20th May 2025 - Link Blog
Gemini 2.5: Our most intelligent models are getting even better. A bunch of new Gemini 2.5 announcements at Google I/O today.
2.5 Flash and 2.5 Pro are both getting audio output (previously previewed in Gemini 2.0) and 2.5 Pro is getting an enhanced reasoning mode called "Deep Think" - not yet available via the API.
Available today is the latest Gemini 2.5 Flash model, gemini-2.5-flash-preview-05-20. I added support to that in llm-gemini 0.20 (and, if you're using the LLM tool-use alpha, llm-gemini 0.20a2).
I tried it out on my personal benchmark, as seen in the Google I/O keynote!
llm -m gemini-2.5-flash-preview-05-20 'Generate an SVG of a pelican riding a bicycle'
Here's what I got from the default model, with its thinking mode enabled:
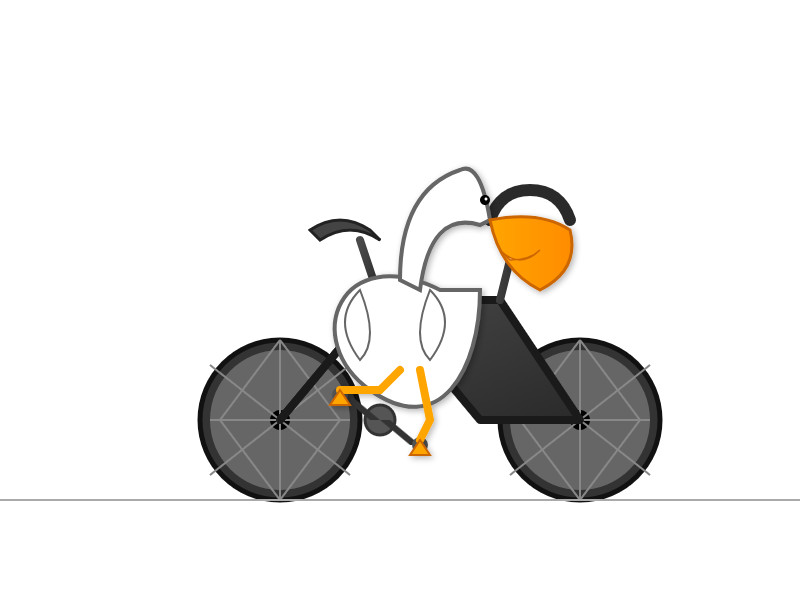
Full transcript. 11 input tokens, 2,619 output tokens, 10,391 thinking tokens = 4.5537 cents.
I ran the same thing again with -o thinking_budget 0 to turn off thinking mode entirely, and got this:

Full transcript. 11 input, 1,243 output = 0.0747 cents.
The non-thinking model is priced differently - still $0.15/million for input but $0.60/million for output as opposed to $3.50/million for thinking+output. The pelican it drew was 61x cheaper!
Finally, inspired by the keynote I ran this follow-up prompt to animate the more expensive pelican:
llm --cid 01jvqjqz9aha979yemcp7a4885 'Now animate it'
This one is pretty great!

Recent articles
- Mr. Chatterbox is a (weak) Victorian-era ethically trained model you can run on your own computer - 30th March 2026
- Vibe coding SwiftUI apps is a lot of fun - 27th March 2026
- Experimenting with Starlette 1.0 with Claude skills - 22nd March 2026