Trying out the new Gemini 2.5 model family
17th June 2025
After many months of previews, Gemini 2.5 Pro and Flash have reached general availability with new, memorable model IDs: gemini-2.5-pro and gemini-2.5-flash. They are joined by a new preview model with an unmemorable name: gemini-2.5-flash-lite-preview-06-17 is a new Gemini 2.5 Flash Lite model that offers lower prices and much faster inference times.
I’ve added support for the new models in llm-gemini 0.23:
llm install -U llm-gemini
llm 'Generate an SVG of a pelican riding a bicycle' \
-m gemini-2.5-flash-lite-preview-06-17
There’s also a new Gemini 2.5 Technical Report (PDF), which includes some interesting details about long context and audio and video support. Some highlights:
While Gemini 1.5 was focused on native audio understanding tasks such as transcription, translation, summarization and question-answering, in addition to understanding, Gemini 2.5 was trained to perform audio generation tasks such as text-to-speech or native audio-visual to audio out dialog. [...]
Our Gemini 2.5 Preview TTS Pro and Flash models support more than 80 languages with the speech style controlled by a free formatted prompt which can specify style, emotion, pace, etc, while also being capable of following finer-grained steering instructions specified in the transcript. Notably, Gemini 2.5 Preview TTS can generate speech with multiple speakers, which enables the creation of podcasts as used in NotebookLM Audio Overviews. [...]
We have also trained our models so that they perform competitively with 66 instead of 258 visual tokens per frame, enabling using about 3 hours of video instead of 1h within a 1M tokens context window. [...]
An example showcasing these improved capabilities for video recall can be seen in Appendix 8.5, where Gemini 2.5 Pro is able to consistently recall a 1 sec visual event out of a full 46 minutes video.
The report also includes six whole pages of analyses of the unaffiliated Gemini_Plays_Pokemon Twitch stream! Drew Breunig wrote a fun and insightful breakdown of that section of the paper with some of his own commentary:
Long contexts tripped up Gemini’s gameplay. So much about agents is information control, what gets put in the context. While benchmarks demonstrated Gemini’s unmatched ability to retrieve facts from massive contexts, leveraging long contexts to inform Pokémon decision making resulted in worse performance: “As the context grew significantly beyond 100k tokens, the agent showed a tendency toward favoring repeating actions from its vast history rather than synthesizing novel plans.” This is an important lesson and one that underscores the need to build your own evals when designing an agent, as the benchmark performances would lead you astray.
Let’s run a few experiments through the new models.
Pelicans on bicycles
Here are some SVGs of pelicans riding bicycles!
gemini-2.5-pro—4,226 output tokens, 4.2274 cents:

gemini-2.5-flash—14,500 output tokens, 3.6253 cents (it used a surprisingly large number of output tokens here, hence th cost nearly matching 2.5 Pro):
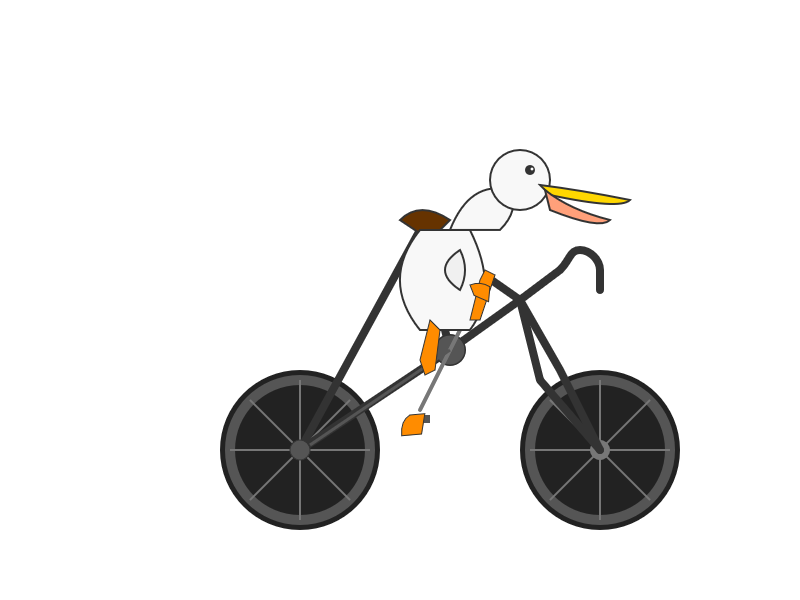
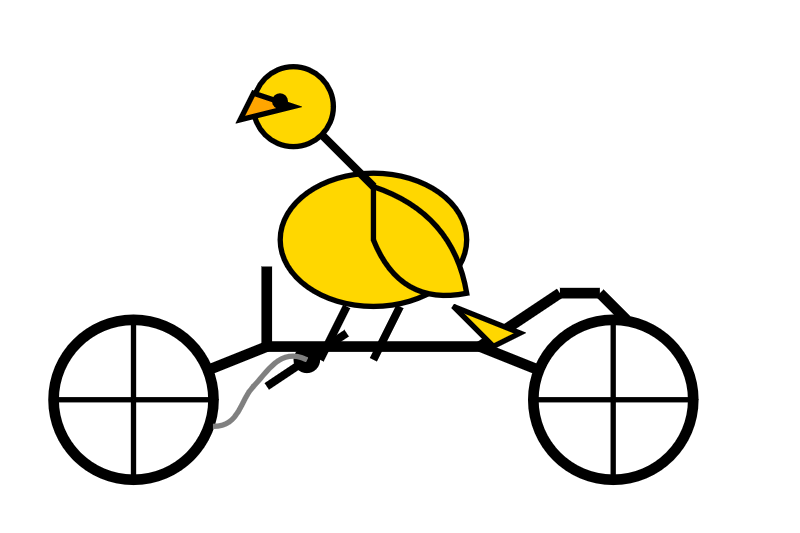
gemini-2.5-flash-lite-preview-06-17—2,070 output tokens, 0.0829 cents:
Transcribing audio from a Twitter Space
The Gemini team hosted a Twitter Space this morning to discuss the new models, with Logan Kilpatrick, Tulsee Doshi, Melvin Johnson, Anca Dragan and Zachary Gleicher. I grabbed a copy of the audio using yt-dlp, shrunk it down a bit with ffmpeg (here’s the resulting 2.5_smaller.m4a) and then tried using the new models to generate a transcript:
llm --at gemini-2.5_smaller.m4a audio/mpeg \
-m gemini/gemini-2.5-flash \
'Full transcript with timestamps' \
--schema-multi 'timestamp:mm:ss,speaker:best guess at name,text'
I got good results from 2.5 Pro (74,073 input, 8,856 output = 18.1151 cents, 147.5 seconds) and from 2.5 Flash (74,073 input audio, 10,477 output = 10.026 cents, 72.6 seconds), but the new Flash Lite model got stuck in a loop (65,517 output tokens = 6.3241 cents, 231.9 seconds) part way into the transcript:
... But this model is so cool because it just sort of goes on this rant, this hilarious rant about how the toaster is the pinnacle of the breakfast civilization, and then it makes all these jokes about the toaster. Um, like, what did the cows bring to you? Nothing. And then, um, and then, uh, and then, uh, and then, uh, and then, uh, and then, uh, and then, uh, and then, uh, and then, uh, and then, uh, and then, uh, and then, uh, and then, uh, and then, uh, and then, uh, and then, uh, and then, uh, and then, uh, and then, uh, and then, uh, and then, uh, and then, uh, and then, uh, and then, uh, and then, uh, and then, uh, and then, uh, and then, uh, and then, uh, and then, uh, and then, uh, and then, uh, and then, uh, and then, uh, and then, uh, and then, uh...(continues until it runs out of output tokens)
I had Claude 4 Sonnet vibe code me a quick tool for turning that JSON into Markdown, here’s the Markdown conversion of the Gemini 2.5 Flash transcript.
A spot-check of the timestamps seems to confirm that they show up in the right place, and the speaker name guesses look mostly correct as well.
Pricing for 2.5 Flash has changed
There have been some changes to Gemini pricing.
The 2.5 Flash and 2.5 Flash-Lite Preview models both charge different prices for text v.s. audio input tokens.
- $0.30/million text and $1/million audio for 2.5 Flash.
- $0.10/million text and $0.50/million audio for 2.5 Flash Lite Preview.
I think this mean I can’t trust the raw output token counts for the models and need to look at the [{"modality": "TEXT", "tokenCount": 5}, {"modality": "AUDIO", "tokenCount": 74068}] breakdown instead, which is frustrating.
I wish they’d kept the same price for both type of tokens and used a multiple when counting audio tokens, but presumably that would have broken the overall token limit numbers.
Gemini 2.5 Flash has very different pricing from the Gemini 2.5 Flash Preview model. That preview charged different rates for thinking v.s. non-thinking mode.
2.5 Flash Preview: $0.15/million input text/image/video, $1/million audio input, $0.60/million output in non-thinking mode, $3.50/million output in thinking mode.
The new 2.5 Flash is simpler: $0.30/million input text/image/video (twice as much), $1/million audio input (the same), $2.50/million output (more than non-thinking mode but less than thinking mode).
In the Twitter Space they mentioned that the difference between thinking and non-thinking mode for 2.5 Flash Preview had caused a lot of confusion, and the new price should still work out cheaper for thinking-mode uses. Using that model in non-thinking mode was always a bit odd, and hopefully the new 2.5 Flash Lite can fit those cases better (though it’s actually also a “thinking” model.)
I’ve updated my llm-prices.com site with the prices of the new models.
More recent articles
- Mr. Chatterbox is a (weak) Victorian-era ethically trained model you can run on your own computer - 30th March 2026
- Vibe coding SwiftUI apps is a lot of fun - 27th March 2026
- Experimenting with Starlette 1.0 with Claude skills - 22nd March 2026