The pelicans have variations of browns and grays with white. The smaller birds are in shades of dark grey and browns. The rocks are a light grey, almost white, and the background is a dark gray.
Overall Impression:
The overall impression is that of a busy, natural habitat where various birds gather together. The image captures the wildness and the coexistence of different bird species. The scene feels peaceful and serene despite the large number of animals.
A white head on a California Brown Pelican is breeding plumage, which does indeed indicate they are older birds.
Impressive performance on spatial reasoning
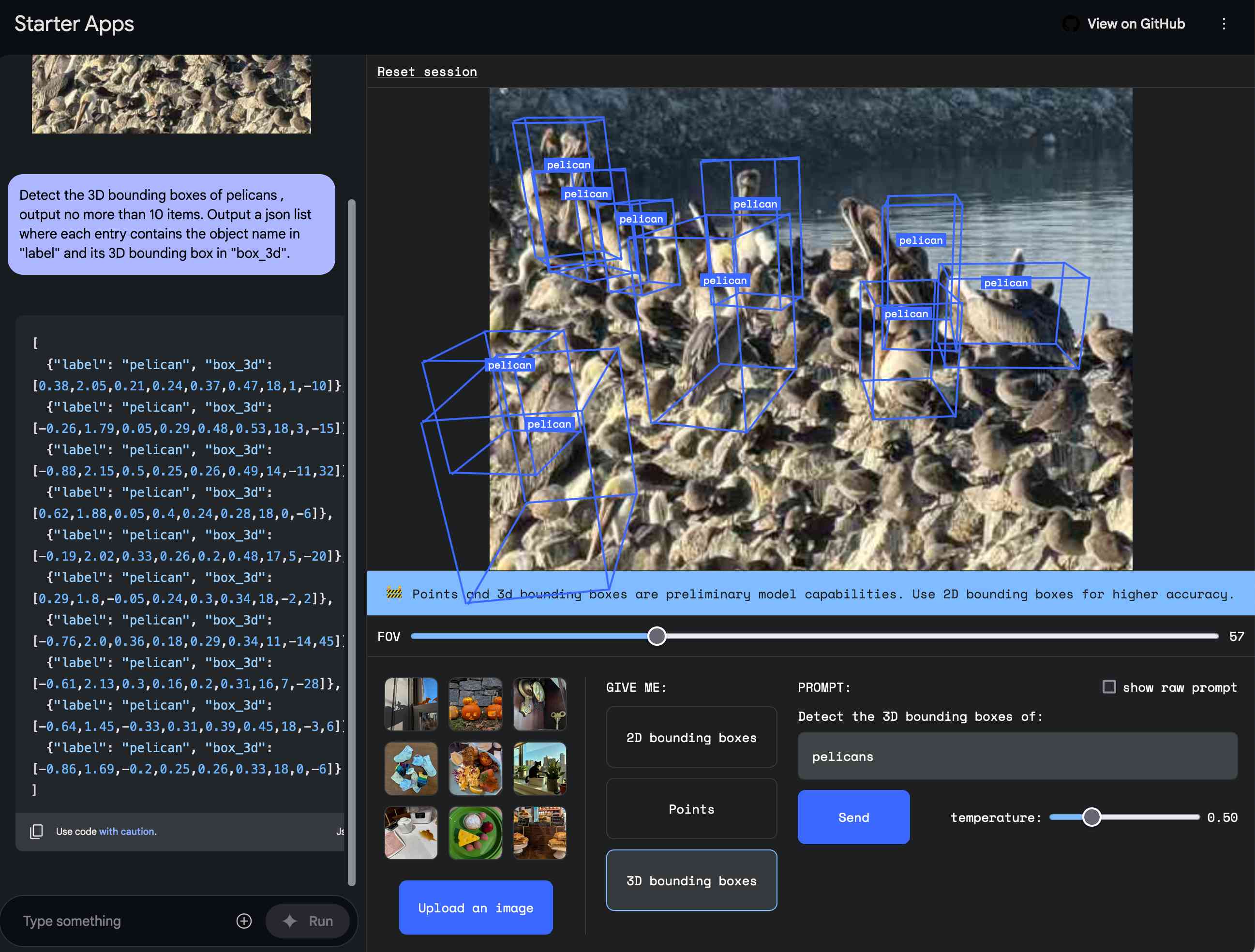
One of the most interesting characteristics of the Gemini 1.5 series is its ability to return bounding boxes for objects within an image. I described a tool I built for exploring that in Building a tool showing how Gemini Pro can return bounding boxes for objects in images back in August.
I upgraded that tool to support Gemini 2.0 Flash and ran my pelican photo through, with this prompt:
Return bounding boxes around all pelicans as JSON arrays [ymin, xmin, ymax, xmax]
Here’s what I got back, overlayed on the image by my tool:

Given how complicated that photograph is I think this is a pretty amazing result.
AI Studio now offers its own Spatial Understanding demo app which can be used to try out this aspect of the model, including the ability to return “3D bounding boxes” which I still haven’t fully understood!
Google published a short YouTube video about Gemini 2.0’s spatial understanding.
It can both write and execute code
The Gemini 1.5 Pro models have this ability too: you can ask the API to enable a code execution mode, which lets the models write Python code, run it and consider the result as part of their response.
Here’s how to access that using LLM, with the -o code_execution 1 flag:
llm -m gemini-2.0-flash-exp -o code_execution 1 \
'write and execute python to generate a 80x40 ascii art fractal'The full response is here—here’s what it drew for me:

The code environment doesn’t have access to make outbound network calls. I tried this:
llm -m gemini-2.0-flash-exp -o code_execution 1 \
'write python code to retrieve https://simonwillison.net/ and use a regex to extract the title, run that code'And the model attempted to use requests, realized it didn’t have it installed, then tried urllib.request and got a Temporary failure in name resolution error.
Amusingly it didn’t know that it couldn’t access the network, but it gave up after a few more tries.
The streaming API is next level
The really cool thing about Gemini 2.0 is the brand new streaming API. This lets you open up a two-way stream to the model sending audio and video to it and getting text and audio back in real time.
I urge you to try this out right now using https://aistudio.google.com/live. It works for me in Chrome on my laptop and Mobile Safari on my iPhone—it didn’t quite work in Firefox.
Here’s a minute long video demo I just shot of it running on my phone:
The API itself is available to try out right now. I managed to get the multimodal-live-api-web-console demo app working by doing this:
- Clone the repo:
git clone https://github.com/google-gemini/multimodal-live-api-web-console - Install the NPM dependencies:
cd multimodal-live-api-web-console && npm install - Edit the
.envfile to add my Gemini API key - Run the app with
npm start
It’s pretty similar to the previous live demo, but has additional tools—so you can tell it to render a chart or run Python code and it will show you the output.
This stuff is straight out of science fiction: being able to have an audio conversation with a capable LLM about things that it can “see” through your camera is one of those “we live in the future” moments.
Worth noting that OpenAI released their own WebSocket streaming API at DevDay a few months ago, but that one only handles audio and is currently very expensive to use. Google haven’t announced the pricing for Gemini 2.0 Flash yet (it’s a free preview) but if the Gemini 1.5 series is anything to go by it’s likely to be shockingly inexpensive.
Things to look forward to
I usually don’t get too excited about not-yet-released features, but this thing from the Native image output video caught my eye:

The dream of multi-modal image output is that models can do much more finely grained image editing than has been possible using previous generations of diffusion-based image models. OpenAI and Amazon have both promised models with these capabilities in the near-future, so it looks like we’re going to have a lot of fun with this stuff in 2025.
The Building with Gemini 2.0: Native audio output demo video shows off how good Gemini 2.0 Flash will be at audio output with different voices, intonations, languages and accents. This looks similar to what’s possible with OpenAI’s advanced voice mode today.
More recent articles
- The Axios supply chain attack used individually targeted social engineering - 3rd April 2026
- Highlights from my conversation about agentic engineering on Lenny's Podcast - 2nd April 2026
- Mr. Chatterbox is a (weak) Victorian-era ethically trained model you can run on your own computer - 30th March 2026