23rd July 2025 - Link Blog
TimeScope: How Long Can Your Video Large Multimodal Model Go? (via) New open source benchmark for evaluating vision LLMs on how well they handle long videos:
TimeScope probes the limits of long-video capabilities by inserting several short (~5-10 second) video clips---our "needles"---into base videos ranging from 1 minute to 8 hours. With three distinct task types, it evaluates not just retrieval but synthesis, localization, and fine-grained motion analysis, providing a more holistic view of temporal comprehension.
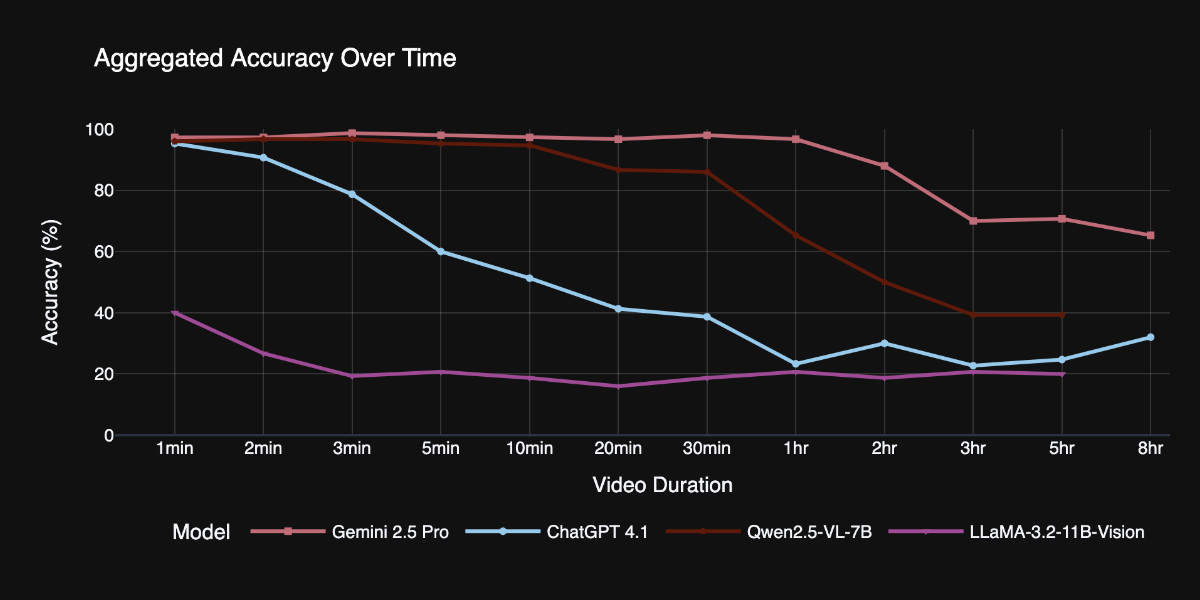
Videos can be fed into image-accepting models by converting them into thousands of images of frames (a trick I've tried myself), so they were able to run the benchmark against models that included GPT 4.1, Qwen2.5-VL-7B and Llama-3.2 11B in addition to video supporting models like Gemini 2.5 Pro.
Two discoveries from the benchmark that stood out to me:
Model size isn't everything. Qwen 2.5-VL 3B and 7B, as well as InternVL 2.5 models at 2B, 4B, and 8B parameters, exhibit nearly indistinguishable long-video curves to their smaller counterparts. All of them plateau at roughly the same context length, showing that simply scaling parameters does not automatically grant a longer temporal horizon.
Gemini 2.5-Pro is in a league of its own. It is the only model that maintains strong accuracy on videos longer than one hour.
You can explore the benchmark dataset on Hugging Face, which includes prompts like this one:
Answer the question based on the given video. Only give me the answer and do not output any other words.
Question: What does the golden retriever do after getting out of the box?A: lies on the ground B: kisses the man C: eats the food D: follows the baby E: plays with the ball F: gets back into the box
Recent articles
- OpenAI’s accidental cyberattack against Hugging Face is science fiction that happened - 22nd July 2026
- A Fireside Chat with Cat and Thariq from the Claude Code team - 21st July 2026
- Kimi K3, and what we can still learn from the pelican benchmark - 16th July 2026