Gemini 2.5: Updates to our family of thinking models. After many months of previews, Gemini 2.5 Pro and Flash have reached general availability with new, memorable model IDs: gemini-2.5-pro and gemini-2.5-flash. They are joined by a new preview model with an unmemorable name: gemini-2.5-flash-lite-preview-06-17 is a new Gemini 2.5 Flash Lite model that offers lower prices and much faster inference times. I've added support for the new models in llm-gemini 0.23.
There's also a new Gemini 2.5 Technical Report (PDF). A few snippets of note from that paper:
While Gemini 1.5 was focused on native audio understanding tasks such as transcription, translation, summarization and question-answering, in addition to understanding, Gemini 2.5 was trained to perform audio generation tasks such as text-to-speech or native audio-visual to audio out dialog. [...]
Our Gemini 2.5 Preview TTS Pro and Flash models support more than 80 languages with the speech style controlled by a free formatted prompt which can specify style, emotion, pace, etc, while also being capable of following finer-grained steering instructions specified in the transcript. Notably, Gemini 2.5 Preview TTS can generate speech with multiple speakers, which enables the creation of podcasts as used in NotebookLM Audio Overviews. [...]
We have also trained our models so that they perform competitively with 66 instead of 258 visual tokens per frame, enabling using about 3 hours of video instead of 1h within a 1M tokens context window. [...]
An example showcasing these improved capabilities for video recall can be seen in Appendix 8.5, where Gemini 2.5 Pro is able to consistently recall a 1 sec visual event out of a full 46 minutes video.
It also includes six whole pages of analyses of the unaffiliated Gemini_Plays_Pokemon Twitch stream! Drew Breunig wrote a fun breakdown of that section of the paper.
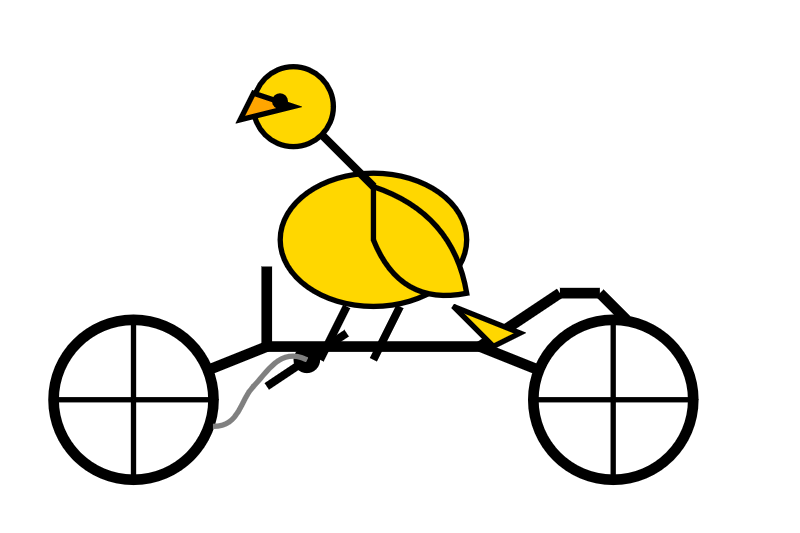
Here are some pelicans riding bicycles!
gemini-2.5-pro - 4,226 output tokens, 4.2274 cents

gemini-2.5-flash - 14,500 output tokens, 3.6253 cents
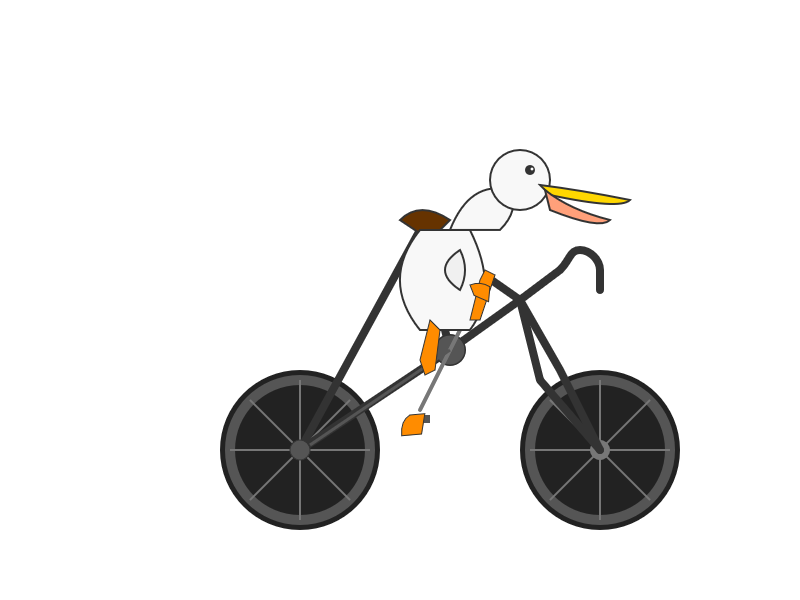
gemini-2.5-flash-lite-preview-06-17 - 2,070 output tokens, 0.0829 cents
The Gemini team hosted a Twitter Space this morning to discuss the new models, with Logan Kilpatrick, Tulsee Doshi, Melvin Johnson, Anca Dragan and Zachary Gleicher. I grabbed a copy of the audio using yt-dlp, shrunk it down a bit with ffmpeg (here's the resulting 2.5_smaller.m4a) and then tried using the new models to generate a transcript:
llm --at gemini-2.5_smaller.m4a audio/mpeg \
-m gemini/gemini-2.5-flash \
'Full transcript with timestamps' \
--schema-multi 'timestamp:mm:ss,speaker:best guess at name,text'
I got good results from 2.5 Pro and from 2.5 Flash, but the new Flash Lite model got stuck in a loop part way into the transcript:
... But this model is so cool because it just sort of goes on this rant, this hilarious rant about how the toaster is the pinnacle of the breakfast civilization, and then it makes all these jokes about the toaster. Um, like, what did the cows bring to you? Nothing. And then, um, and then, uh, and then, uh, and then, uh, and then, uh, and then, uh, and then, uh, and then, uh, and then, uh, and then, uh, and then, uh, and then, uh, and then, uh, and then, uh, and then, uh, and then, uh, and then, uh, and then, uh, and then, uh, and then, uh, and then, uh, and then, uh, and then, uh, and then, uh, and then, uh, and then, uh, and then, uh, and then, uh, and then, uh, and then, uh, and then, uh, and then, uh, and then, uh, and then, uh, and then, uh, and then, uh...(continues until it runs out of output tokens)
I had Claude 4 Sonnet vibe code me a quick tool for turning that JSON into Markdown, here's the Markdown conversion of the Gemini 2.5 Flash transcript.
A spot-check of the timestamps seems to confirm that they show up in the right place, and the speaker name guesses look mostly correct as well.
Recent articles
- Phoenix.new is Fly's entry into the prompt-driven app development space - 23rd June 2025
- Trying out the new Gemini 2.5 model family - 17th June 2025
- The lethal trifecta for AI agents: private data, untrusted content, and external communication - 16th June 2025