Leaked Google document: “We Have No Moat, And Neither Does OpenAI”
4th May 2023
SemiAnalysis published something of a bombshell leaked document this morning: Google “We Have No Moat, And Neither Does OpenAI”.
The source of the document is vague:
The text below is a very recent leaked document, which was shared by an anonymous individual on a public Discord server who has granted permission for its republication. It originates from a researcher within Google.
Having read through it, it looks real to me—and even if it isn’t, I think the analysis within stands alone. It’s the most interesting piece of writing I’ve seen about LLMs in a while.
It’s absolutely worth reading the whole thing—it’s full of quotable lines—but I’ll highlight some of the most interesting parts here.
The premise of the paper is that while OpenAI and Google continue to race to build the most powerful language models, their efforts are rapidly being eclipsed by the work happening in the open source community.
While our models still hold a slight edge in terms of quality, the gap is closing astonishingly quickly. Open-source models are faster, more customizable, more private, and pound-for-pound more capable. They are doing things with $100 and 13B params that we struggle with at $10M and 540B. And they are doing so in weeks, not months.
This chart is adapted from one in the Vicuna 13-B announcement—the author added the “2 weeks apart” and “1 week apart” labels illustrating how quickly LLaMA Vicuna and Alpaca followed LLaMA.
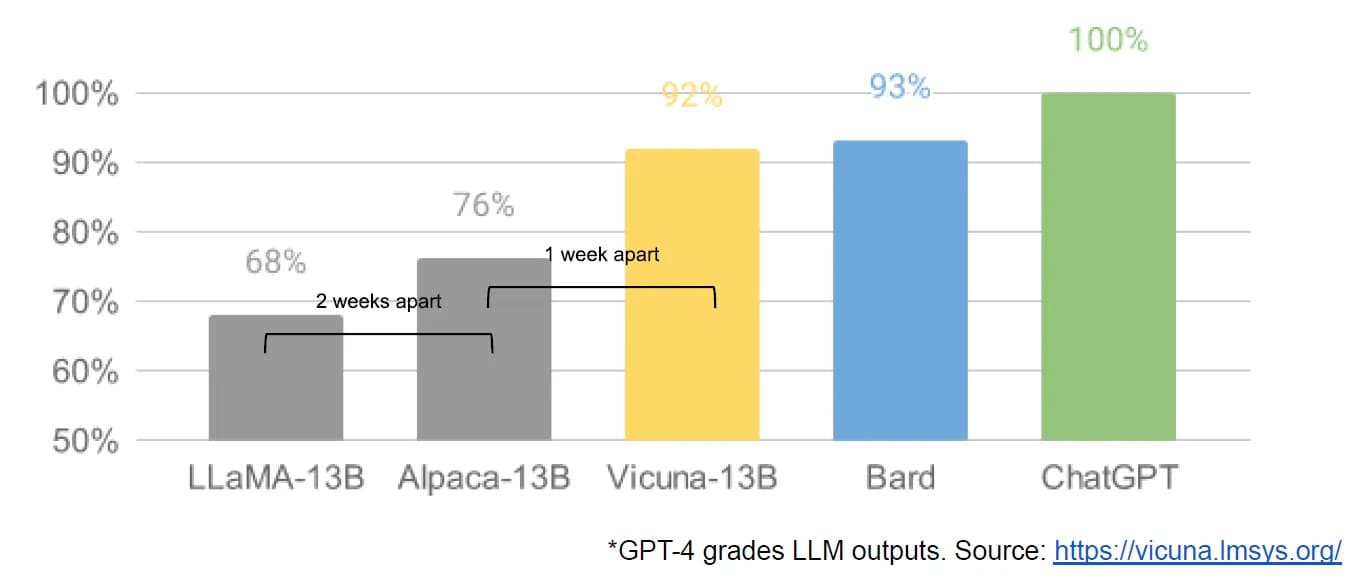
They go on to explain quite how much innovation happened in the open source community following the release of Meta’s LLaMA model in March:
A tremendous outpouring of innovation followed, with just days between major developments (see The Timeline for the full breakdown). Here we are, barely a month later, and there are variants with instruction tuning, quantization, quality improvements, human evals, multimodality, RLHF, etc. etc. many of which build on each other.
Most importantly, they have solved the scaling problem to the extent that anyone can tinker. Many of the new ideas are from ordinary people. The barrier to entry for training and experimentation has dropped from the total output of a major research organization to one person, an evening, and a beefy laptop.
Why We Could Have Seen It Coming
In many ways, this shouldn’t be a surprise to anyone. The current renaissance in open source LLMs comes hot on the heels of a renaissance in image generation. The similarities are not lost on the community, with many calling this the "Stable Diffusion moment" for LLMs.
I’m pretty chuffed to see a link to my blog post about the Stable Diffusion moment in there!
Where things get really interesting is where they talk about “What We Missed”. The author is extremely bullish on LoRA—a technique that allows models to be fine-tuned in just a few hours of consumer hardware, producing improvements that can then be stacked on top of each other:
Part of what makes LoRA so effective is that—like other forms of fine-tuning—it’s stackable. Improvements like instruction tuning can be applied and then leveraged as other contributors add on dialogue, or reasoning, or tool use. While the individual fine tunings are low rank, their sum need not be, allowing full-rank updates to the model to accumulate over time.
This means that as new and better datasets and tasks become available, the model can be cheaply kept up to date, without ever having to pay the cost of a full run.
Training models from scratch again is hugely more expensive, and invalidates previous LoRA fine-tuning work. So having the ability to train large models from scratch on expensive hardware is much less of a competitive advantage than previously thought:
Large models aren’t more capable in the long run if we can iterate faster on small models
LoRA updates are very cheap to produce (~$100) for the most popular model sizes. This means that almost anyone with an idea can generate one and distribute it. Training times under a day are the norm. At that pace, it doesn’t take long before the cumulative effect of all of these fine-tunings overcomes starting off at a size disadvantage. Indeed, in terms of engineer-hours, the pace of improvement from these models vastly outstrips what we can do with our largest variants, and the best are already largely indistinguishable from ChatGPT. Focusing on maintaining some of the largest models on the planet actually puts us at a disadvantage.
(Seriously, this entire paper is full of quotable sections like this.)
The paper concludes with some fascinating thoughts on strategy. Google have already found it difficult to keep their advantages protected from competitors such as OpenAI, and now that the wider research community are collaborating in the open they’re going to find it even harder:
Keeping our technology secret was always a tenuous proposition. Google researchers are leaving for other companies on a regular cadence, so we can assume they know everything we know, and will continue to for as long as that pipeline is open.
But holding on to a competitive advantage in technology becomes even harder now that cutting edge research in LLMs is affordable. Research institutions all over the world are building on each other’s work, exploring the solution space in a breadth-first way that far outstrips our own capacity. We can try to hold tightly to our secrets while outside innovation dilutes their value, or we can try to learn from each other.
As for OpenAI themselves?
And in the end, OpenAI doesn’t matter. They are making the same mistakes we are in their posture relative to open source, and their ability to maintain an edge is necessarily in question. Open source alternatives can and will eventually eclipse them unless they change their stance. In this respect, at least, we can make the first move.
There’s a whole lot more in there—it’s a fascinating read, very information dense and packed with extra insight. I strongly suggest working through the whole thing.