Enriching data with GPT3.5 and SQLite SQL functions
29th April 2023
I shipped openai-to-sqlite 0.3 yesterday with a fun new feature: you can now use the command-line tool to enrich data in a SQLite database by running values through an OpenAI model and saving the results, all in a single SQL query.
The idea for this came out of a conversation in a Datasette Office Hours session. I was asked if there was a way to do sentiment analysis using Datasette. There isn’t, yet—and the feature I’ve been planning that would enable that (which I’m calling “enrichments”) is still a fair way out.
But it got me to thinking... what’s the simplest possible way to run sentiment analysis on a column of data in a SQLite database using the tools I’ve already built?
I ended up adding a small new feature to my openai-to-sqlite tool: the ability to call the OpenAI API (currently just the ChatGPT / gpt-3.5-turbo model) with a SQL query, plus a new chatgpt(prompt) SQL function for executing prompts.
This means you can do sentiment analysis something like this:
openai-to-sqlite query database.db "
update messages set sentiment = chatgpt(
'Sentiment analysis for this message: ' || message ||
' - ONLY return a lowercase string from: positive, negative, neutral, unknown'
)
where sentiment not in ('positive', 'negative', 'neutral', 'unknown')
or sentiment is null
"Running this command causes the sentiment column on the messages table to be populated with one of the following values: positive, negative, neutral or unknown.
It also prints out a cost estimate at the end. To run against 400 rows of data (each the length of a group chat message, so pretty short) cost me 20,000 tokens, which was about 4 cents. gpt-3.5-turbo is cheap.
The command uses an OpenAI API key from the OPENAI_API_KEY environment variable, or you can pass it in using the --token option to the command.
The tool also displays a progress bar while it’s running, which looks like this:

Sentiment analysis with ChatGPT
Here’s the SQL query that I ran, with extra inline comments:
update messages
-- we're updating rows in the messages table
set sentiment = chatgpt(
-- Construct the ChatGPT prompt
'Sentiment analysis for this message: ' ||
message ||
' - ONLY return a lowercase string from:' ||
'positive, negative, neutral, unknown'
)
where
-- Don't update rows that already have a sentiment
sentiment not in (
'positive', 'negative', 'neutral', 'unknown'
) or sentiment is nullAnd here’s the prompt I’m using:
Sentiment analysis for this message: {message}—ONLY return a lowercase string from: positive, negative, neutral, unknown
As usual with prompt engineering, you end up having to practically BEG the model to stick to the rules. My first version of this prompt produced all kinds of unexpected output—this version mostly does what I want, but still ends up spitting out the occasional Positive. or Sentiment: Negative result despite my pleas for just those four strings.
I’m sure there are better prompts for this. I’d love to see what they are!
(The most likely improvement would be to include some examples in the prompt, to help nail down the expected outputs—an example of few-shot training.)
Running prompts with a SELECT
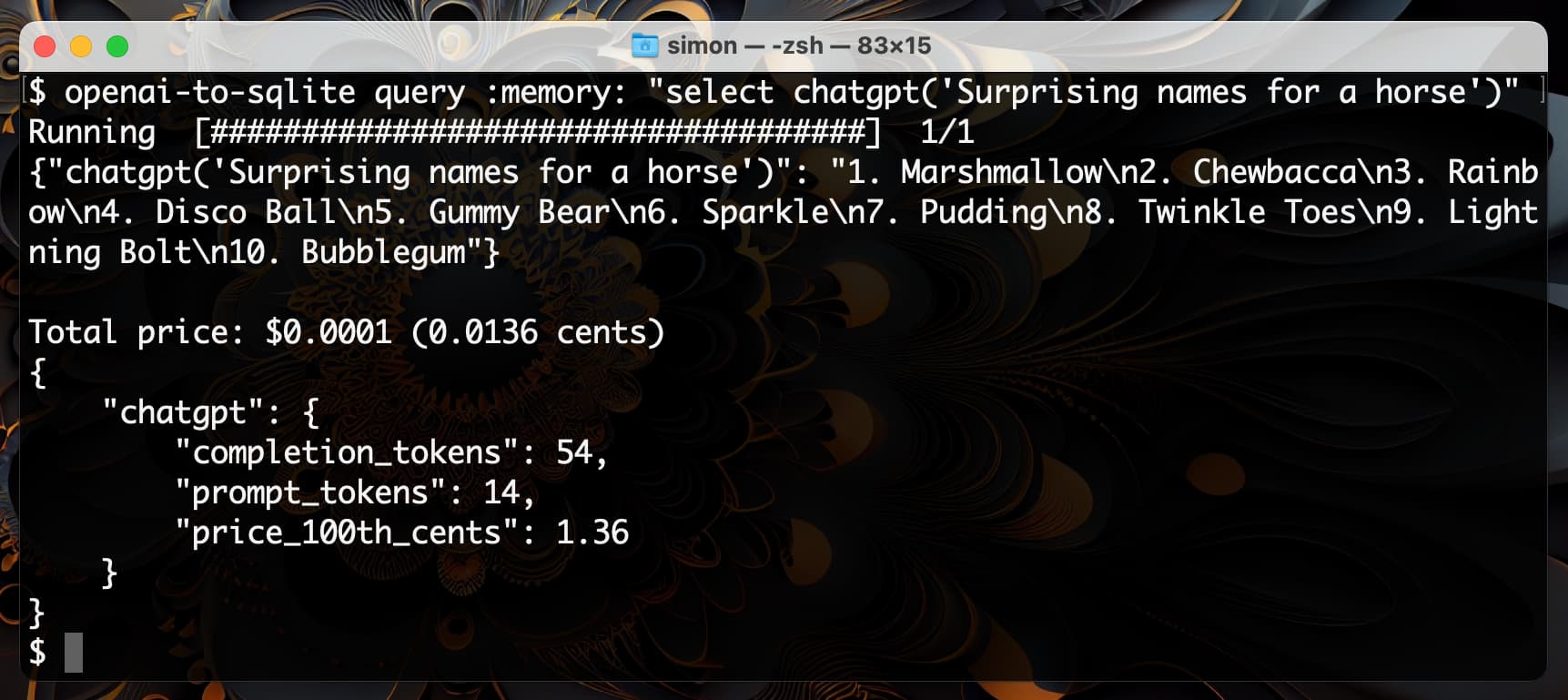
I have other tools for running prompts from the command-line, but if you want to use this to execute a prompt directly without writing to a database you can execute against the :memory: SQLite in-memory database like this:
openai-to-sqlite query :memory: \
"select chatgpt('Surprising names for a horse')"
How the progress bar works
When I first implemented this, it didn’t have a progress bar.
This turned out to be a pretty big problem!
A SQL update that affects 400 rows, each one involving an API call to OpenAI, can take a few minutes to run.
During that time, there is no feedback at all to show you that it’s working, or indicate how far it’s gone.
The UPDATE statement itself runs inside a transaction, so you can’t even peak in the database to see how it’s going—all 400 rows will appear once, at the end of the query.
I really wanted a progress bar. But how could I implement that? I need it to update as the query progresses, and I also need to know how many API calls it’s going to make in advance in order to correctly display it.
I figured out a neat way of doing this.
The trick is to run the SQL query twice. The first time, implement a dummy chatgpt() function that counts how many times it has been called but doesn’t make an API call.
Then, at the end of that query... rollback the transaction! This means that the dummy chatgpt() function will have been called the correct number of times, but the database will be left unchanged.
Now register the “real” chatgpt() function and run the query a second time.
That second chatgpt() Python function can increment the counter used by the progress bar each time it’s called.
The result is a progress bar that knows how many API calls are going to be made and updates as the query progresses.
Here’s the code that makes that happen.
Is this a good way of doing things?
Even though I managed to get the progress bar working, there are still some big limitations in using a SQL query to do this.
The first is that any query which triggers external API calls via a custom SQL function is inherently time-consuming. This means running a really long transaction, and since SQLite only accepts a single write at a time this means locking the database for writes for a very long time.
That’s OK for a command-line script like this when you’re the only user of the database, but it’s not a good idea for databases that are serving other queries—as I frequently do with SQLite and Datasette.
A much bigger problem though is what happens when something goes wrong. An update ... set col1 = chatgpt(...) query executes in a single transaction. If you’re running it against 400 rows and something causes an error at row 399, the transaction will rollback and you’ll lose all of the work that DID succeed!
As such, while this is a fun tool for ad-hoc experiments with OpenAI data enrichment, I don’t think it’s a good long-term solution. A better mechanism would enable each individual API call to be written to storage such that problems in later calls don’t discard data collected earlier on.
More recent articles
- Meta's new model is Muse Spark, and meta.ai chat has some interesting tools - 8th April 2026
- Anthropic's Project Glasswing - restricting Claude Mythos to security researchers - sounds necessary to me - 7th April 2026
- The Axios supply chain attack used individually targeted social engineering - 3rd April 2026