The Baked Data architectural pattern
28th July 2021
I’ve been exploring an architectural pattern for publishing websites over the past few years that I call the “Baked Data” pattern. It provides many of the advantages of static site generators while avoiding most of their limitations. I think it deserves to be used more widely.
I define the Baked Data architectural pattern as the following:
Baked Data: bundling a read-only copy of your data alongside the code for your application, as part of the same deployment
Most dynamic websites keep their code and data separate: the code runs on an application server, the data lives independently in some kind of external data store—something like PostgreSQL, MySQL or MongoDB.
With Baked Data, the data is deployed as part of the application bundle. Any time the content changes, a fresh copy of the site is deployed that includes those updates.
I mostly use SQLite database files for this, but plenty of other formats can work here too.
This works particularly well with so-called “serverless” deployment platforms—platforms that support stateless deployments and only charge for resources spent servicing incoming requests (“scale to zero”).
Since every change to the data results in a fresh deployment this pattern doesn’t work for sites that change often—but in my experience many content-oriented sites update their content at most a few times a day. Consider blogs, documentation sites, project websites—anything where content is edited by a small group of authors.
Benefits of Baked Data
Why would you want to apply this pattern? A few reasons:
- Inexpensive to host. Anywhere that can run application code can host a Baked Data application—there’s no need to pay extra for a managed database system. Scale to zero serverless hosts such as Cloud Run, Vercel or AWS Lambda will charge only cents per month for low-traffic deployments.
- Easy to scale. Need to handle more traffic? Run more copies of your application and its bundled data. Horizontally scaling Baked Data applications is trivial. They’re also a great fit to run behind a caching proxy CDN such as Cloudflare or Fastly—when you deploy a new version you can purge that entire cache.
- Difficult to break. Hosting server-side applications on a VPS is always disquieting because there’s so much that might go wrong—the server could be compromised, or a rogue log file could cause it to run out of disk space. With Baked Data the worst that can happen is that you need to re-deploy the application—there’s no risk at all of data loss, and providers that can auto-restart code can recover from errors automatically.
- Server-side functionality is supported. Static site generators provide many of the above benefits, but with the limitation that any dynamic functionality needs to happen in client-side JavaScript. With a Baked Data application you can execute server-side code too.
- Templated pages. Another improvement over static site generators: if you have 10,000 pages, a static site generator will need to generate 10,000 HTML files. With Baked Data those 10,000 pages can exist as rows in a single SQLite database file, and the pages can be generated at run-time using a server-side template.
- Easy to support multiple formats. Since your content is in a dynamic data store, outputting that same content in alternative formats is easy. I use Datasette plugins for this: datasette-atom can produce an Atom feed from a SQL query, and datasette-ics does the same thing for iCalendar feeds.
- Integrates well with version control. I like to keep my site content under version control. The Baked Data pattern works well with build scripts that read content from a git repository and use it to build assets that are bundled with the deployment.
How to bake your data
My initial implementations of Baked Data have all used SQLite. It’s an ideal format for this kind of application: a single binary file which can store anything that can be represented as relational tables, JSON documents or binary objects—essentially anything at all.
Any format that can be read from disk by your dynamic server-side code will work too: YAML or CSV files, Berkeley DB files, or anything else that can be represented by a bucket of read-only bytes in a file on disk.
[I have a hunch that you could even use something like PostgreSQL, MySQL or Elasticsearch by packaging up their on-disk representations and shipping them as part of a Docker container, but I’ve not tried that myself yet.]
Once your data is available in a file, your application code can read from that file and use it to generate and return web pages.
You can write code that does this in any server-side language. I use Python, usually with my Datasette application server which can read from a SQLite database file and use Jinja templates to generate pages.
The final piece of the puzzle is a build and deploy script. I use GitHub Actions for this, but any CI tool will work well here. The script builds the site content into a deployable asset, then deploys that asset along with the application code to a hosting platform.
Baked Data in action: datasette.io
The most sophisticated Baked Data site I’ve published myself is the official website for my Datasette project, datasette.io—source code in this repo.
The site is deployed using Cloud Run. It’s actually a heavily customized Datasette instance, using a custom template for the homepage, custom pages for other parts of the site and the datasette-template-sql plugin to execute SQL queries and display their results from those templates.
The site currently runs off four database files:
-
content.db has most of the site content. It is built inside GitHub Actions by the build.sh script, which does the following:
- Import the contents of the news.yaml file into a news table using yaml-to-sqlite.
- Import the markdown files from the for/ folder (use-cases for Datasette) into the uses table using markdown-to-sqlite.
- Populate the plugin_repos and tool_repos single-column tables using data from more YAML files. These are used in the next step.
- Runs the build_directory.py Python script. This uses the GitHub GraphQL API to fetch information about all of those plugin and tool repositories, including their README files and their most recent tagged releases.
- Populates a stats table with the latest download statistics for all of the Datasette ecosystem PyPI packages. That data is imported from a
stats.jsonfile in my simonw/package-stats repository, which is itself populated by this git scraping script that runs in GitHub Actions. I also use this for my Datasette Downloads Observable notebook.
-
blog.db contains content from my blog that carries any of the datasette, dogsheep or sqliteutils tags.
- This is fetched by the fetch_blog_content.py script, which hits the paginated per-tag Atom feed for my blog content, implemented in Django here.
-
docs-index.db is a database table containing the documentation for the most recent stable Datasette release, broken up by sections.
- This database file is downloaded from a separate site, stable-docs.datasette.io, which is built and deployed as part of Datasette’s release process.
-
dogsheep-index.db is the search index that powers site search (e.g. this search for dogsheep).
- The search index is built by dogsheep-beta using data pulled from tables in the other database files, as configured by this YAML file.
The site is automatically deployed once a day by a scheduled action, and I can also manually trigger that action if I want to ensure a new software release is reflected on the homepage.
Other real-world examples of Baked Data
I’m currently running two other sites using this pattern:
- Niche Museums is my blog about tiny museums that I’ve visited. Again, it’s Datasette with custom templates. Most of the content comes from this museums.yaml file, but I also run a script to figure out when each item was created or updated from the git history.
- My TILs site runs on Vercel and is built from my simonw/til GitHub repository by this build script (populating this tils table). It uses the GitHub API to convert GitHub Flavored Markdown to HTML. I’m also running a script that generates small screenshots of each page and stashes them in a BLOB column in SQLite in order to provide social media preview cards, see Social media cards for my TILs.
My favourite example of this pattern in a site that I haven’t worked on myself is Mozilla.org.
They started using SQLite back in 2018 in a system they call Bedrock—Paul McLanahan provides a detailed description of how this works.
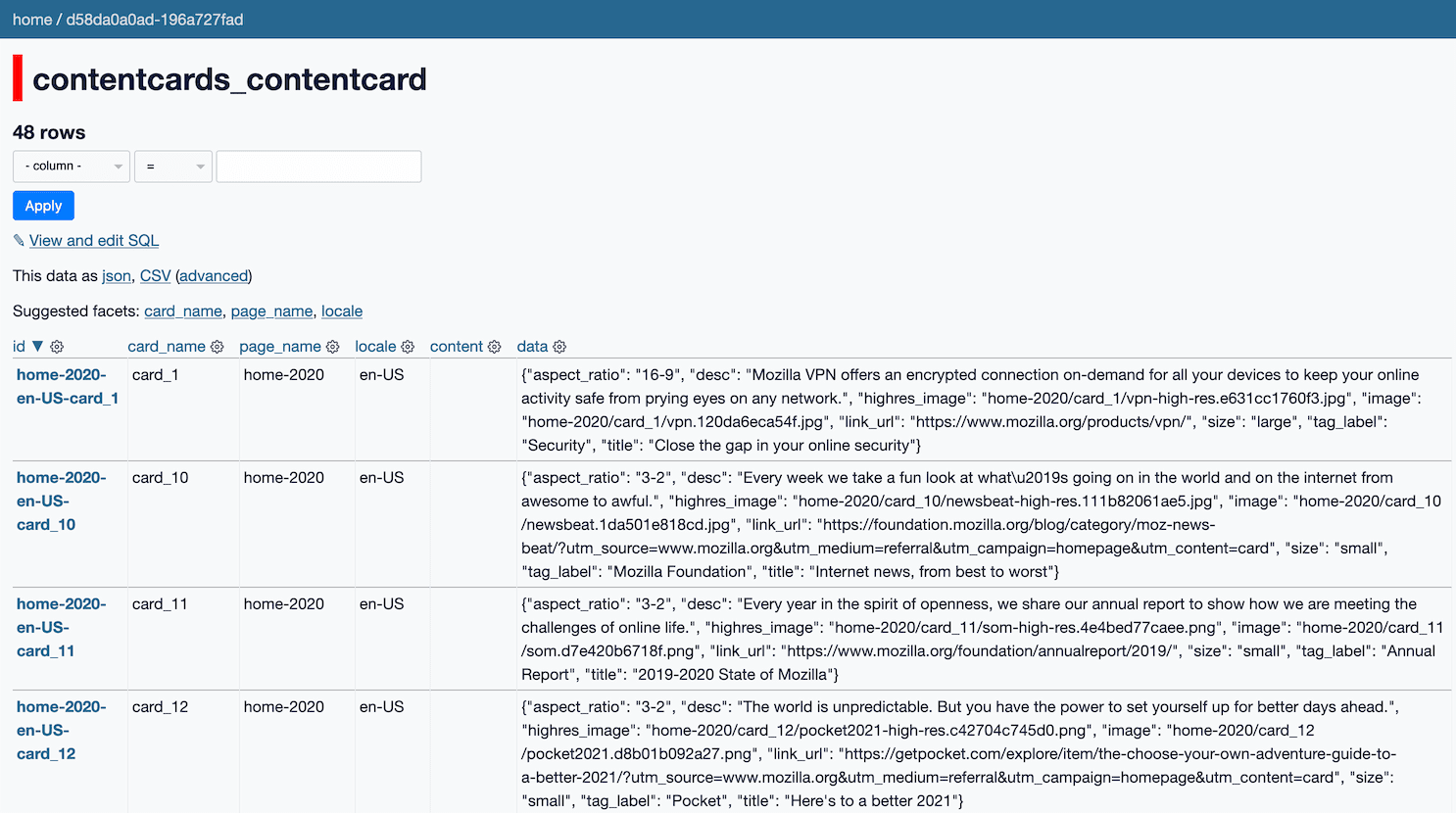
Their site content lives in a ~22MB SQLite database file, which is built and uploaded to S3 and then downloaded on a regular basis to each of their application servers.
You can view their healthcheck page to see when the database was last downloaded, and grab a copy of the SQLite file yourself. It’s fun to explore that using Datasette:
Compared to static site generators
Static site generators have exploded in popularity over the past ten years. They drive the cost of hosting a site down to almost nothing, provide excellent performance, work well with CDNs and produce sites that are extremely unlikely to break.
Used carefully, the Baked Data keeps most of these characteristics while still enabling server-side code execution.
My example sites use this in a few different ways:
- datasette.io provides search across 1,588 different pieces of content, plus simpler search on the plugins and tools pages.
- My TIL site also provides search, as does Niche Museums.
- All three sites provide Atom feeds that are configured using a server-side SQL query: Datasette, Niche Museums, TILs.
- Niche Museums offers a “Use my location” button which then serves museums near you, using a SQL query that makes use of the datasette-haversine plugin.
A common complaint about static site generators when used for larger sites is that build times can get pretty long if the builder has to generate tens of thousands of pages.
With Baked Data, 10,000 pages can be generated by a single template file and 10,000 rows in a SQLite database table.
This also makes for a faster iteration cycle during development: you can edit a template and hit “refresh” to see any page rendered by the new template instantly, without needing to rebuild any pages.
Want to give this a go?
If you want to give the Baked Data pattern a try, I recommend starting out using the combination of Datasette, GitHub Actions and Vercel. Hopefully the examples I’ve provided above are a good starting point—also feel free to reach out to me on Twitter or in the Datasette Discussions forum with any questions.