Weeknotes: Getting my personal Dogsheep up and running again
22nd August 2021
I gave a talk about Dogsheep at Noisebridge’s Five Minutes of Fame on Thursday. Just one problem: my regular Dogsheep demo was broken, so I ended up building it from scratch again. In doing so I fixed a few bugs in some Dogsheep tools.
Dogsheep on a Digital Ocean droplet
The latest iteration of my personal Dogsheep runs on a $20/month 4GB/2CPU Digital Ocean Droplet running Ubuntu 20.04 LTS.
It runs a private Datasette instance and a bunch of cron jobs to fetch data from Twitter, GitHub, Foursquare Swarm, Pocket and Hacker News.
It also has copies of my Apple Photos and Apple HealthKit data which I upload manually—plus a copy of my genome for good measure.
Some abbreviated notes on how I set it up, copied from a private GitHub Issues thread:
-
Create a new Ubuntu droplet, and configure its IP address as the A record for
dogsheep.simonwillison.net -
Install Python 3 and NGINX and SQLite:
apt-get install python3 python3-venv nginx sqlite -y -
Use letsencrypt to get an HTTPS certificate for it:
apt-get updateand thenapt install certbot python3-certbot-nginx -y, thencertbot --nginx -d dogsheep.simonwillison.net -
I had to remove the
ipv6only=on;bit from the NGINX configuration due to this bug -
Created a
dogsheepuser,useradd -s /bin/bash -d /home/dogsheep/ -m -G -
As that user, created a virtual environment:
python3 -mvenv datasette-venvand thendatasette-venv/bin/pip install wheelanddatasette-venv/bin/pip install datasette datasette-auth-passwords -
Created a
/etc/systemd/system/datasette.servicefile with this contents -
Created a set of blank SQLite database files in WAL mode in
/home/dogsheepusing the following:for f in beta.db twitter.db healthkit.db github.db \ swarm.db photos.db genome.db simonwillisonblog.db \ pocket.db hacker-news.db memories.db do sqlite3 $f vacuum # And enable WAL mode: sqlite3 $f 'PRAGMA journal_mode=WAL;' done -
Started the Datasette service:
service datasette start -
Configured NGINX to proxy to localhost port 8001, using this configuration
It’s a few more steps than I’d like, but the end result was a password-protected Datasette instance running against a bunch of SQLite database files on my new server.
With Datasette up and running, the next step was to start loading in data.
Importing my tweets
I started with Twitter. I dropped my Twitter API access credentials into an auth.json file (as described here) and ran the following:
source /home/dogsheep/datasette-venv/bin/activate
pip install twitter-to-sqlite
twitter-to-sqlite user-timeline /home/dogsheep/twitter.db \
-a /home/dogsheep/auth.json
@simonw [###############################-----] 26299/29684 00:02:06
That pulled in all 29,684 of my personal tweets.
(Actually, first it broke with an error, exposing a bug that had already been reported. I shipped a fix for that and tried again and it worked.)
Favourited tweets were a little harder—I have 39,904 favourited tweets, but the Twitter API only returns the most recent 3,200. I grabbed those more recent ones with:
twitter-to-sqlite favorites /home/dogsheep/twitter.db \
-a /home/dogsheep/auth.json
Then I requested my Twitter archive, waited 24 hours and uploaded the resulting like.js file to the server, then ran:
twitter-to-sqlite import twitter.db /tmp/like.js
This gave me an archive_like table with the data from that file—but it wasn’t the full tweet representation, just the subset that Twitter expose in the archive export.
The README shows how to inflate those into full tweets:
twitter-to-sqlite statuses-lookup twitter.db \
--sql='select tweetId from archive_like' \
--skip-existing
Importing 33,382 tweets [------------------------------------] 0% 00:18:28
Once that was done I wrote additional records into the favorited_by table like so:
sqlite3 twitter.db '
INSERT OR IGNORE INTO favorited_by (tweet, user)
SELECT tweetId, 12497 FROM archive_like
'
(12497 is my Twitter user ID.)
I also came up with a SQL view that lets me see just media attached to tweets:
sqlite-utils create-view twitter.db media_details "
select
json_object('img_src', media_url_https, 'width', 400) as img,
tweets.full_text,
tweets.created_at,
tweets.id as tweet_id,
users.screen_name,
'https://twitter.com/' || users.screen_name || '/status/' || tweets.id as tweet_url
from
media
join media_tweets on media.id = media_tweets.media_id
join tweets on media_tweets.tweets_id = tweets.id
join users on tweets.user = users.id
order by
tweets.id desc
"
Now I can visit /twitter/media_details?_where=tweet_id+in+(select+tweet+from+favorited_by+where+user+=+12497) to see the most recent media tweets that I’ve favourited!
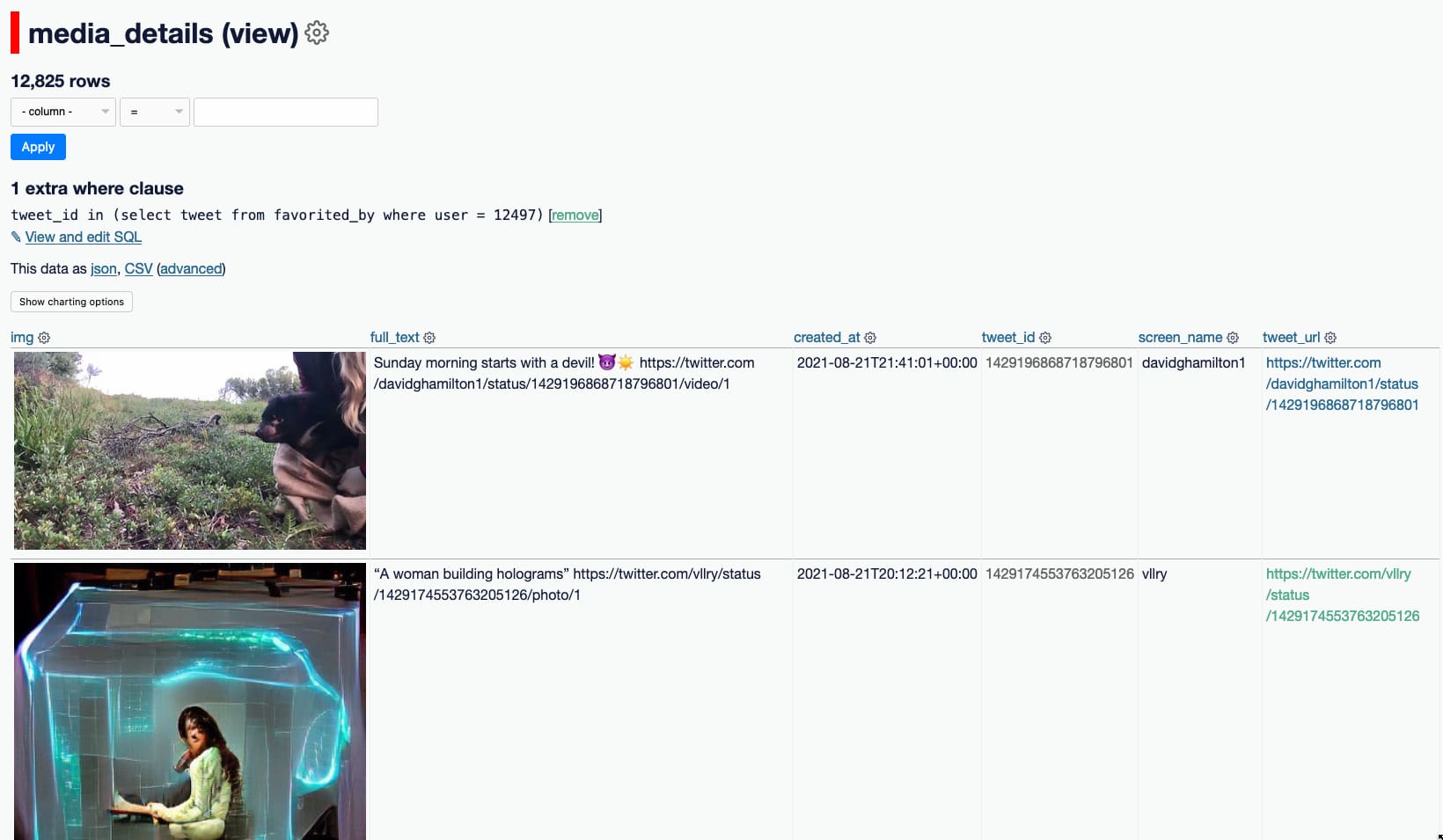
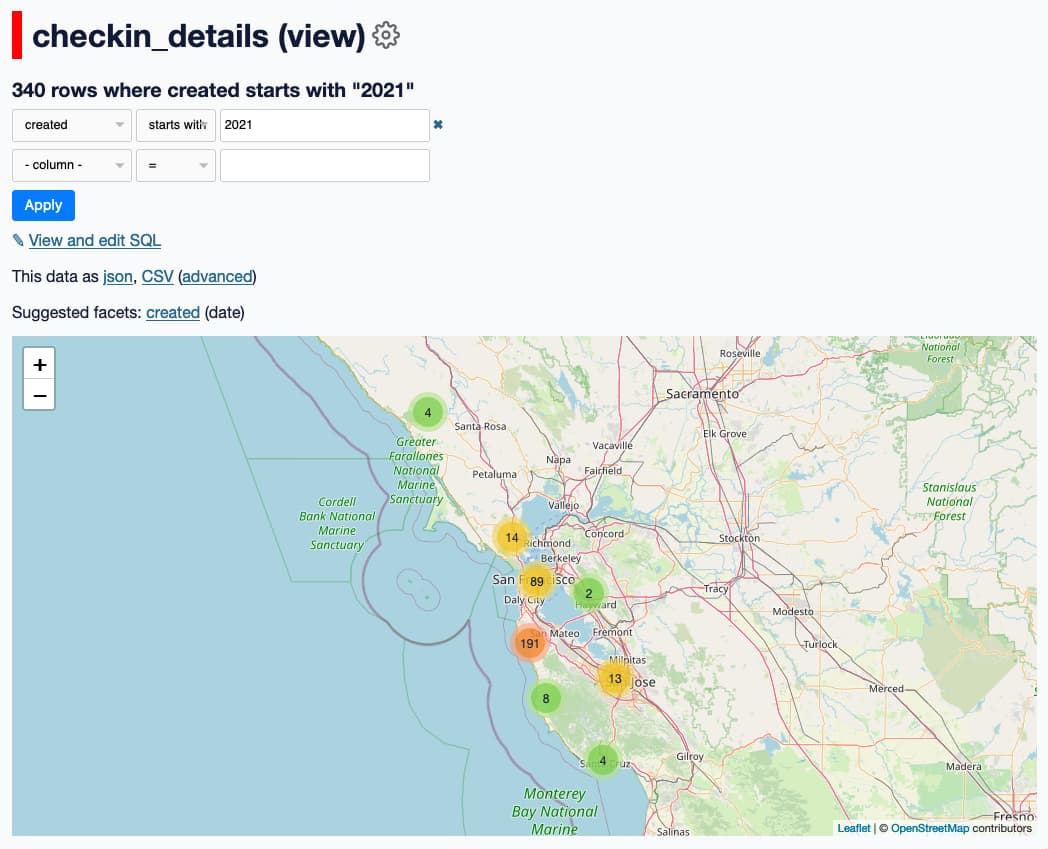
Swarm checkins
Swarm checkins were a lot easier. I needed my previously-created Foursquare API token, and swarm-to-sqlite:
pip install swarm-to-sqlite
swarm-to-sqlite /home/dogsheep/swarm.db --token=...
This gave me a full table of my Swarm checkins, which I can visualize using datasette-cluster-map:
Apple HealthKit
I don’t yet have full automation for my Apple HealthKit data (collected by my Apple Watch) or my Apple Photos—both require me to run scripts on my laptop to create the SQLite database file and then copy the result to the server via scp.
healthkit-to-sqlite runs against the export.zip that is produced by the Apple Health app on the iPhone’s export data button—for me that was a 158MB zip file which I AirDropped to my laptop and converted (after fixing a new bug) like so:
healthkit-to-sqlite ~/Downloads/export.zip healthkit.db
Importing from HealthKit [-----------------------------] 2% 00:02:25
I uploaded the resulting 1.5GB healthkit.db file and now I can do things like visualize my 2017 San Francisco Half Marathon run on a map:
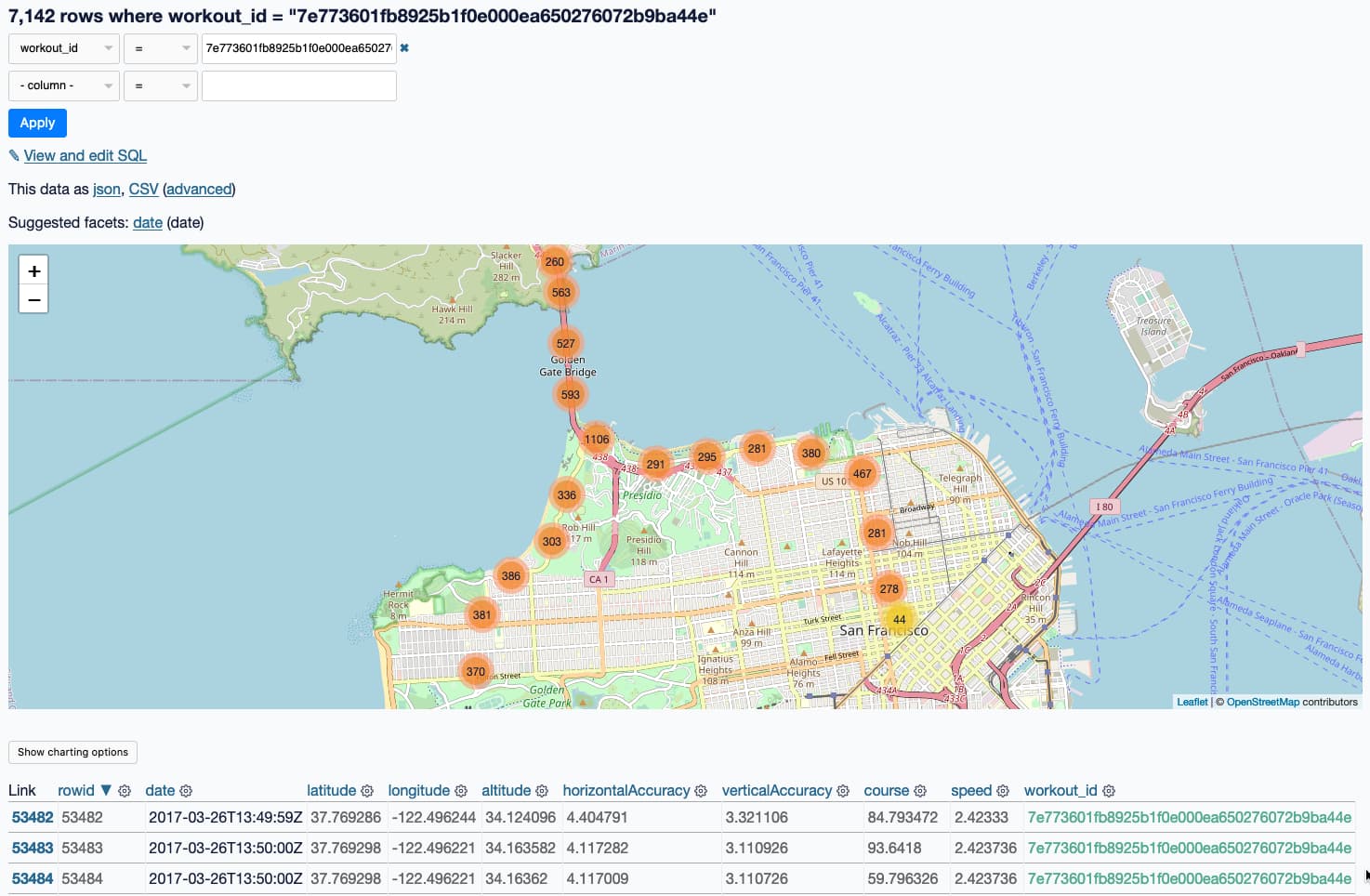
Apple Photos
For my photos I use dogsheep-photos, which I described last year in Using SQL to find my best photo of a pelican according to Apple Photos. The short version: I run this script on my laptop:
# Upload original photos to my S3 bucket
dogsheep-photos upload photos.db \
~/Pictures/Photos\ Library.photoslibrary/originals
dogsheep-photos apple-photos photos.db \
--image-url-prefix "https://photos.simonwillison.net/i/" \
--image-url-suffix "?w=600"
scp photos.db dogsheep:/home/dogsheep/photos.db
photos.db is only 171MB—it contains the metadata, including the machine learning labels, but not the photos themselves.
And now I can run queries for things like photos of food I’ve taken in 2021:
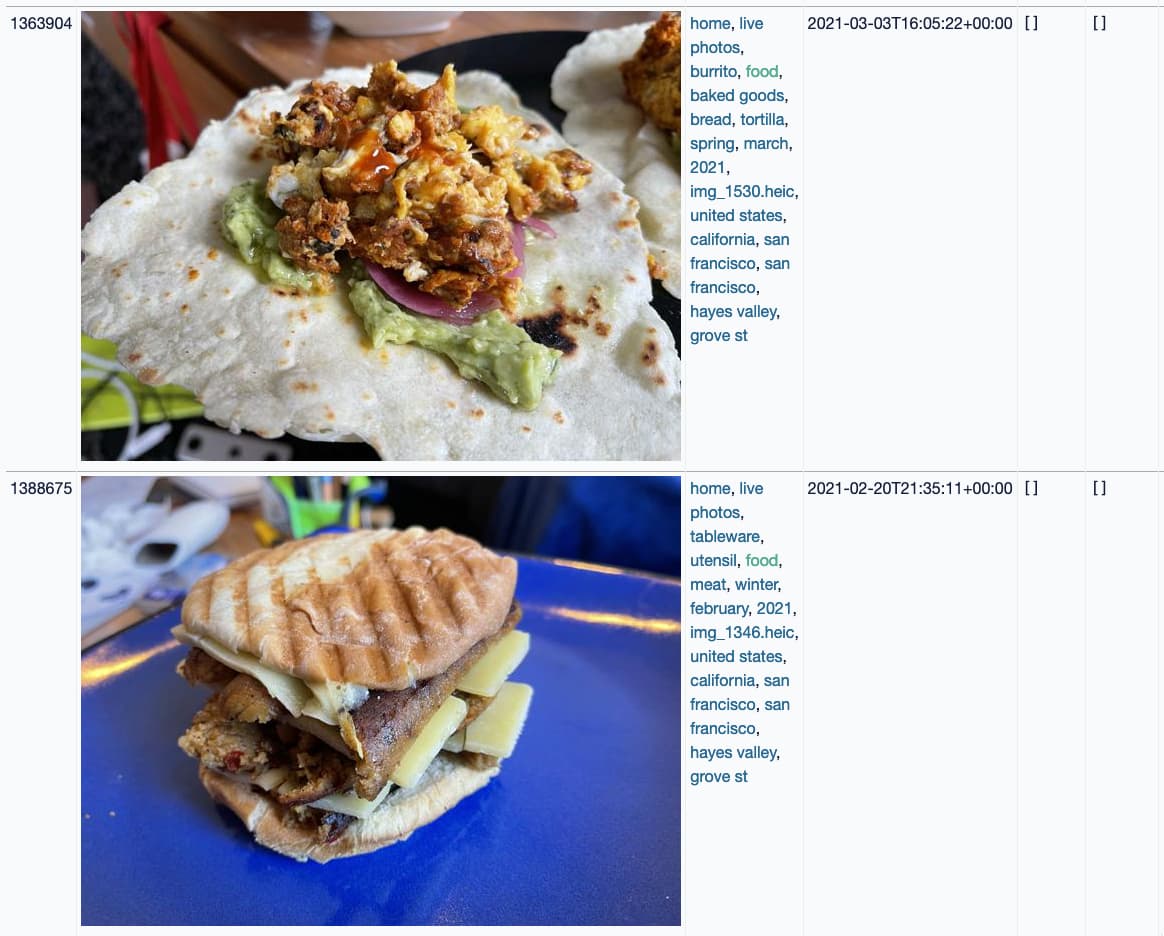
Automation via cron
I’m still working through the last step, which involves setting up cron tasks to refresh my data periodically from various sources. My crontab currently looks like this:
# Twitter
1,11,21,31,41,51 * * * * /home/dogsheep/datasette-venv/bin/twitter-to-sqlite user-timeline /home/dogsheep/twitter.db -a /home/dogsheep/auth.json --since
4,14,24,34,44,54 * * * * run-one /home/dogsheep/datasette-venv/bin/twitter-to-sqlite mentions-timeline /home/dogsheep/twitter.db -a /home/dogsheep/auth.json --since
11 * * * * run-one /home/dogsheep/datasette-venv/bin/twitter-to-sqlite user-timeline /home/dogsheep/twitter.db cleopaws -a /home/dogsheep/auth.json --since
6,16,26,36,46,56 * * * * run-one /home/dogsheep/datasette-venv/bin/twitter-to-sqlite favorites /home/dogsheep/twitter.db -a /home/dogsheep/auth.json --stop_after=50
# Swarm
25 */2 * * * /home/dogsheep/datasette-venv/bin/swarm-to-sqlite /home/dogsheep/swarm.db --token=... --since=2w
# Hacker News data every six hours
35 0,6,12,18 * * * /home/dogsheep/datasette-venv/bin/hacker-news-to-sqlite user /home/dogsheep/hacker-news.db simonw
# Re-build dogsheep-beta search index once an hour
32 * * * * /home/dogsheep/datasette-venv/bin/dogsheep-beta index /home/dogsheep/beta.db /home/dogsheep/dogsheep-beta.yml
I’ll be expanding this out as I configure more of the Dogsheep tools for my personal instance.
TIL this week
- Building a specific version of SQLite with pysqlite on macOS/Linux
- Track timestamped changes to a SQLite table using triggers
- Histogram with tooltips in Observable Plot
Releases this week
-
healthkit-to-sqlite: 1.0.1—(9 releases total)—2021-08-20
Convert an Apple Healthkit export zip to a SQLite database -
twitter-to-sqlite: 0.21.4—(27 releases total)—2021-08-20
Save data from Twitter to a SQLite database -
datasette-block-robots: 1.0—(5 releases total)—2021-08-19
Datasette plugin that blocks robots and crawlers using robots.txt -
sqlite-utils: 3.16—(85 releases total)—2021-08-18
Python CLI utility and library for manipulating SQLite databases -
datasette-debug-asgi: 1.1—(3 releases total)—2021-08-17
Datasette plugin for dumping out the ASGI scope
More recent articles
- Experimenting with Starlette 1.0 with Claude skills - 22nd March 2026
- Profiling Hacker News users based on their comments - 21st March 2026
- Thoughts on OpenAI acquiring Astral and uv/ruff/ty - 19th March 2026